- 更新时间:2018-07-05
前言
项目是好久之前做的,现在可能类似的demo也有很多了,已知忘记发博客和上传GitHub了,刚传上去,地址:https://github.com/roguesir/DL-ML-project/tree/master/Expression-Recognition
结构设计
采用fer2013人脸表情数据集,使用裁剪和旋转变换进行数据增强,处理后的数据量达到105000张,大小为48x48的黑白图片。

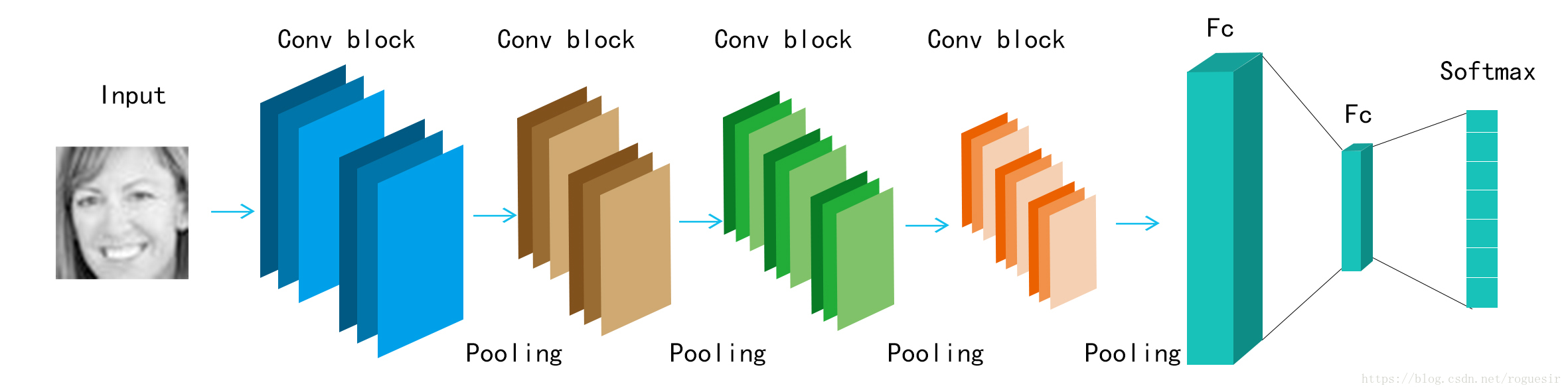
基本结构如下:
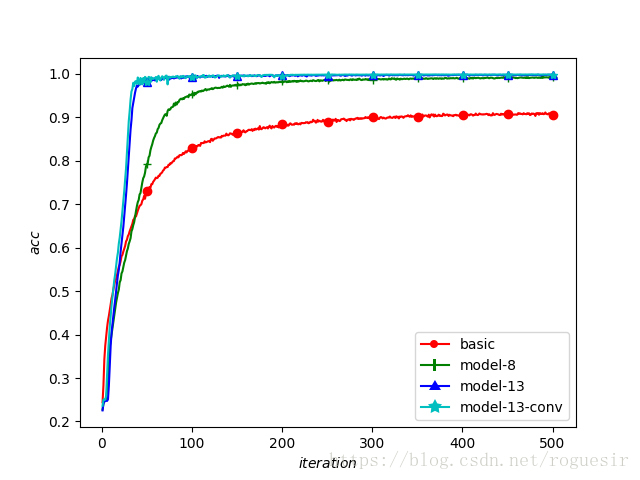
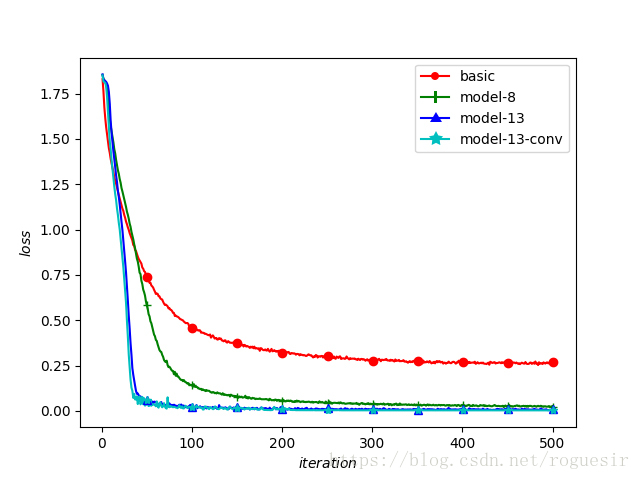
训练结果
| 模型 | 准确率(%) |
|---|---|
| model-basic | 90.11 |
| model-8 | 99.27 |
| model-13 | 99.80 |
| model-13-conv | 99.86 |
部分代码
# -*- coding: utf-8 -*-
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Flatten, Activation
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.preprocessing.image import load_img, img_to_array
from keras.utils import np_utils
import os
import numpy as np
def load_dataset(filedir):
"""
读取数据
:param filedir:
:return:
"""
image_data_list = []
label = []
train_image_list = os.listdir(filedir + '/train_data')
for img in train_image_list:
url = os.path.join(filedir + '/train_data/' + img)
image = load_img(url, grayscale=True, target_size=(48, 48))
#print(image.shape)
image_data_list.append(img_to_array(image))
label.append(img.split('.')[0].split("-")[1])
img_data = np.array(image_data_list)
img_data = img_data.astype('float32')
img_data /= 255
return img_data, label
def make_network():
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(48, 48, 1)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(7))
model.add(Activation('softmax'))
model.save('./data/model/model-basic.h5')
return model
if __name__ == '__main__':
train_loss = []
train_accuracy = []
train_x, train_y = load_dataset('data')
train_y = np_utils.to_categorical(train_y)
model = make_network()
model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=500, epochs=200, verbose=1)