作者:何翔
学院:计算机学院
学号:04191315
班级:软件1903
转载请标注本文链接: https://blog.csdn.net/HXBest/article/details/121981276
一、绪论
1.1 研究背景
面部表情识别 (Facial Expression Recognition )
在日常工作和生活中,人们情感的表达方式主要有:语言、声音、肢体行为(如手势)、以及面部表情等。在这些行为方式中,面部表情所携带的表达人类内心情感活动的信息最为丰富,据研究表明,人类的面部表情所携带的内心活动的信息在所有的上述的形式中比例最高,大约占比55%。
人类的面部表情变化可以传达出其内心的情绪变化,表情是人类内心世界的真实写照。上世纪70年代,美国著名心理学家保罗•艾克曼经过大量实验之后,将人类的基本表情定义为悲伤、害怕、厌恶、快乐、气愤和惊讶六种。同时,他们根据不同的面部表情类别建立了相应的表情图像数据库。随着研究的深入,中性表情也被研究学者加入基本面部表情中,组成了现今的人脸表情识别研究中的七种基础面部表情。

由于不同的面部表情,可以反映出在不同情景下人们的情绪变化以及心理变化,因此面部表情的识别对于研究人类行为和心理活动,具有十分重要的研究意义和实际应用价值。现如今,面部表情识别主要使用计算机对人类面部表情进行分析识别,从而分析认得情绪变化,这在人机交互、社交网络分析、远程医疗以及刑侦监测等方面都具有重要意义。
1.2 研究意义
在计算机视觉中,因为表情识别作为人机交互的一种桥梁,可以更好的帮助机器了解、识别人类的内心活动,从而更好的服务人类,因此对人脸表情识别进行深入研究具有十分重要的意义。而在研究人脸表情的过程中,如何有效地提取人脸表情特征,是人脸表情识别中最为关键的步骤。人脸表情识别从出现到现在已历经数十载,在过去的面部表情识别方法里还是主要依靠于人工设计的特征(比如边和纹理描述量)和机器学习技术(如主成分分析、线性判别分析或支持向量机)的结合。但是在无约束的环境中,人工设计对不同情况的特征提取是很困难的,同时容易受外来因素的干扰(光照、角度、复杂背景等),进而导致识别率下降。
随着科学技术的发展,传统的一些基于手工提取人脸表情图像特征的方法,因为需要研究人员具有比较丰富的经验,具有比较强的局限性,从而给人脸表情识别的研究造成了比较大的困难。随着深度学习的兴起,作为深度学习的经典代表的卷积神经网络,由于其具有自动提取人脸表情图像特征的优势,使得基于深度学习的人脸表情特征提取方法逐渐兴起,并逐步替代一些传统的人脸表情特征提取的方法。深度学习方法的主要优点在于它们可通过使用非常大的数据集进行训练学习从而获得表征这些数据的最佳功能。在深度学习中,使用卷积神经网络作为人脸表情特征提取的工具,可以更加完整的提取人脸表情特征,解决了一些传统手工方法存在的提取人脸表情特征不充足的问题。
将人脸表情识别算法按照特征提取方式进行分类,其主要分为两种:一是基于传统的计算机视觉的提取算法。该类方法主要依赖于研究人员手工设计来提取人脸表情特征;二是基于深度学习的算法。该方法使用卷积神经网络,自动地提取人脸表情特征。卷积神经网络对原始图像进行简单的预处理之后,可以直接输入到网络中,使用端到端的学习方法,即不经过传统的机器学习复杂的中间建模过程,如在识别中对数据进行标注、翻转处理等,直接一次性将数据标注好,同时学习特征与进行分类,这是深度学习方法与传统方法的重要区别。相比人工的选取与设计图像特征,卷积神经网络通过自动学习的方式,获得的样本数据的深度特征信息拥有更好的抗噪声能力、投影不变性、推广与泛化能力、抽象语义表示能力。
二、理论分析与研究
2.1 面部表情识别框架
面部表情识别通常可以划分为四个进程。包括图像获取,面部检测,图像预处理和表情分类。其中,面部检测,脸部特征提取和面部表情分类是面部表情识别的三个关键环节面部表情识别的基本框架如下图所示。
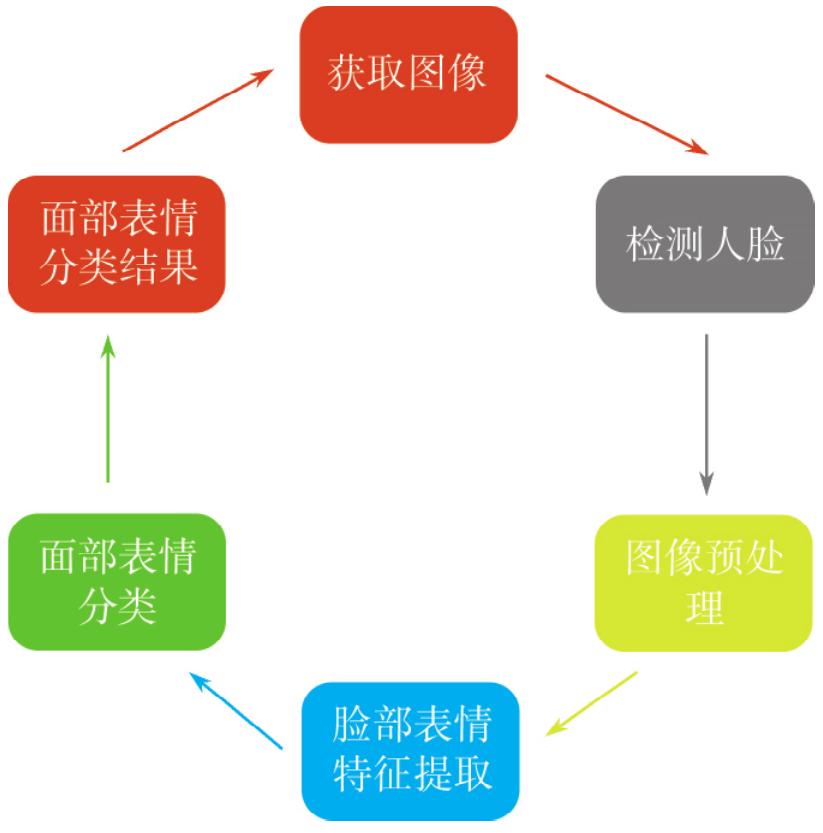
首先是获取图像并执行面部检测,然后提取仅具有面部的图像部分。所提取的面部表情在比例和灰度上不均匀,因此有必要对面部特征区域进行分割和归一化,其中执行归一化主要是对面部光照和位置进行统一处理,将图像统一重塑为标准大小,如 48×48 像素的图片,即图像预处理。然后对脸部图像提取面部表情特征值,并进行分类。采用卷积神经网络(CNN)来完成特征提取和分类的任务,因为 CNN 是模仿人脑工作并建立卷积神经网络结构模型的著名模型,所以选择卷积神经网络作为构建模型体系结构的基础,最后不断训练,优化,最后达到较准确识别出面部表情的结果。
图像预处理
采用多普勒扩展法的几何归一化分为两个主要步骤:面部校正和面部修剪。
主要目的是将图像转化为统一大小。
具体步骤如下:
(1)找到特征点并对其进行标记,首先选取两眼和鼻子作为三个特征点并采用一个函数对其进行标记,这里选择的函数是[x,y]=ginput(3)。这里重要的一点是获得特征点的坐标值,可以用鼠标进行调整。
(2)两眼的坐标值可以看作参考点,将两眼之间的距离设置为 d,找到两眼间的中点并标记为 O,然后根据参考点对图像进行旋转,这步操作是为了保证将人脸图像调到一致。
(3)接下来以选定的 O 为基准,分别向左右两个方向各剪切距离为 d 的区域,在垂直方向剪切 0.5d 和 1.5d 的区域,这样就可以根据面部特征点和几何模型对特征区域进行确定,如下图所示:
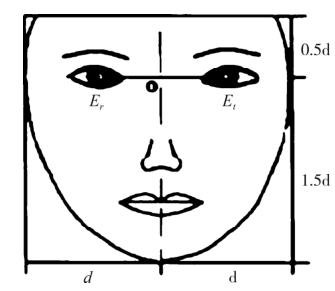
(4)为了更好的对表情进行提取,可将表情的子区域图像裁剪成统一的 48×48 尺寸。
2.2 基于 CNN 的人脸面部表情识别算法
卷积神经网络(CNN)是一种前馈神经网络,它包括卷积计算并具有较深的结构,因此是深度学习的代表性算法之一。随着科技的不断进步,人们在研究人脑组织时受启发创立了神经网络。神经网络由很多相互联系的神经元组成,并且可以在不同的神经元之间通过调整传递彼此之间联系的权重系数 x 来增强或抑制信号。标准卷积神经网络通常由输入层、卷积层、池化层、全连接层和输出层组成,如下图所示:
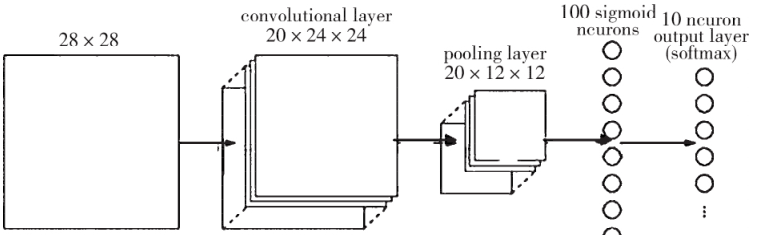
上图中第一层为输入层,大小为 28×28,然后通过 20×24×24 的卷积层,得到的结果再输入池化层中,最后再通过图中第四层既全连接层,直到最后输出。
下图为CNN常见的网络模型。其中包括 4 个卷积层,3 个池化层,池化层的大小为 3×3,最终再通过两个全连接层到达输出层。网络模型中的输入层一般是一个矩阵,卷积层,池化层和全连接层可以当作隐藏层,这些层通常具有不同的计算方法,需要学习权重以找到最佳值。

从上述中可知,标准卷积神经网络除了输入和输出外,还主要具有三种类型:池化层,全连接层和卷积层。这三个层次是卷积神经网络的核心部分。
2.2.1 卷积层
卷积层是卷积神经网络的第一层,由几个卷积单元组成。每个卷积单元的参数可以通过反向传播算法进行优化,其目的是提取输入的各种特征,但是卷积层的第一层只能提取低级特征,例如边、线和角。更多层的可以提取更高级的特征,利用卷积层对人脸面部图像进行特征提取。一般卷积层结构如下图所示,卷积层可以包含多个卷积面,并且每个卷积面都与一个卷积核相关联。
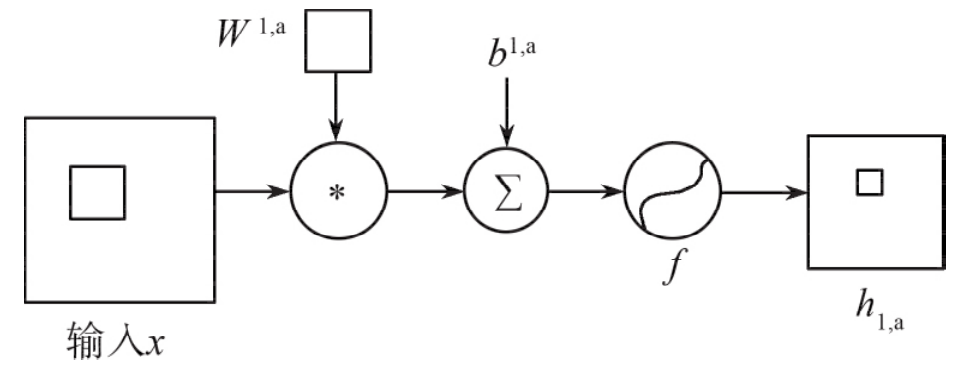
由上图可知,每次执行卷积层计算时,都会生成与之相关的多个权重参数,这些权重参数的数量与卷积层的数量相关,即与卷积层所用的函数有直接的关系。
2.2.2 池化层
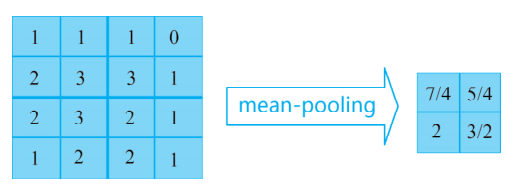
在卷积神经网络中第二个隐藏层便是池化层,在卷积神经网络中,池化层通常会在卷积层之间,由此对于缩小参数矩阵的尺寸有很大帮助,也可以大幅减少全连接层中的参数数量。此外池化层在加快计算速度和防止过拟合方面也有很大的作用。在识别图像的过程中,有时会遇到较大的图像,此时希望减少训练参数的数量,这时需要引入池化层。池化的唯一目的是减小图像空间的大小。常用的有 mean-pooling 和max-pooling。mean-pooling 即对一小块区域取平均值,假设 pooling 窗的大小是 2×2,那么就是在前面卷积层的输出的不重叠地进行 2×2 的取平均值降采样,就得到 mean-pooling 的值。不重叠的 4 个 2×2 区域分别 mean-pooling 如下图所示。
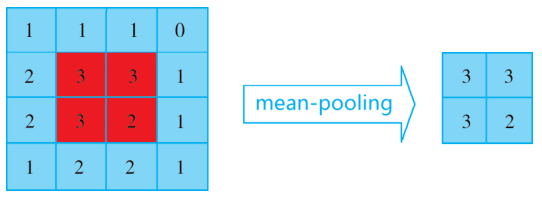
max-pooling 即对一小块区域取最大值,假设 pooling 的窗大小是 2×2,就是在前面卷积层的输出的不重叠地进行 2×2 的取最大值降采样,就得到 max-pooling 的值。不重叠的 4 个 2×2 区域分别max-pooling 如下图所示:
2.2.3 全连接层
卷积神经网络中的最后一个隐藏层是全连接层。该层的角色与之前的隐藏层完全不同。卷积层和池化层的功能均用于面部图像的特征提取,而全连接层的主要功能就是对图像的特征矩阵进行分类。根据不同的状况,它可以是一层或多层。
通过该层的图片可以高度浓缩为一个数。由此全连接层的输出就是高度提纯的特征了,便于移交给最后的分类器或者回归。
2.2.4 网络的训练
神经网络通过自学习的方式可以获得高度抽象的,手工特征无法达到的特征,在计算机视觉领域已经取得了革命性的突破。被广泛的应用于生活中的各方面。而要想让神经网络智能化,必须对它进行训练,在训练过程中一个重要的算法就是反向传播算法。反向传播算法主要是不断调整网络的权重和阈值,以得到最小化网络的平方误差之和,然后可以输出想要的结果。
2.2.5 CNN模型的算法评价
卷积神经网络由于强大的特征学习能力被应用于面部表情识别中,从而极大地提高了面部表情特征提取的效率。与此同时,卷积神经网络相比于传统的面部表情识别方法在数据的预处理和数据格式上得到了很大程度的简化。例如,卷积神经网络不需要输入归一化和格式化的数据。基于以上优点,卷积神经网络在人类面部表情识别这一领域中的表现要远远优于其他传统算法。
2.3 基于 VGG 的人脸面部表情识别算法
随着深度学习算法的不断发展,众多卷积神经网络算法已经被应用到机器视觉领域中。尽管卷积神经网络极大地提高了面部表情特征提取的效率,但是,基于卷积神经网络的算法仍存在两个较为典型的问题:
(1)忽略图像的二维特性。
(2)常规神经网络提取的表情特征鲁棒性较差。
因此,我们需要寻找或设计一种对人类面部表情的识别更加优化并准确的深度卷积神经网络模型。
2.3.1 VGG模型原理
VGG模型的提出
VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,网络名称VGGNet取自该小组名缩写。VGGNet是首批把图像分类的错误率降低到10%以内模型,同时该网络所采用的3\times33×3卷积核的思想是后来许多模型的基础,该模型发表在2015年国际学习表征会议(International Conference On Learning Representations, ICLR)后至今被引用的次数已经超过1万4千余次。
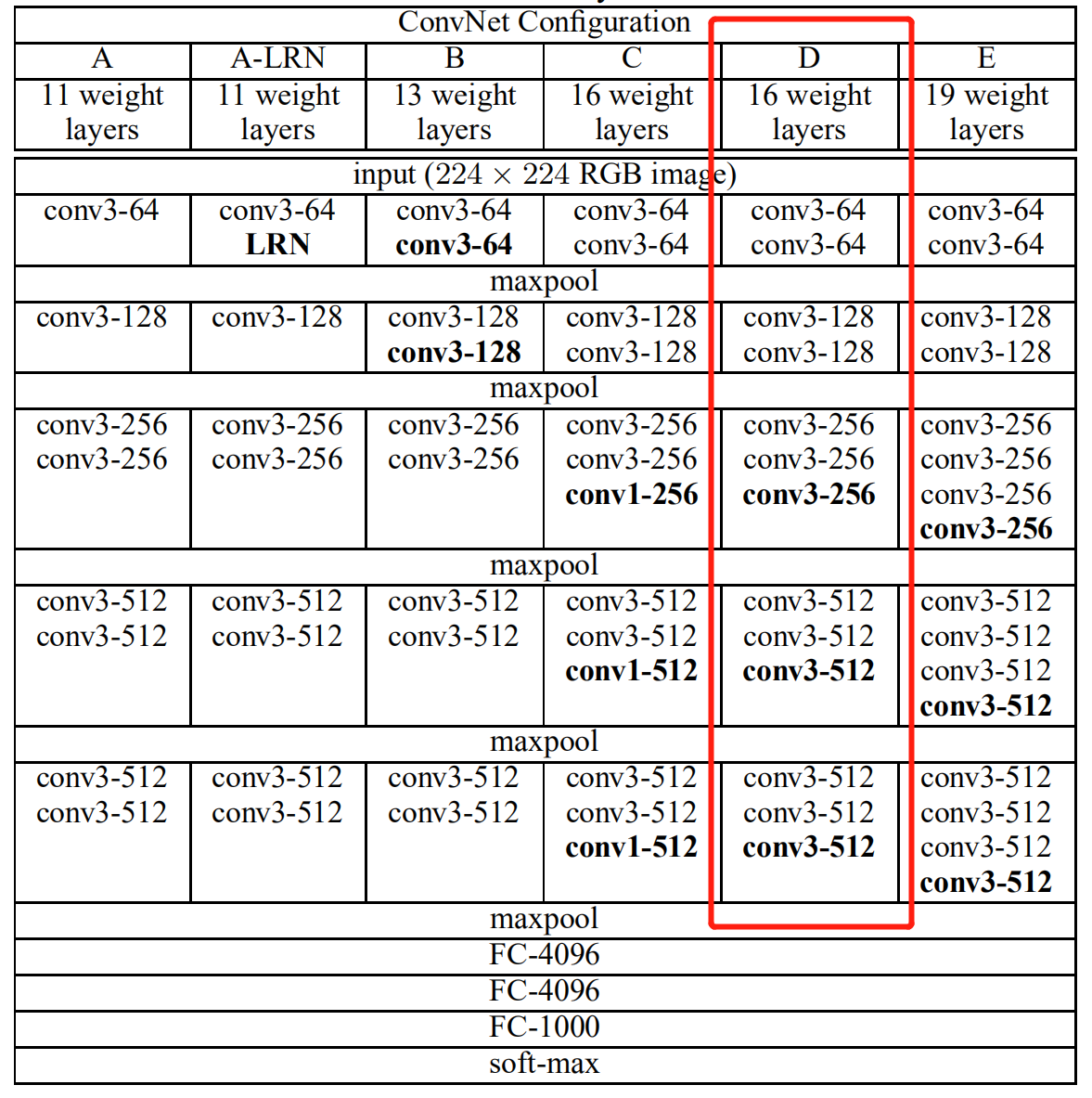
在原论文中的VGGNet包含了6个版本的演进,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数(VGG11-LRN表示在第一层中采用了LRN的VGG11,VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为 1\times11×1 ,相应的VGG16-3表示卷积核尺寸为 3\times33×3 )。下面主要以的VGG16-3为例。
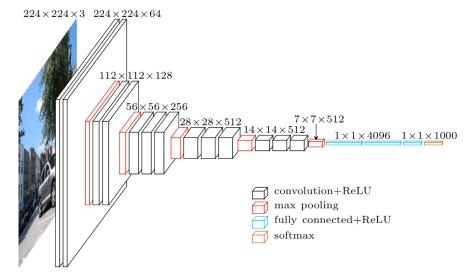
上图中的VGG16体现了VGGNet的核心思路,使用 3\times33×3 的卷积组合代替大尺寸的卷积(2个 3\times33×3 卷积即可与 5\times55×5 卷积拥有相同的感受视野)。
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。那么如果在我感受野相同的条件下,我让中间层数更多,那么能提取到的特征就越丰富,效果就会更好。
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为 3\times33×3 的卷积层后接上一个步幅为2、窗口形状为 2\times22×2 的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。
2.3.2 VGG模型的优点
(1)小卷积核: 将卷积核全部替换为3x3(极少用了1x1),作用就是减少参数,减小计算量。此外采用了更小的卷积核我们就可以使网络的层数加深,就可以加入更多的激活函数,更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,更多的卷积核的使用可使决策函数更加具有辨别能力。其实最重要的还是多个小卷积堆叠在分类精度上比单个大卷积要好。
(2)小池化核: 相比AlexNet的3x3的池化核,VGG全部为2x2的池化核。
(3)层数更深: 从作者给出的6个试验中我们也可以看到,最后两个实验的的层数最深,效果也是最好。
(4)卷积核堆叠的感受野: 作者在VGGnet的试验中只使用了两中卷积核大小:1*1,3*3。并且作者也提出了一种想法:两个3*3的卷积堆叠在一起获得的感受野相当于一个5*5卷积;3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。
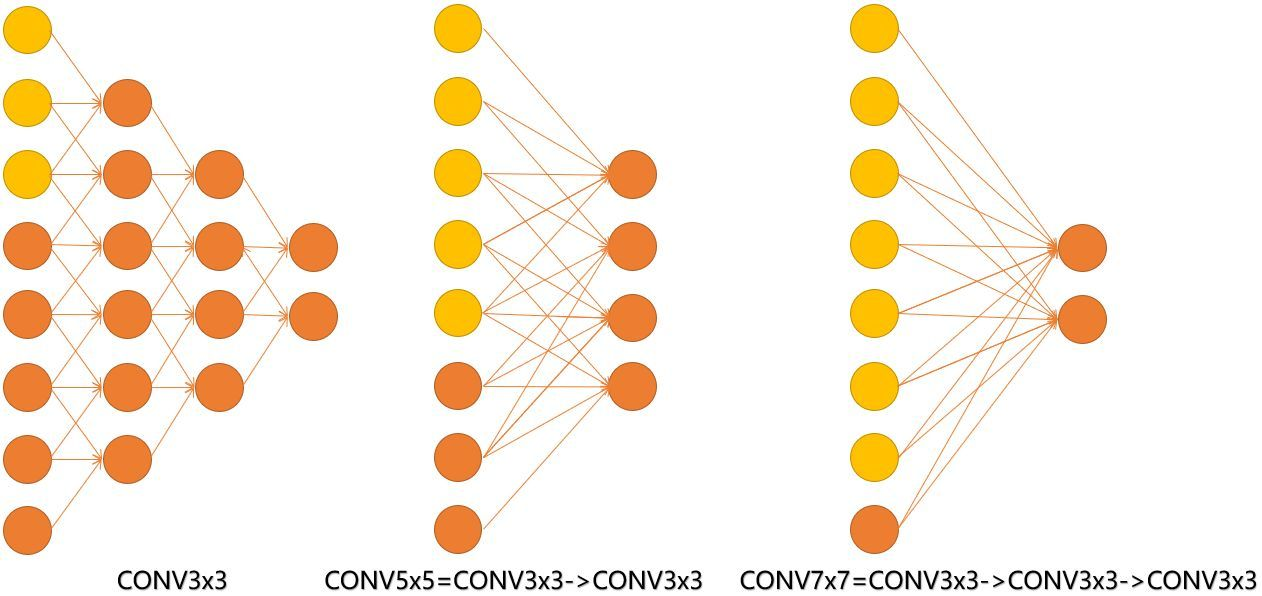
- input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
- input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
由上图可知,输入的8个神经元可以想象为feature map的宽和高,conv3 、conv5 、conv7 、对应stride=1,pad=0 。从结果我们可以得出上面推断的结论。此外,倒着看网络,也就是 backprop 的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的 conv3x3 中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层 conv3x3 的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
(5)全连接转卷积:VGG另一个特点就是使用了全连接转全卷积,它把网络中原本的三个全连接层依次变为1个conv7x7,2个conv1x1,也就是三个卷积层。改变之后,整个网络由于没有了全连接层,网络中间的 feature map 不会固定,所以网络对任意大小的输入都可以处理。
2.3.3 VGG模型的算法评价
综上所述,VGG采用连续的小卷积核代替较大卷积核,以获取更大的网络深度。 例如,使用 2 个 3∗3 卷积核代替 5∗5 卷积核。这种方法使得在确保相同感知野的条件下,VGG 网络具有比一般的 CNN 更大的网络深度,提升了神经网络特征提取及分类的效果。
2.4 基于 ResNet 的人脸面部表情识别算法
2.4.1 ResNet模型原理
ResNet模型的提出
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
下图是ResNet34层模型的结构简图:

在ResNet网络中有如下几个亮点:
- 提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
- 使用Batch Normalization加速训练(丢弃dropout)
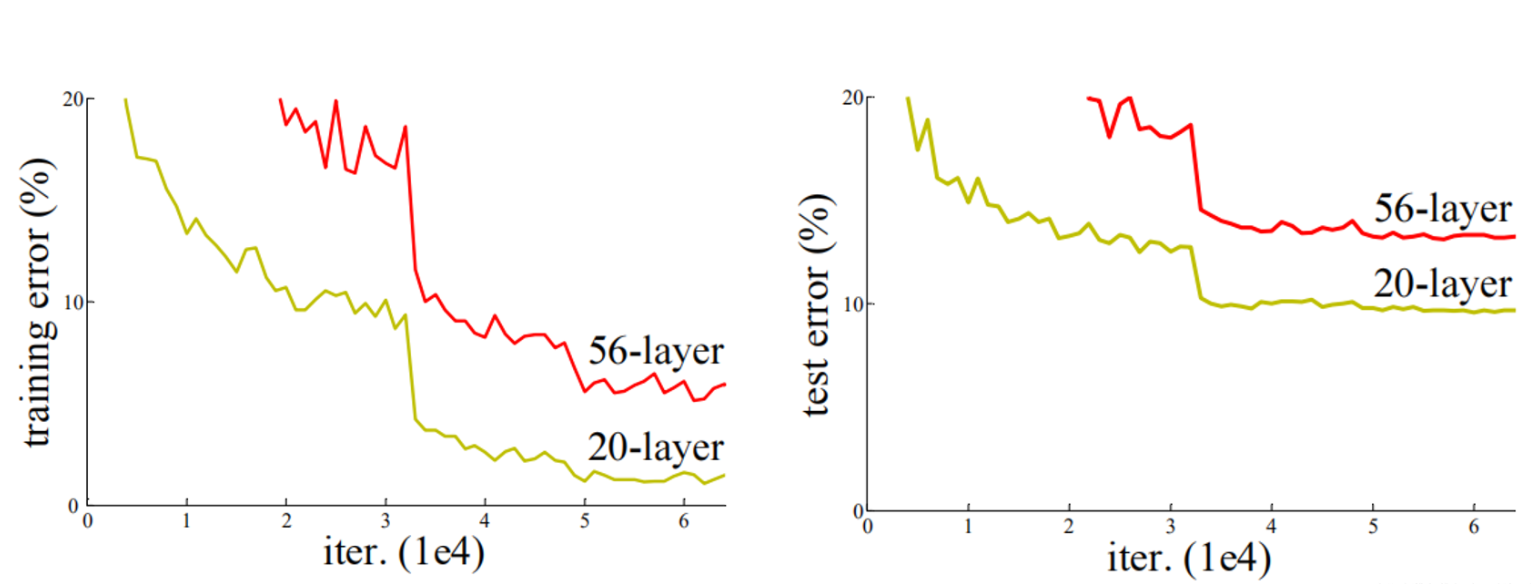
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。
- 梯度消失或梯度爆炸。
- 退化问题(degradation problem)。
在ResNet论文中说通过数据的预处理以及在网络中使用BN(Batch Normalization)层能够解决梯度消失或者梯度爆炸问题。但是对于退化问题(随着网络层数的加深,效果还会变差,如下图所示)并没有很好的解决办法。
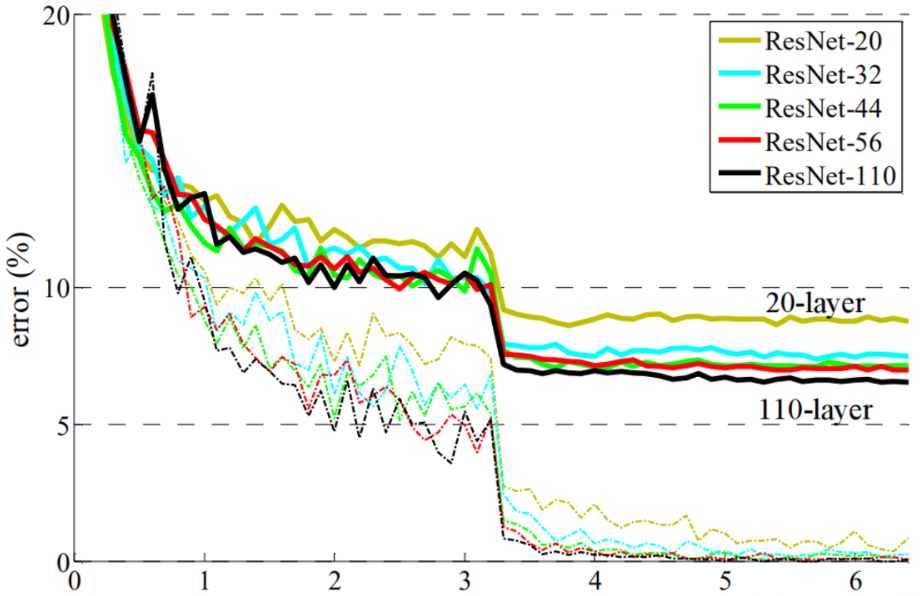
所以ResNet论文提出了residual结构(残差结构)来减轻退化问题。下图是使用residual结构的卷积网络,可以看到随着网络的不断加深,效果并没有变差,反而变的更好了。
2.4.2 残差结构(residual)
残差指的是什么?
其中ResNet提出了两种mapping:一种是identity mapping,指的就是下图中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+x
identity mapping
顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。
下图是论文中给出的两种残差结构。左边的残差结构是针对层数较少网络,例如ResNet18层和ResNet34层网络。右边是针对网络层数较多的网络,例如ResNet101,ResNet152等。为什么深层网络要使用右侧的残差结构呢。因为,右侧的残差结构能够减少网络参数与运算量。同样输入一个channel为256的特征矩阵,如果使用左侧的残差结构需要大约1170648个参数,但如果使用右侧的残差结构只需要69632个参数。明显搭建深层网络时,使用右侧的残差结构更合适。
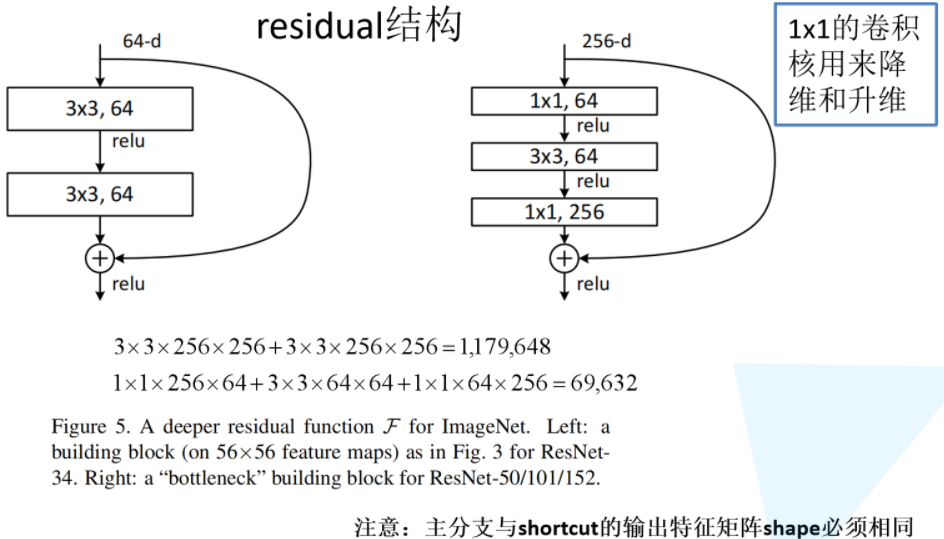
下面先对左侧的残差结构(针对ResNet18/34)进行一个分析。如下图所示,该残差结构的主分支是由两层3x3的卷积层组成,而残差结构右侧的连接线是shortcut分支也称捷径分支(注意为了让主分支上的输出矩阵能够与我们捷径分支上的输出矩阵进行相加,必须保证这两个输出特征矩阵有相同的shape)。如果刚刚仔细观察了ResNet34网络结构图,应该能够发现图中会有一些虚线的残差结构。在原论文中作者只是简单说了这些虚线残差结构有降维的作用,并在捷径分支上通过1x1的卷积核进行降维处理。而下图右侧给出了详细的虚线残差结构,注意下每个卷积层的步距stride,以及捷径分支上的卷积核的个数(与主分支上的卷积核个数相同)。
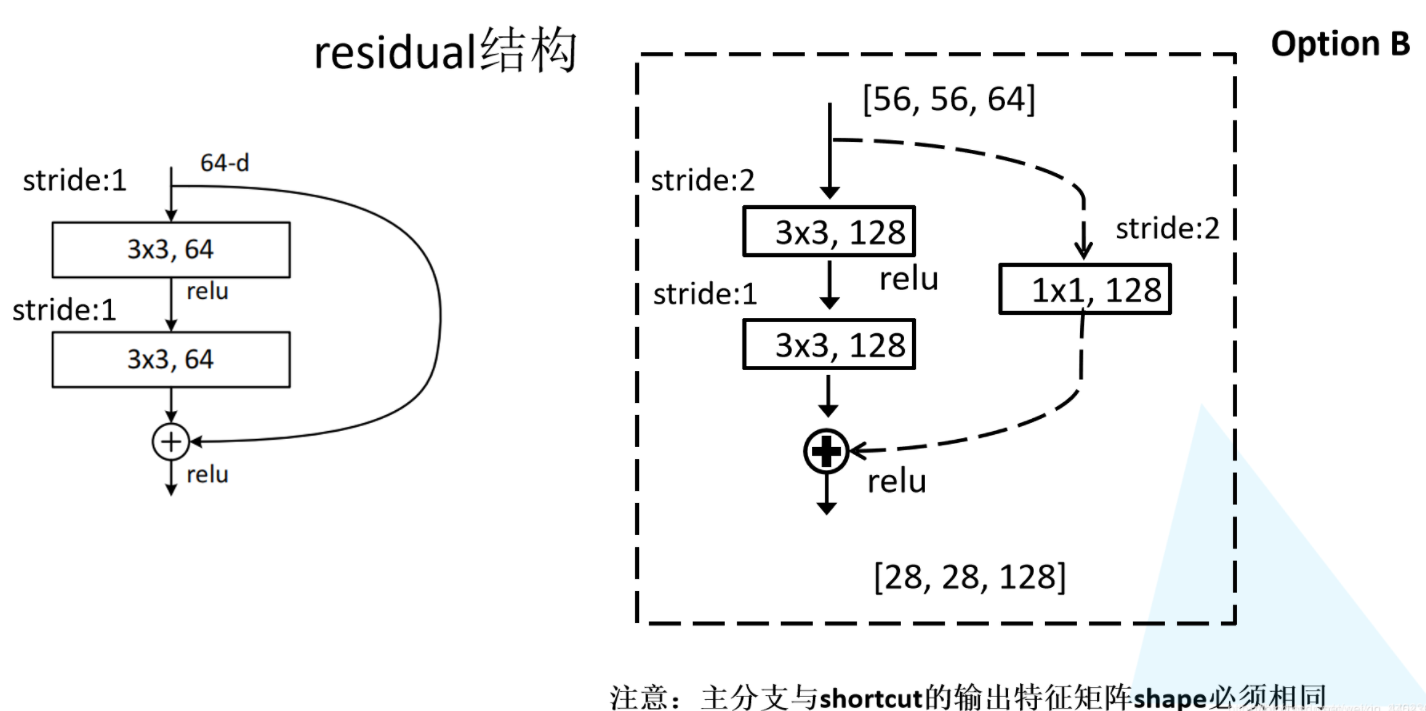
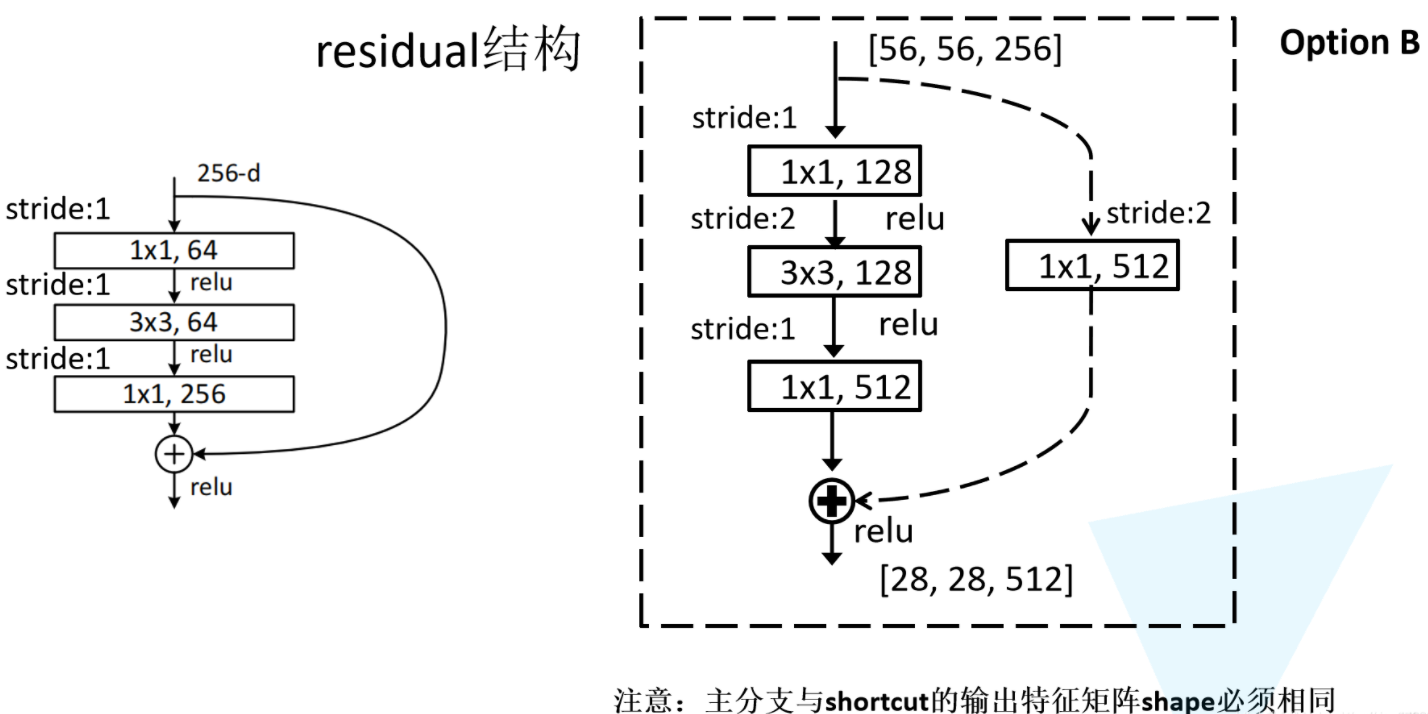
接着再来分析下针对ResNet50/101/152的残差结构,如下图所示。在该残差结构当中,主分支使用了三个卷积层,第一个是1x1的卷积层用来压缩channel维度,第二个是3x3的卷积层,第三个是1x1的卷积层用来还原channel维度(注意主分支上第一层卷积层和第二次卷积层所使用的卷积核个数是相同的,第三次是第一层的4倍)。该残差结构所对应的虚线残差结构如下图右侧所示,同样在捷径分支上有一层1x1的卷积层,它的卷积核个数与主分支上的第三层卷积层卷积核个数相同,注意每个卷积层的步距。
下面这幅图是原论文给出的不同深度的ResNet网络结构配置,注意表中的残差结构给出了主分支上卷积核的大小与卷积核个数,表中的xN表示将该残差结构重复N次。那到底哪些残差结构是虚线残差结构呢。
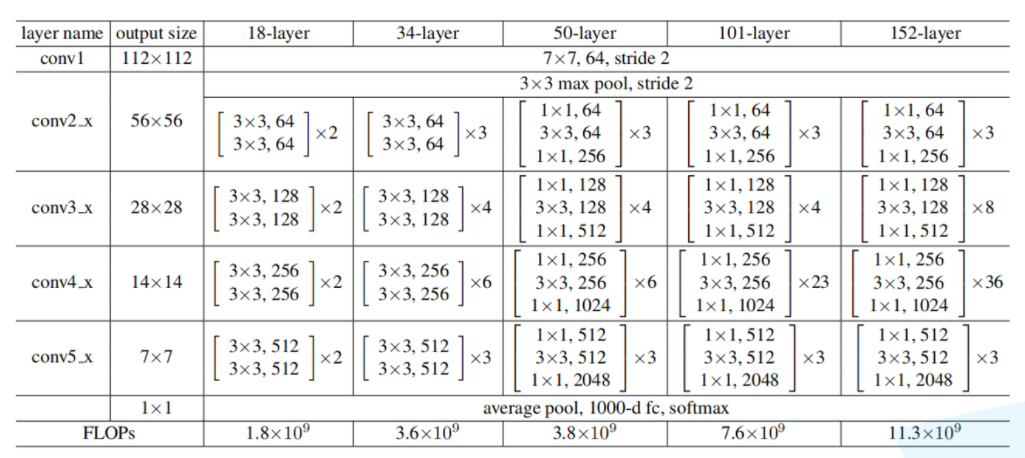
对于我们ResNet18/34/50/101/152,表中conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层残差结构都是虚线残差结构。因为这一系列残差结构的第一层都有调整输入特征矩阵shape的使命(将特征矩阵的高和宽缩减为原来的一半,将深度channel调整成下一层残差结构所需要的channel)。下面给出了简单标注了一些信息的ResNet34网络结构图。

对于ResNet50/101/152,其实在conv2_x所对应的一系列残差结构的第一层也是虚线残差结构。因为它需要调整输入特征矩阵的channel,根据表格可知通过3x3的max pool之后输出的特征矩阵shape应该是[56, 56, 64],但我们conv2_x所对应的一系列残差结构中的实线残差结构它们期望的输入特征矩阵shape是[56, 56, 256](因为这样才能保证输入输出特征矩阵shape相同,才能将捷径分支的输出与主分支的输出进行相加)。所以第一层残差结构需要将shape从[56, 56, 64] --> [56, 56, 256]。注意,这里只调整channel维度,高和宽不变(而conv3_x, conv4_x, conv5_x所对应的一系列残差结构的第一层虚线残差结构不仅要调整channel还要将高和宽缩减为原来的一半)。
2.4.3 ResNet模型的算法评价
ResNet已经被广泛运用于各种特征提取应用中,它的出现解决了网络层数到一定的深度后分类性能和准确率不能提高的问题,深度残差网络与传统卷积神经网络相比,在网络中引入残差模块,该模块的引入有效地缓解了网络模型训练时反向传播的梯度消失问题,进而解决了深层网络难以训练和性能退化的问题。
三、人脸面部表情识别项目设计
3.1 项目简介
本项目是基于卷积神经网络模型开展表情识别的研究,为了尽可能的提高最终表情识别的准确性,需要大量的样本图片训练,优化,所以采用了 FER2013 数据集用来训练、测试,此数据集由 35886 张人脸表情图片组成,其中,测试图 28708 张,公共验证图和私有验证图各 3589 张,所有图片中共有7种表情。在预处理时把图像归一化为 48×48 像素,训练的网络结构是基于 CNN 网络结构的优化改进后的一个开源的网络结构,下文中会具体介绍到,通过不断地改进优化,缩小损失率,最终能达到较准确的识别出人的面部表情的结果。
3.2 数据集准备
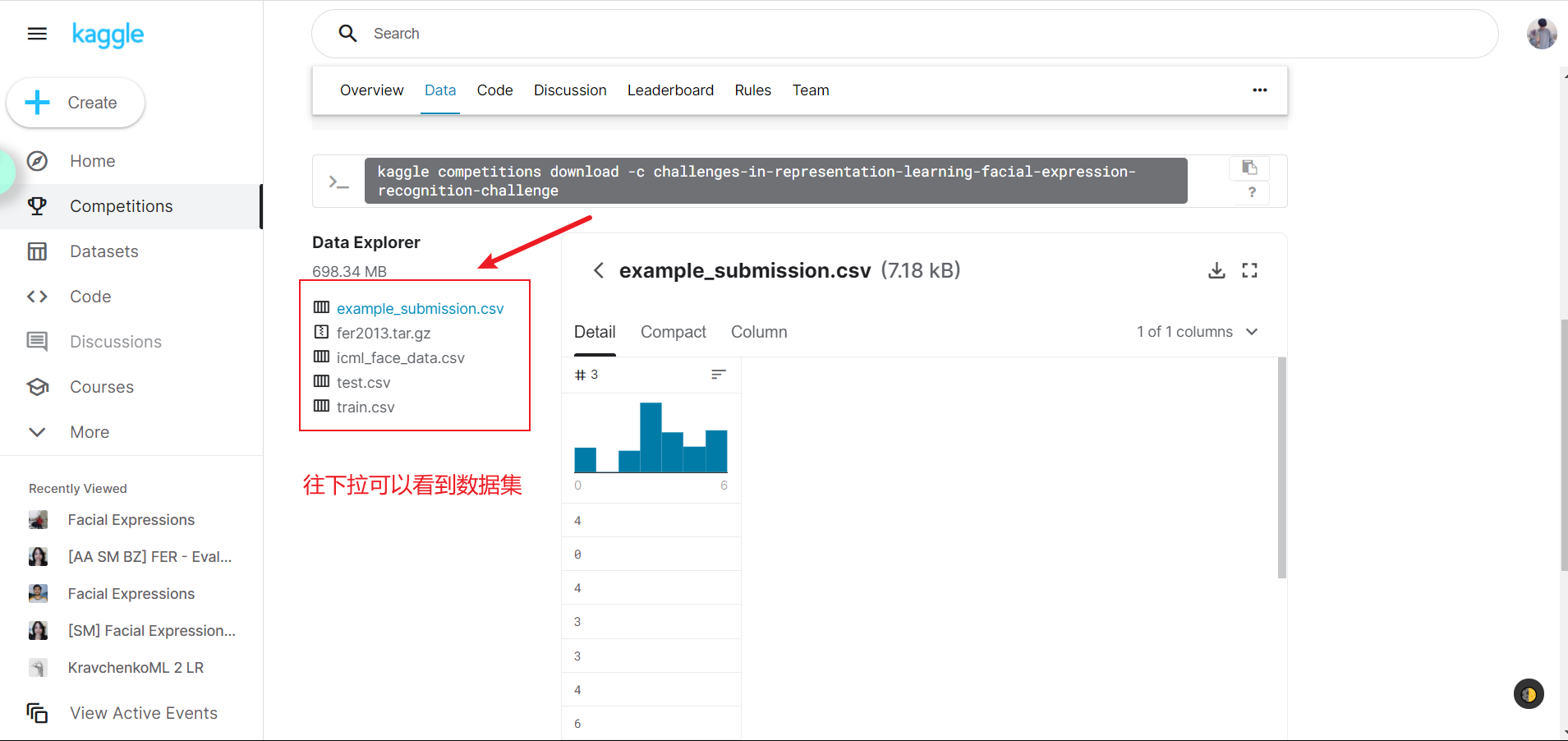
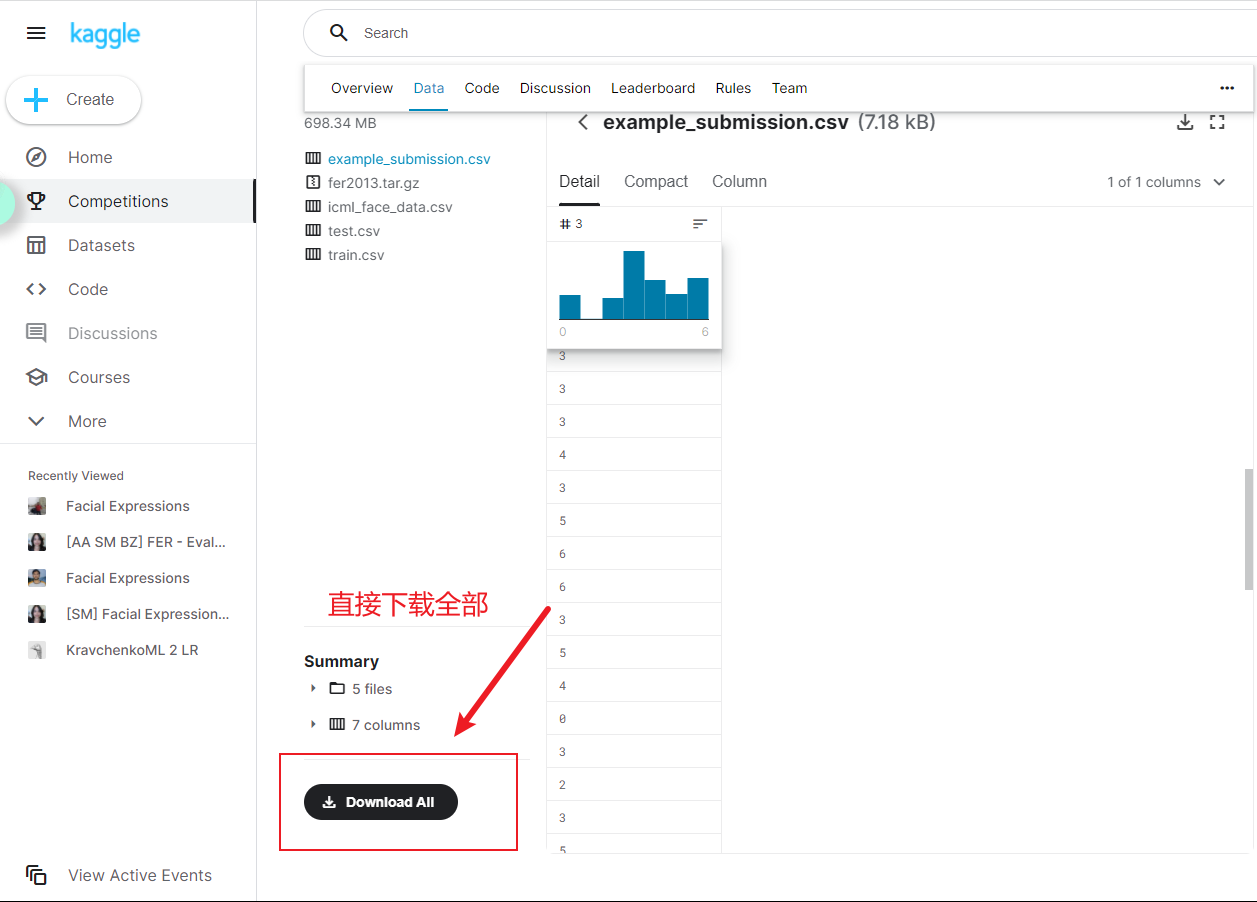
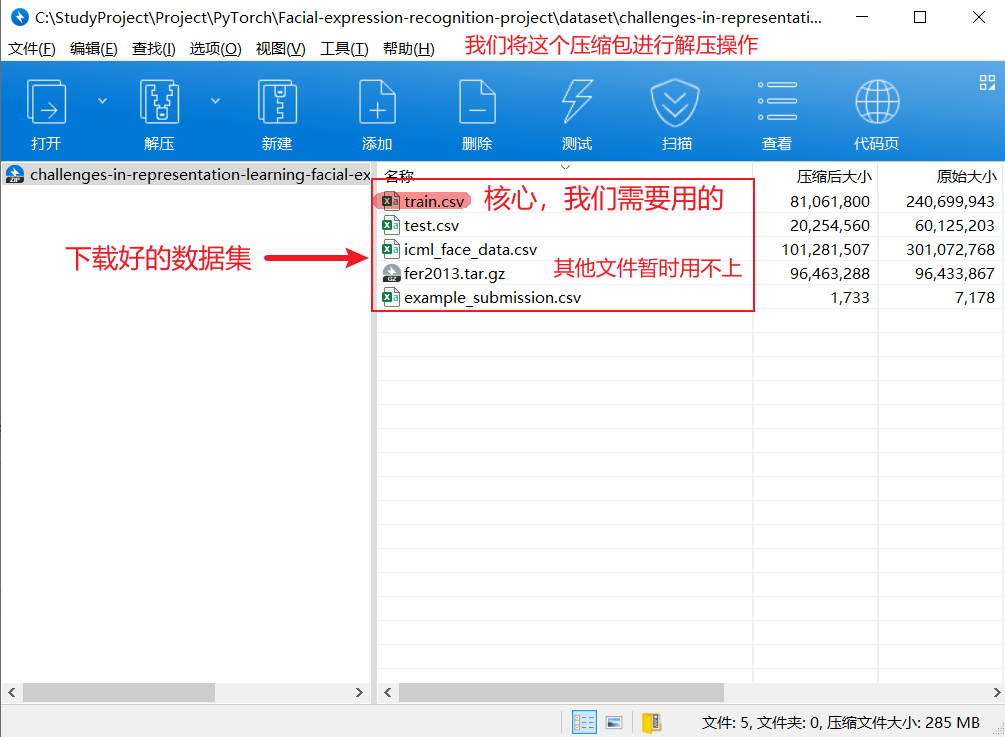
本项目采用了FER2013数据库,其数据集的下载地址如下:
https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data
FER2013数据集由28709张训练图,3589张公开测试图和3589张私有测试图组成。每一张图都是像素为48*48的灰度图。FER2013数据库中一共有7中表情:愤怒,厌恶,恐惧,开心,难过,惊讶和中性。该数据库是2013年Kaggle比赛的数据,由于这个数据库大多是从网络爬虫下载的,存在一定的误差性。这个数据库的人为准确率是65% 士 5%。
3.3 数据集介绍
给定的数据集train.csv,我们要使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情。在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过,(5)惊讶和(6)中立(即面无表情,无法归为前六类)。因此,项目实质上是一个7分类问题。

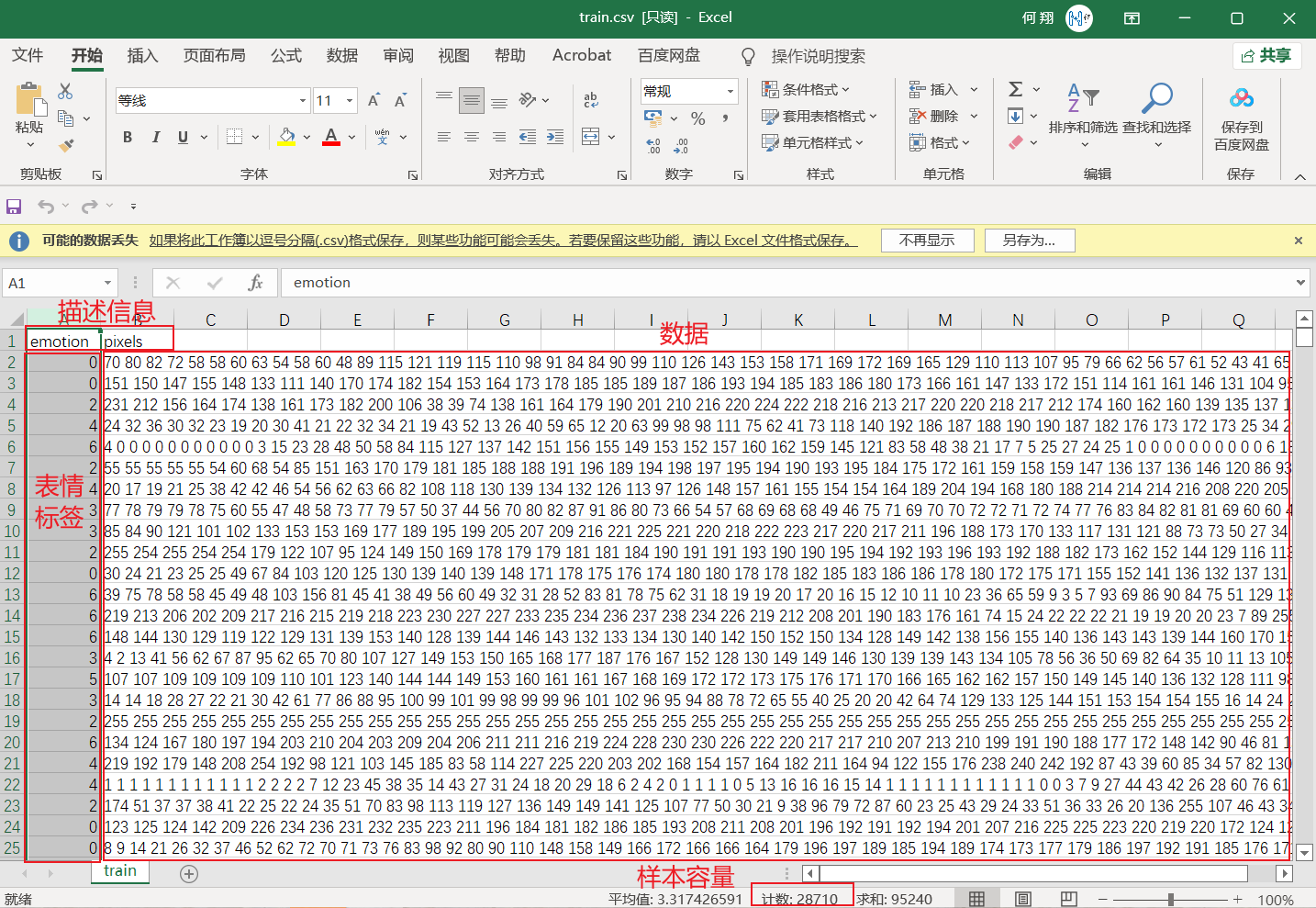
train.csv文件说明:
(1)CSV文件,大小为28710行X2305列;
(2)在28710行中,其中第一行为描述信息,即“emotion”和“pixels”两个单词,其余每行内含有一个样本信息,即共有28709个样本;
(3)在2305列中,其中第一列为该样本对应的emotion,取值范围为0到6。其余2304列为包含着每个样本大小为48X48人脸图片的像素值(2304=48X48),每个像素值取值范围在0到255之间;
3.4 数据集分离
在原文件中,emotion和pixels人脸像素数据是集中在一起的。为了方便操作,决定利用pandas库进行数据分离,即将所有emotion读出后,写入新创建的文件emotion.csv;将所有的像素数据读出后,写入新创建的文件pixels.csv。
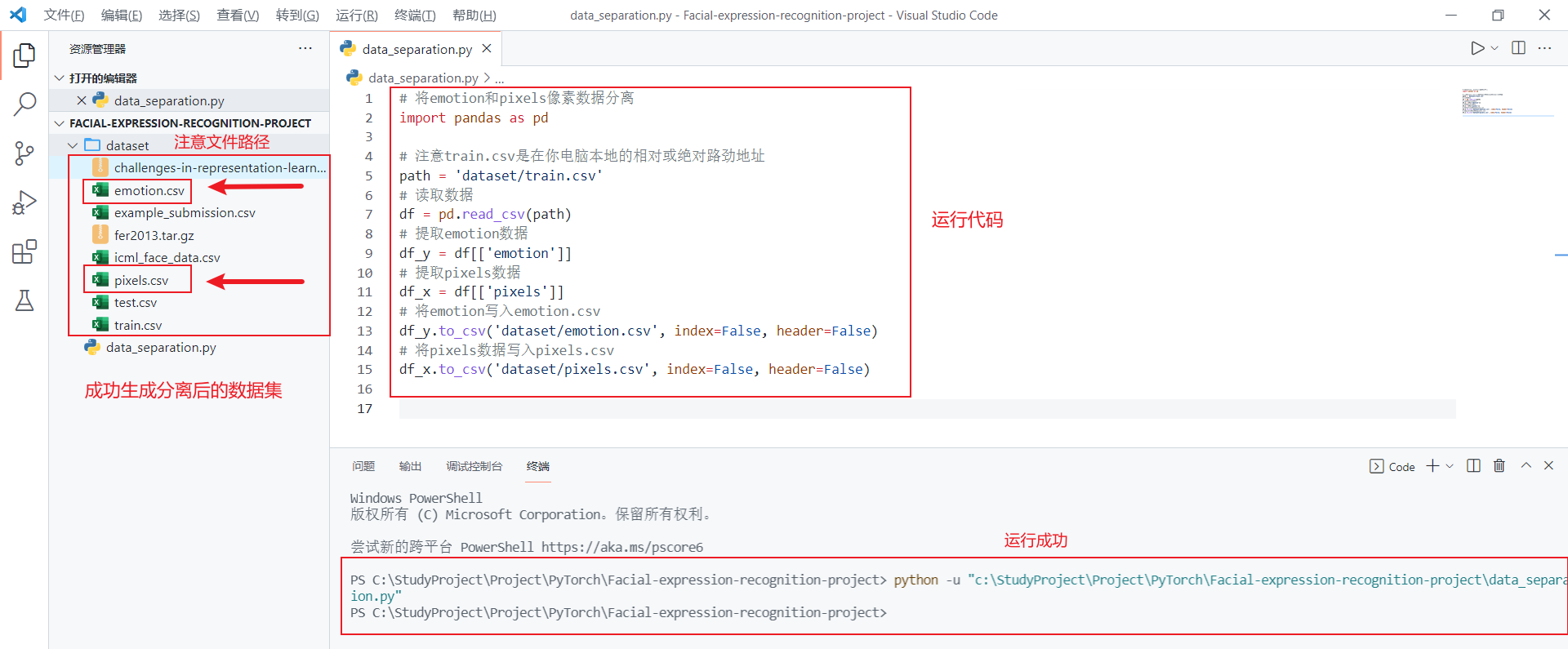
数据集分离的代码如下:
# 将emotion和pixels像素数据分离
import pandas as pd
# 注意修改train.csv为你电脑上文件所在的相对或绝对路劲地址。
path = 'dataset/train.csv'
# 读取数据
df = pd.read_csv(path)
# 提取emotion数据
df_y = df[['emotion']]
# 提取pixels数据
df_x = df[['pixels']]
# 将emotion写入emotion.csv
df_y.to_csv('dataset/emotion.csv', index=False, header=False)
# 将pixels数据写入pixels.csv
df_x.to_csv('dataset/pixels.csv', index=False, header=False)
以上代码执行完毕后,在dataset的文件夹下,就会生成两个新文件emotion.csv以及pixels.csv。在执行代码前,注意修改train.csv为你电脑上文件所在的相对或绝对路劲地址。
3.5 数据可视化
给定的数据集是csv格式的,考虑到图片分类问题的常规做法,决定先将其全部可视化,还原为图片文件再送进模型进行处理。
在python环境下,将csv中的像素数据还原为图片并保存下来,有很多库都能实现类似的功能,如pillow,opencv等。这里我采用的是用opencv来实现这一功能。
将数据分离后,人脸像素数据全部存储在pixels.csv文件中,其中每行数据就是一张人脸。按行读取数据,利用opencv将每行的2304个数据恢复为一张48X48的人脸图片,并保存为jpg格式。在保存这些图片时,将第一行数据恢复出的人脸命名为0.jpg,第二行的人脸命名为1.jpg…,以方便与label[0]、label[1]…一一对应。
数据可视化的代码如下;
import cv2
import numpy as np
# 指定存放图片的路径
path = 'face_images'
# 读取像素数据
data = np.loadtxt('dataset/pixels.csv')
# 按行取数据
for i in range(data.shape[0]):
face_array = data[i, :].reshape((48, 48)) # reshape
cv2.imwrite(path + '//' + '{}.jpg'.format(i), face_array) # 写图片
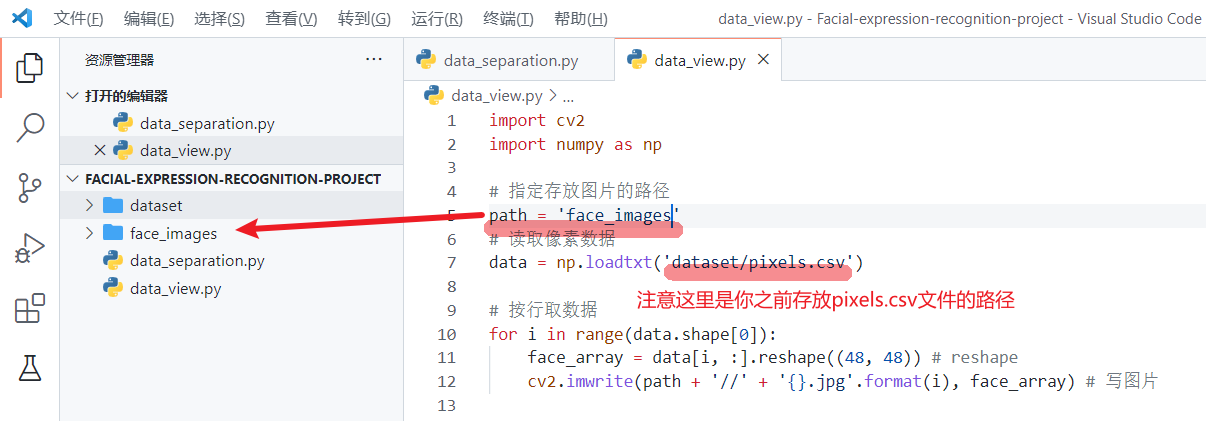
以上代码虽短,但涉及到大量数据的读取和大批图片的写入,因此占用的内存资源较多,且执行时间较长(视机器性能而定,一般要几分钟到十几分钟不等)。代码执行完毕,我们来到指定的图片存储路径,就能发现里面全部是写好的人脸图片。

粗略浏览一下这些人脸图片,就能发现这些图片数据来源较广,且并不纯净。就前60张图片而言,其中就包含了正面人脸,如1.jpg;侧面人脸,如18.jpg;倾斜人脸,如16.jpg;正面人头,如7.jpg;正面人上半身,如55.jpg;动漫人脸,如38.jpg;以及毫不相关的噪声,如59.jpg。放大图片后仔细观察,还会发现不少图片上还有水印。各种因素均给识别提出了严峻的挑战。
3.6 创建映射表
创建image图片名和对应emotion表情数据集的映射关系表。
首先,我们需要划分一下训练集和验证集。在项目中,共有28709张图片,取前24000张图片作为训练集,其他图片作为验证集。新建文件夹train_set和verify_set,将0.jpg到23999.jpg放进文件夹train_set,将其他图片放进文件夹verify_set。
在继承torch.utils.data.Dataset类定制自己的数据集时,由于在数据加载过程中需要同时加载出一个样本的数据及其对应的emotion,因此最好能建立一个image的图片名和对应emotion表情数据的关系映射表,其中记录着image的图片名和其emotion表情数据的映射关系。
这里需要和大家强调一下:大家在人脸可视化过程中,每张图片的命名不是都和emotion的存放顺序是一一对应的。在实际操作的过程中才发现,程序加载文件的机制是按照文件名首字母(或数字)来的,即加载次序是0,1,10,100…,而不是预想中的0,1,2,3…,因此加载出来的图片不能够和emotion[0],emotion[1],emotion[2],emotion[3]…一一对应,所以建立image-emotion映射关系表还是相当有必要的。
建立image-emotion映射表的基本思路就是:指定文件夹(train_set或verify_set),遍历该文件夹下的所有文件,如果该文件是.jpg格式的图片,就将其图片名写入一个列表,同时通过图片名索引出其emotion,将其emotion写入另一个列表。最后利用pandas库将这两个列表写入同一个csv文件。
image-emotion关系映射创建代码如下:
import os
import pandas as pd
def image_emotion_mapping(path):
# 读取emotion文件
df_emotion = pd.read_csv('dataset/emotion.csv', header = None)
# 查看该文件夹下所有文件
files_dir = os.listdir(path)
# 用于存放图片名
path_list = []
# 用于存放图片对应的emotion
emotion_list = []
# 遍历该文件夹下的所有文件
for file_dir in files_dir:
# 如果某文件是图片,则将其文件名以及对应的emotion取出,分别放入path_list和emotion_list这两个列表中
if os.path.splitext(file_dir)[1] == ".jpg":
path_list.append(file_dir)
index = int(os.path.splitext(file_dir)[0])
emotion_list.append(df_emotion.iat[index, 0])
# 将两个列表写进image_emotion.csv文件
path_s = pd.Series(path_list)
emotion_s = pd.Series(emotion_list)
df = pd.DataFrame()
df['path'] = path_s
df['emotion'] = emotion_s
df.to_csv(path+'\\image_emotion.csv', index=False, header=False)
def main():
# 指定文件夹路径
train_set_path = 'face_images/train_set'
verify_set_path = 'face_images/verify_set'
image_emotion_mapping(train_set_path)
image_emotion_mapping(verify_set_path)
if __name__ == "__main__":
main()
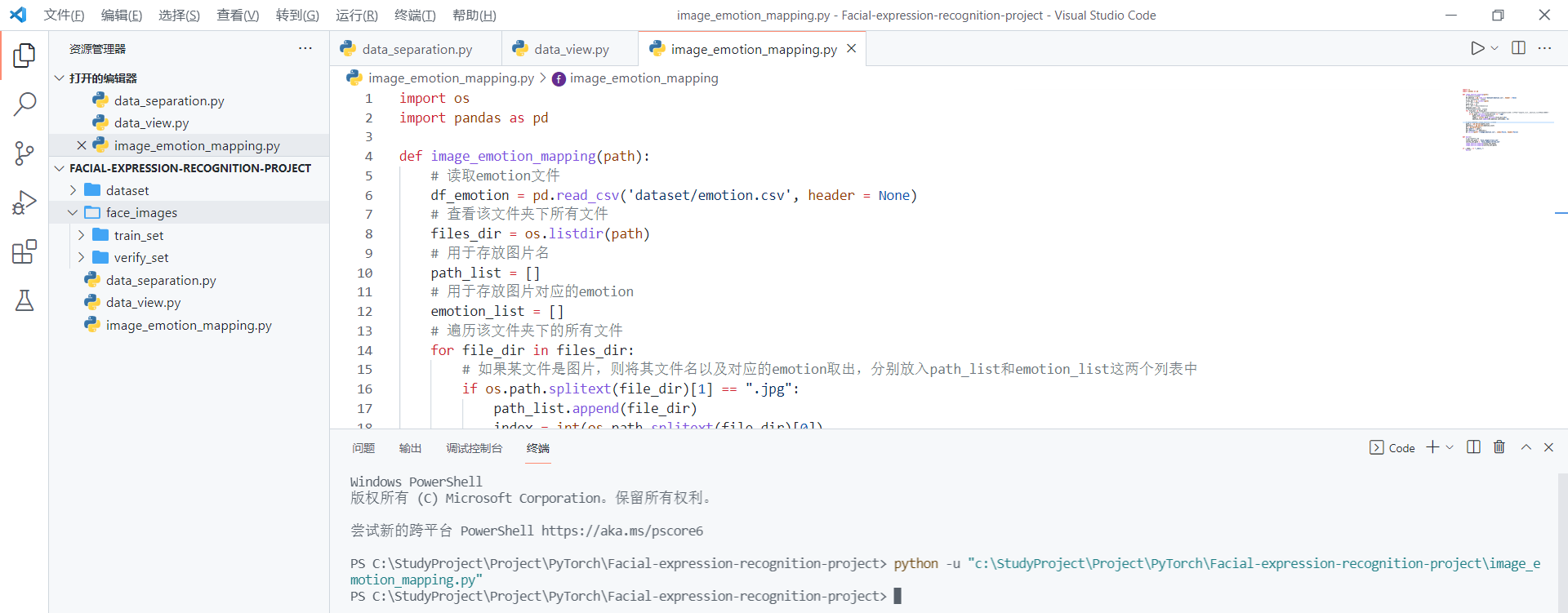
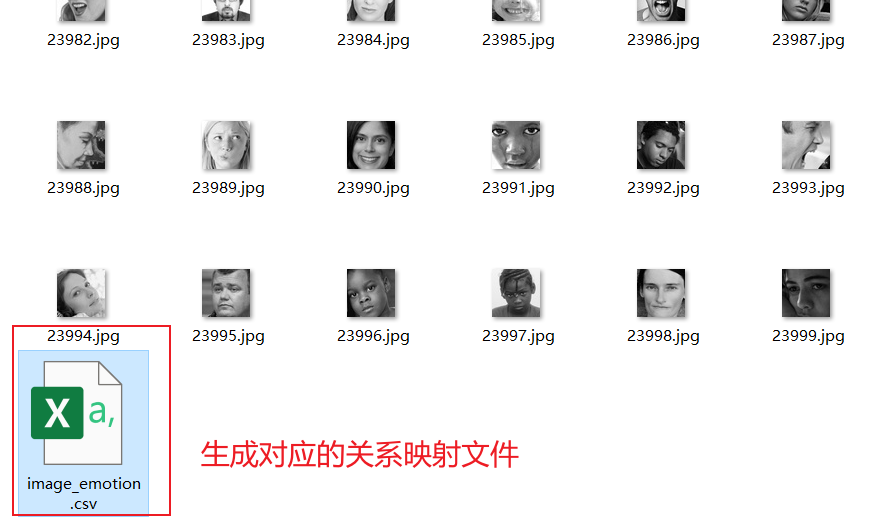
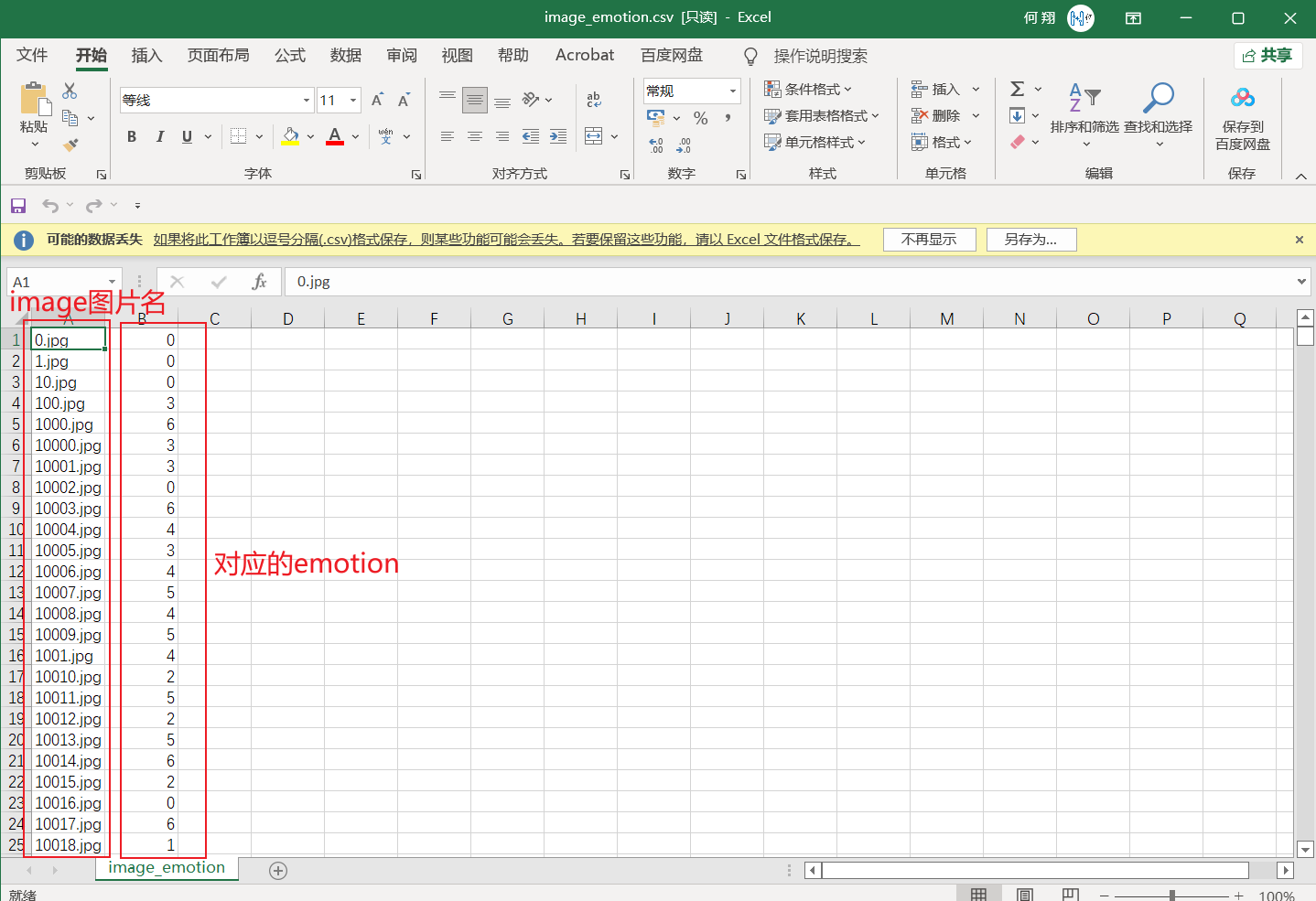
执行这段代码前,注意修改相关文件路径。代码执行完毕后,会在train_set和verify_set文件夹下各生成一个名为image-emotion.csv的关系映射表。
3.7 加载数据集
现在我们有了图片,但怎么才能把图片读取出来送给模型呢?一般在平常的时候,我们第一个想到的是将所有需要的数据聚成一堆一堆然后通过构建list去读取我们的数据:

假如我们编写了上述的图像加载数据集代码,在训练中我们就可以依靠get_training_data()这个函数来得到batch_size个数据,从而进行训练,乍看下去没什么问题,但是一旦我们的数据量超过1000:
- 将所有的图像数据直接加载到numpy数据中会占用大量的内存
- 由于需要对数据进行导入,每次训练的时候在数据读取阶段会占用大量的时间
- 只使用了单线程去读取,读取效率比较低下
- 拓展性很差,如果需要对数据进行一些预处理,只能采取一些不是特别优雅的做法
如果用opencv将所有图片读取出来,最简单粗暴的方法就是直接以numpy中array的数据格式直接送给模型。如果这样做的话,会一次性把所有图片全部读入内存,占用大量的内存空间,且只能使用单线程,效率不高,也不方便后续操作。
既然问题这么多,到底说回来,我们应该如何正确地加载数据集呢?
其实在pytorch中,有一个类(torch.utils.data.Dataset)是专门用来加载数据的,我们可以通过继承这个类来定制自己的数据集和加载方法。
Dataset类是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。其中父类中的两个私有成员函数必须被重载,否则将会触发错误提示:
-
def getitem(self, index):
-
def len(self):
其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据集索引的函数,例如通过dataset[i]可以得到数据集中的第i+1个数据。
#源码
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
#这个函数就是根据索引,迭代的读取路径和标签。因此我们需要有一个路径和标签的 ‘容器’供我们读
def __getitem__(self, index):
raise NotImplementedError
#返回数据的长度
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
我们通过继承Dataset类来创建我们自己的数据加载类,命名为FaceDataset,完整代码如下:
import torch
from torch.utils import data
import numpy as np
import pandas as pd
import cv2
# 我们通过继承Dataset类来创建我们自己的数据加载类,命名为FaceDataset
class FaceDataset(data.Dataset):
'''
首先要做的是类的初始化。之前的image-emotion对照表已经创建完毕,
在加载数据时需用到其中的信息。因此在初始化过程中,我们需要完成对image-emotion对照表中数据的读取工作。
通过pandas库读取数据,随后将读取到的数据放入list或numpy中,方便后期索引。
'''
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
self.root = root
df_path = pd.read_csv(root + '\\image_emotion.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '\\image_emotion.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
'''
接着就要重写getitem()函数了,该函数的功能是加载数据。
在前面的初始化部分,我们已经获取了所有图片的地址,在这个函数中,我们就要通过地址来读取数据。
由于是读取图片数据,因此仍然借助opencv库。
需要注意的是,之前可视化数据部分将像素值恢复为人脸图片并保存,得到的是3通道的灰色图(每个通道都完全一样),
而在这里我们只需要用到单通道,因此在图片读取过程中,即使原图本来就是灰色的,但我们还是要加入参数从cv2.COLOR_BGR2GARY,
保证读出来的数据是单通道的。读取出来之后,可以考虑进行一些基本的图像处理操作,如通过高斯模糊降噪、通过直方图均衡化来增强图像等。
读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d() API所接受的数据格式是(batch_size, channel, width, higth),
本次图片通道为1,因此我们要将48X48 reshape为1X48X48。
'''
# 读取某幅图片,item为索引号
def __getitem__(self, item):
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 高斯模糊
# face_Gus = cv2.GaussianBlur(face_gray, (3,3), 0)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
# 像素值标准化
face_normalized = face_hist.reshape(1, 48, 48) / 255.0 # 为与pytorch中卷积神经网络API的设计相适配,需reshape原图
# 用于训练的数据需为tensor类型
face_tensor = torch.from_numpy(face_normalized) # 将python中的numpy数据类型转化为pytorch中的tensor数据类型
face_tensor = face_tensor.type('torch.FloatTensor') # 指定为'torch.FloatTensor'型,否则送进模型后会因数据类型不匹配而报错
label = self.label[item]
return face_tensor, label
'''
最后就是重写len()函数获取数据集大小了。
self.path中存储着所有的图片名,获取self.path第一维的大小,即为数据集的大小。
'''
# 获取数据集样本个数
def __len__(self):
return self.path.shape[0]
3.8 网络模型搭建
这里采用的是基于 CNN 的优化模型,这个模型是源于github一个做表情识别的开源项目,可惜即使借用了这个项目的模型结构,但却没能达到源项目中的精度(acc在74%)。下图为该开源项目中公布的两个模型结构,这里我采用的是 Model B ,且只采用了其中的卷积-全连接部分,如果大家希望进一步提高模型的表现能力,可以参考项目的说明文档,考虑向模型中添加 Face landmarks + HOG features 部分。
开源项目地址:https://github.com/amineHorseman/facial-expression-recognition-using-cnn
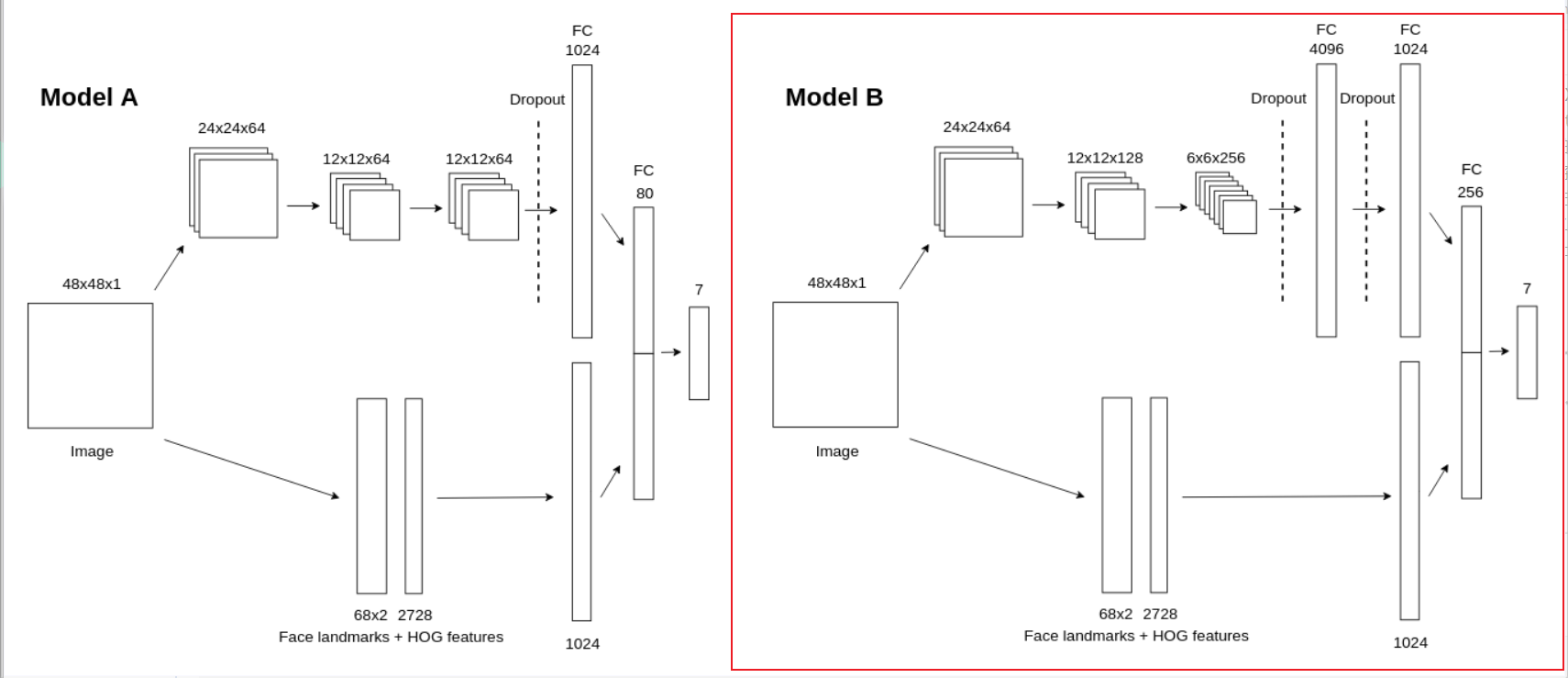
从下图我们可以看出,在 Model B 的卷积部分,输入图片 shape 为 48X48X1,经过一个3X3X64卷积核的卷积操作,再进行一次 2X 2的池化,得到一个 24X24X64 的 feature map 1(以上卷积和池化操作的步长均为1,每次卷积前的padding为1,下同)。将 feature map 1经过一个 3X3X128 卷积核的卷积操作,再进行一次2X2的池化,得到一个 12X12X128 的 feature map 2。将feature map 2经过一个 3X3X256 卷积核的卷积操作,再进行一次 2X2 的池化,得到一个 6X6X256 的feature map 3。卷积完毕,数据即将进入全连接层。进入全连接层之前,要进行数据扁平化,将feature map 3拉一个成长度为 6X6X256=9216 的一维 tensor。随后数据经过 dropout 后被送进一层含有4096个神经元的隐层,再次经过 dropout 后被送进一层含有 1024 个神经元的隐层,之后经过一层含 256 个神经元的隐层,最终经过含有7个神经元的输出层。一般再输出层后都会加上 softmax 层,取概率最高的类别为分类结果。
接着,我们可以通过继承nn.Module来定义自己的模型类。以下代码实现了上述的模型结构。需要注意的是,在代码中,数据经过最后含7个神经元的线性层后就直接输出了,并没有经过softmax层。这是为什么呢?其实这和Pytorch在这一块的设计机制有关。因为在实际应用中,softmax层常常和交叉熵这种损失函数联合使用,因此Pytorch在设计时,就将softmax运算集成到了交叉熵损失函数CrossEntropyLoss()内部,如果使用交叉熵作为损失函数,就默认在计算损失函数前自动进行softmax操作,不需要我们额外加softmax层。Tensorflow也有类似的机制。
模型代码如下:
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
import cv2
# 参数初始化
def gaussian_weights_init(m):
classname = m.__class__.__name__
# 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.04)
# 验证模型在验证集上的正确率
def validate(model, dataset, batch_size):
val_loader = data.DataLoader(dataset, batch_size)
result, num = 0.0, 0
for images, labels in val_loader:
pred = model.forward(images)
pred = np.argmax(pred.data.numpy(), axis=1)
labels = labels.data.numpy()
result += np.sum((pred == labels))
num += len(images)
acc = result / num
return acc
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# 输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding
# input:(bitch_size, 1, 48, 48), output:(bitch_size, 64, 48, 48), (48-3+2*1)/1+1 = 48
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
# output(bitch_size, 64, 24, 24)
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
有了模型,就可以通过数据的前向传播和误差的反向传播来训练模型了。在此之前,还需要指定优化器(即学习率更新的方式)、损失函数以及训练轮数、学习率等超参数。
在本项目中,采用的优化器是SGD,即随机梯度下降,其中参数weight_decay为正则项系数;损失函数采用的是交叉熵;可以考虑使用学习率衰减。
训练模型代码如下:
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay):
# 载入数据并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
# 构建模型
model = FaceCNN()
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
# 逐轮训练
for epoch in range(epochs):
# 记录损失值
loss_rate = 0
# scheduler.step() # 学习率衰减
model.train() # 模型训练
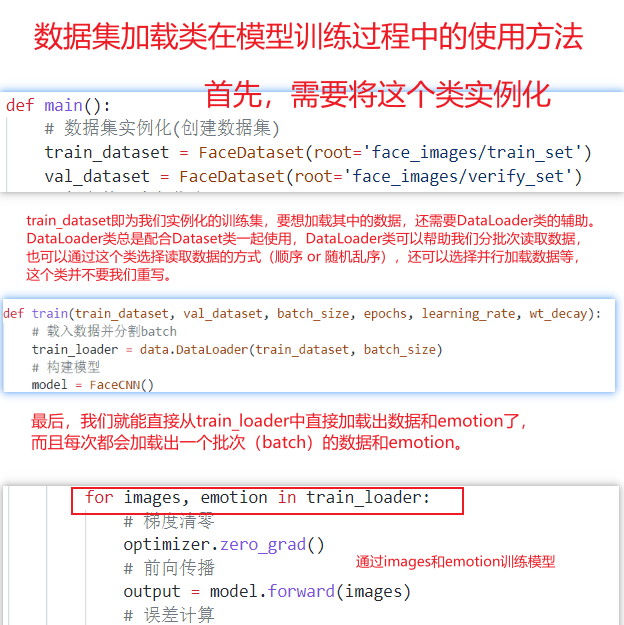
for images, emotion in train_loader:
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model.forward(images)
# 误差计算
loss_rate = loss_function(output, emotion)
# 误差的反向传播
loss_rate.backward()
# 更新参数
optimizer.step()
# 打印每轮的损失
print('After {} epochs , the loss_rate is : '.format(epoch+1), loss_rate.item())
if epoch % 5 == 0:
model.eval() # 模型评估
acc_train = validate(model, train_dataset, batch_size)
acc_val = validate(model, val_dataset, batch_size)
print('After {} epochs , the acc_train is : '.format(epoch+1), acc_train)
print('After {} epochs , the acc_val is : '.format(epoch+1), acc_val)
return model
3.9 数据集的使用
完整的 model_CNN.py 代码如下:
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
import cv2
# 参数初始化
def gaussian_weights_init(m):
classname = m.__class__.__name__
# 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.04)
# 验证模型在验证集上的正确率
def validate(model, dataset, batch_size):
val_loader = data.DataLoader(dataset, batch_size)
result, num = 0.0, 0
for images, labels in val_loader:
pred = model.forward(images)
pred = np.argmax(pred.data.numpy(), axis=1)
labels = labels.data.numpy()
result += np.sum((pred == labels))
num += len(images)
acc = result / num
return acc
# 我们通过继承Dataset类来创建我们自己的数据加载类,命名为FaceDataset
class FaceDataset(data.Dataset):
'''
首先要做的是类的初始化。之前的image-emotion对照表已经创建完毕,
在加载数据时需用到其中的信息。因此在初始化过程中,我们需要完成对image-emotion对照表中数据的读取工作。
通过pandas库读取数据,随后将读取到的数据放入list或numpy中,方便后期索引。
'''
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
self.root = root
df_path = pd.read_csv(root + '\\image_emotion.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '\\image_emotion.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
'''
接着就要重写getitem()函数了,该函数的功能是加载数据。
在前面的初始化部分,我们已经获取了所有图片的地址,在这个函数中,我们就要通过地址来读取数据。
由于是读取图片数据,因此仍然借助opencv库。
需要注意的是,之前可视化数据部分将像素值恢复为人脸图片并保存,得到的是3通道的灰色图(每个通道都完全一样),
而在这里我们只需要用到单通道,因此在图片读取过程中,即使原图本来就是灰色的,但我们还是要加入参数从cv2.COLOR_BGR2GARY,
保证读出来的数据是单通道的。读取出来之后,可以考虑进行一些基本的图像处理操作,
如通过高斯模糊降噪、通过直方图均衡化来增强图像等(经试验证明,在本项目中,直方图均衡化并没有什么卵用,而高斯降噪甚至会降低正确率,可能是因为图片分辨率本来就较低,模糊后基本上什么都看不清了吧)。
读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d() API所接受的数据格式是(batch_size, channel, width, higth),本次图片通道为1,因此我们要将48X48 reshape为1X48X48。
'''
# 读取某幅图片,item为索引号
def __getitem__(self, item):
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 高斯模糊
# face_Gus = cv2.GaussianBlur(face_gray, (3,3), 0)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
# 像素值标准化
face_normalized = face_hist.reshape(1, 48, 48) / 255.0 # 为与pytorch中卷积神经网络API的设计相适配,需reshape原图
# 用于训练的数据需为tensor类型
face_tensor = torch.from_numpy(face_normalized) # 将python中的numpy数据类型转化为pytorch中的tensor数据类型
face_tensor = face_tensor.type('torch.FloatTensor') # 指定为'torch.FloatTensor'型,否则送进模型后会因数据类型不匹配而报错
label = self.label[item]
return face_tensor, label
'''
最后就是重写len()函数获取数据集大小了。
self.path中存储着所有的图片名,获取self.path第一维的大小,即为数据集的大小。
'''
# 获取数据集样本个数
def __len__(self):
return self.path.shape[0]
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# 输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding
# input:(bitch_size, 1, 48, 48), output:(bitch_size, 64, 48, 48), (48-3+2*1)/1+1 = 48
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
# output(bitch_size, 64, 24, 24)
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay):
# 载入数据并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
# 构建模型
model = FaceCNN()
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
# 逐轮训练
for epoch in range(epochs):
# 记录损失值
loss_rate = 0
# scheduler.step() # 学习率衰减
model.train() # 模型训练
for images, emotion in train_loader:
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model.forward(images)
# 误差计算
loss_rate = loss_function(output, emotion)
# 误差的反向传播
loss_rate.backward()
# 更新参数
optimizer.step()
# 打印每轮的损失
print('After {} epochs , the loss_rate is : '.format(epoch+1), loss_rate.item())
if epoch % 5 == 0:
model.eval() # 模型评估
acc_train = validate(model, train_dataset, batch_size)
acc_val = validate(model, val_dataset, batch_size)
print('After {} epochs , the acc_train is : '.format(epoch+1), acc_train)
print('After {} epochs , the acc_val is : '.format(epoch+1), acc_val)
return model
def main():
# 数据集实例化(创建数据集)
train_dataset = FaceDataset(root='face_images/train_set')
val_dataset = FaceDataset(root='face_images/verify_set')
# 超参数可自行指定
model = train(train_dataset, val_dataset, batch_size=128, epochs=100, learning_rate=0.1, wt_decay=0)
# 保存模型
torch.save(model, 'model/model_cnn.pkl')
if __name__ == '__main__':
main()
3.10 保存模型
运行model_CNN.py模型代码
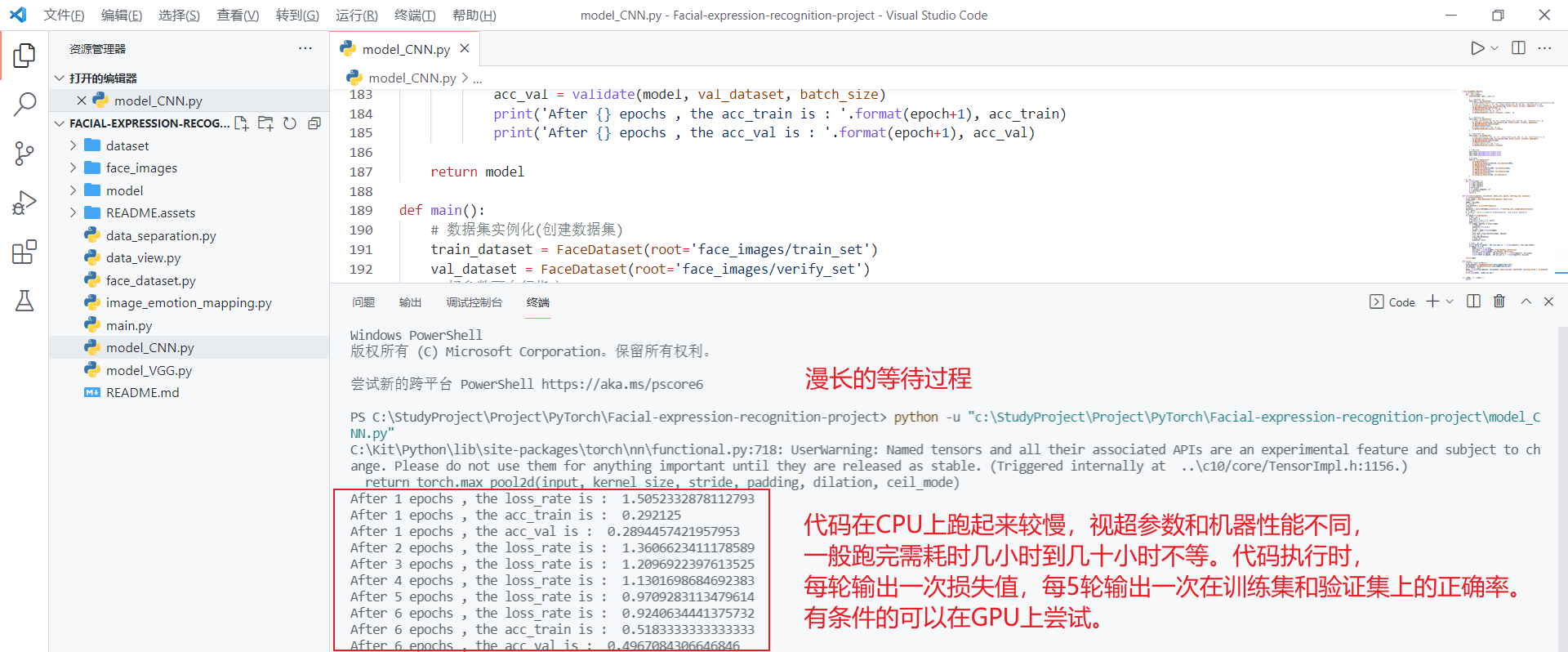
生成模型并保存

3.11 模型的测试
3.11.1 加载模型
3.11.2 人脸面部表情识别测试
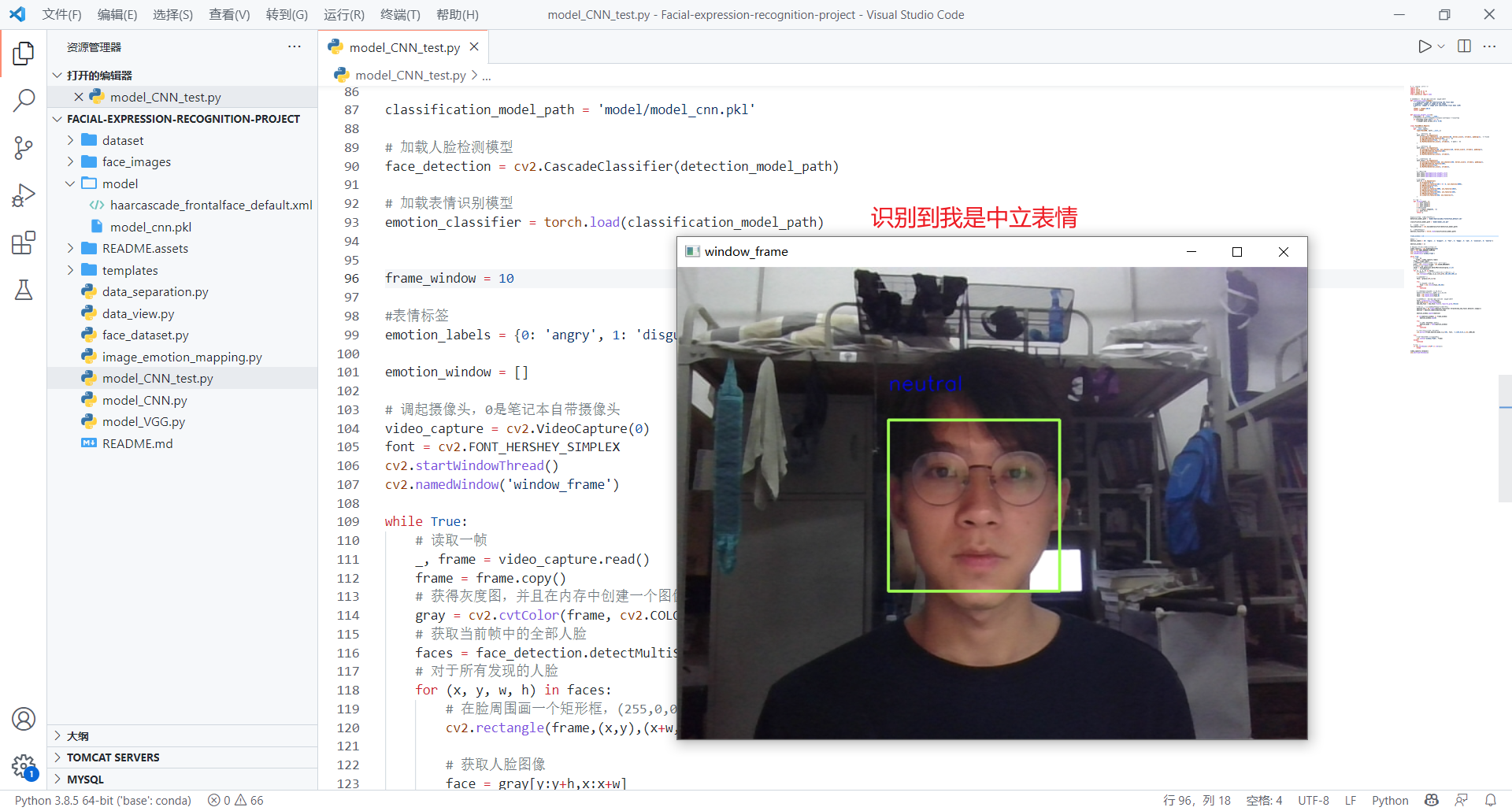
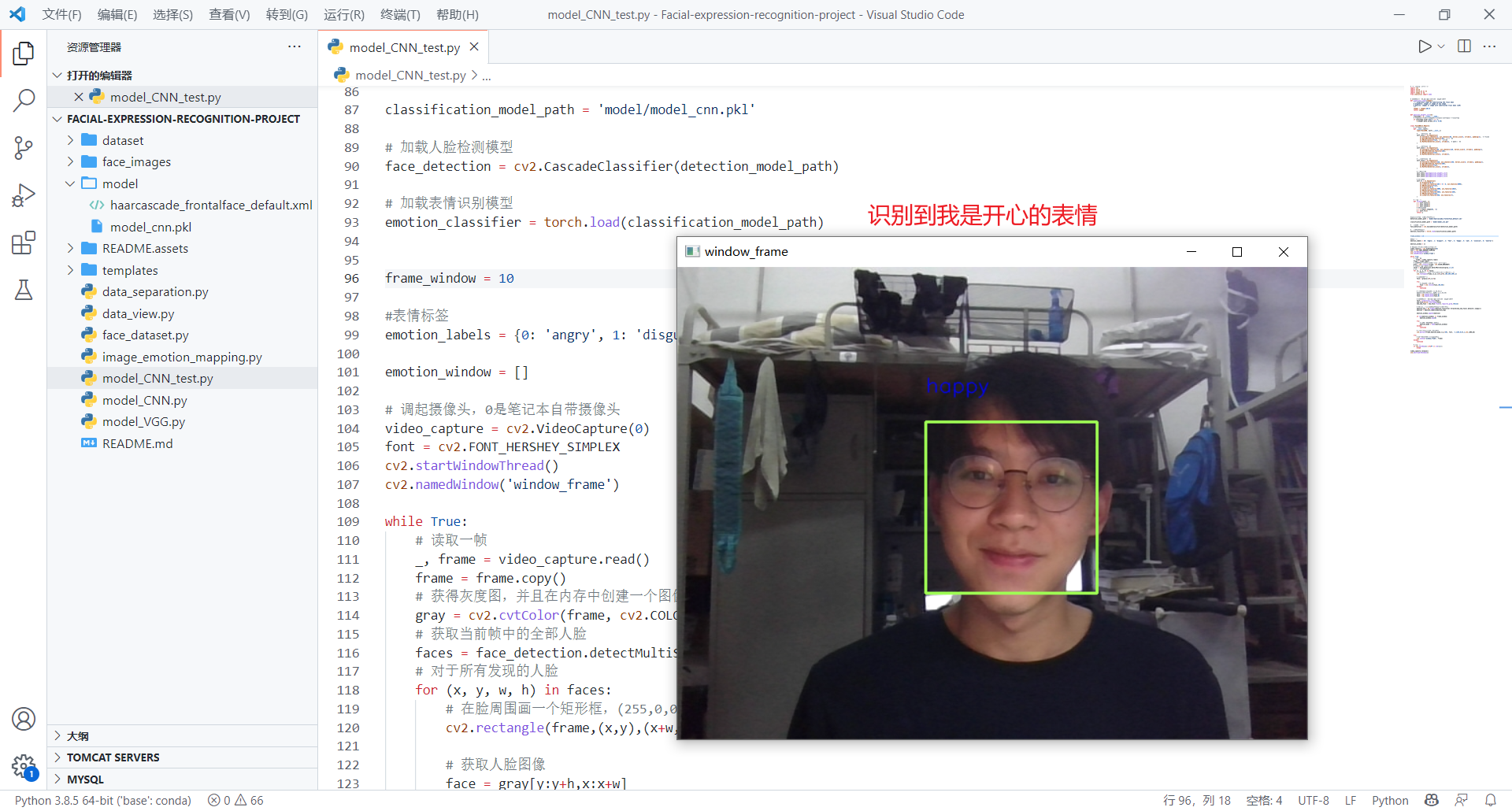
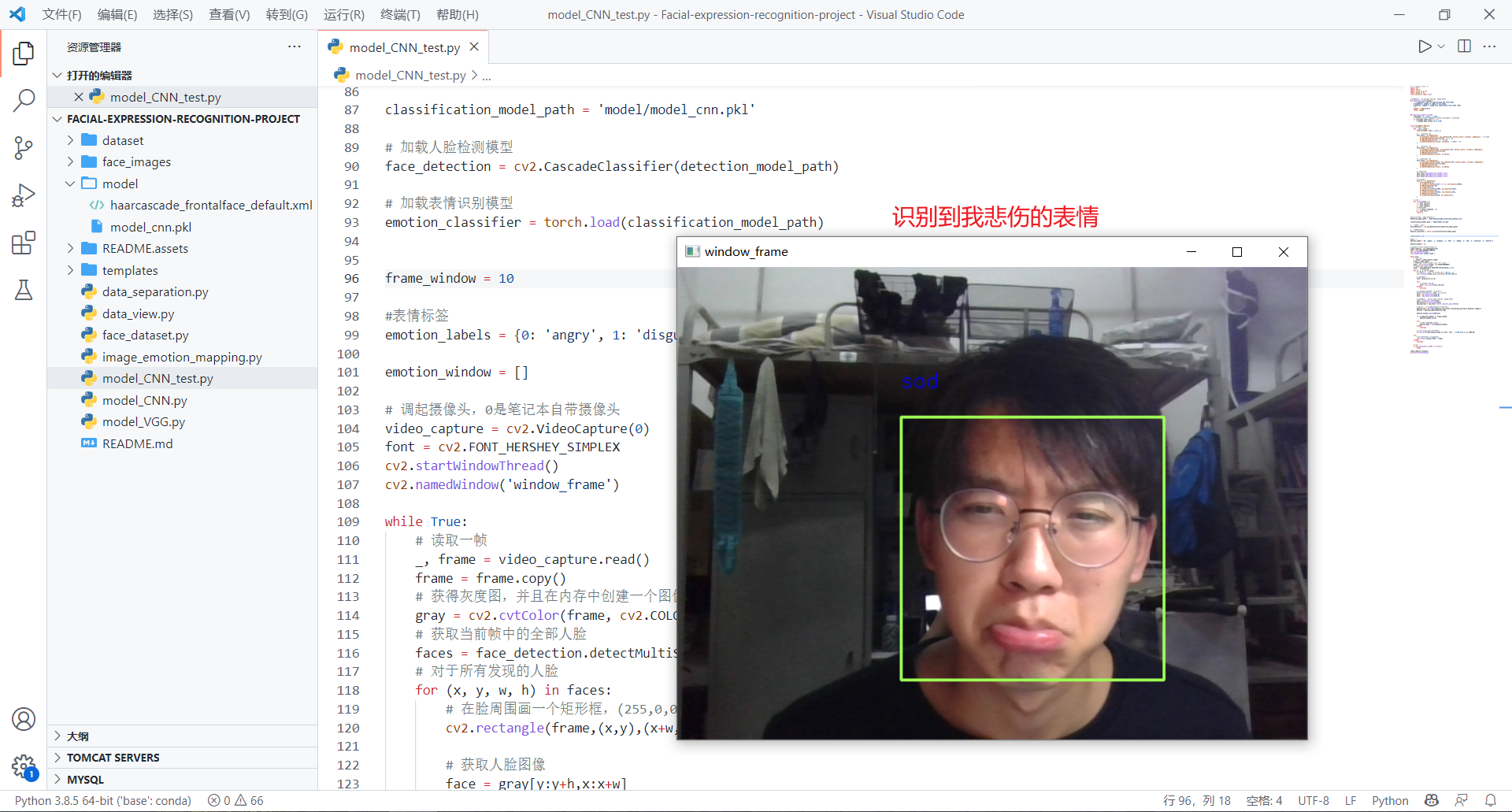
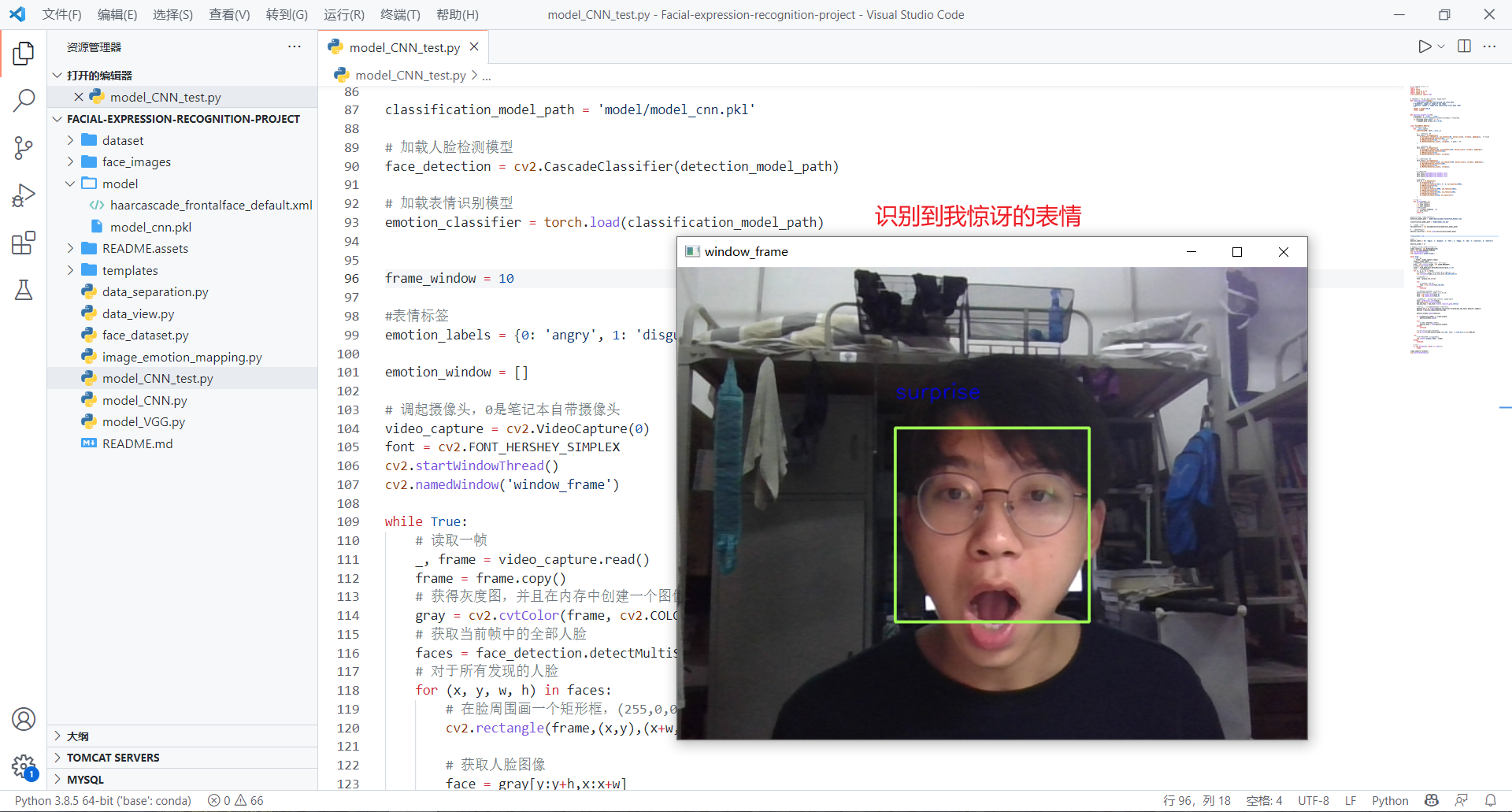
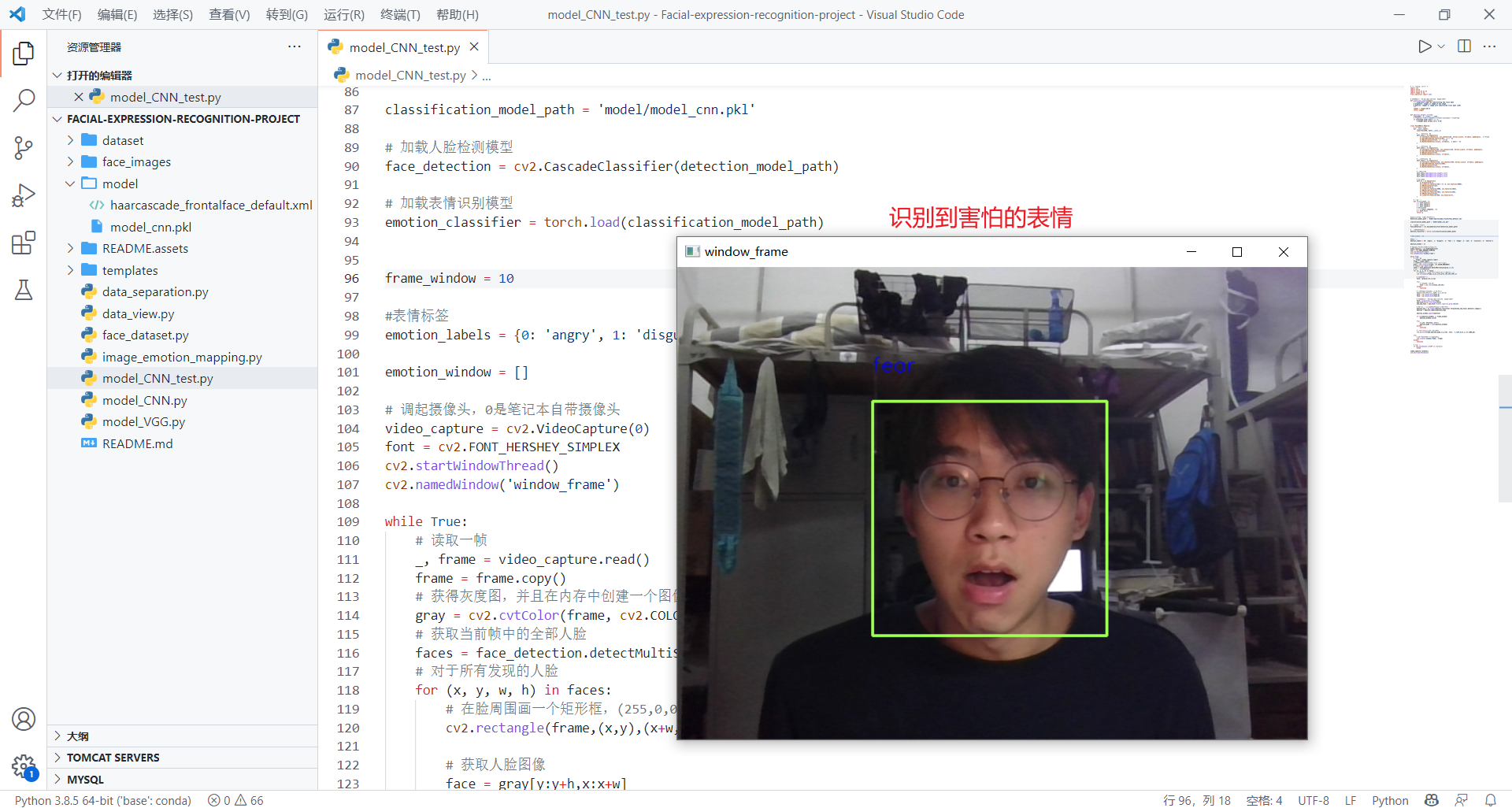
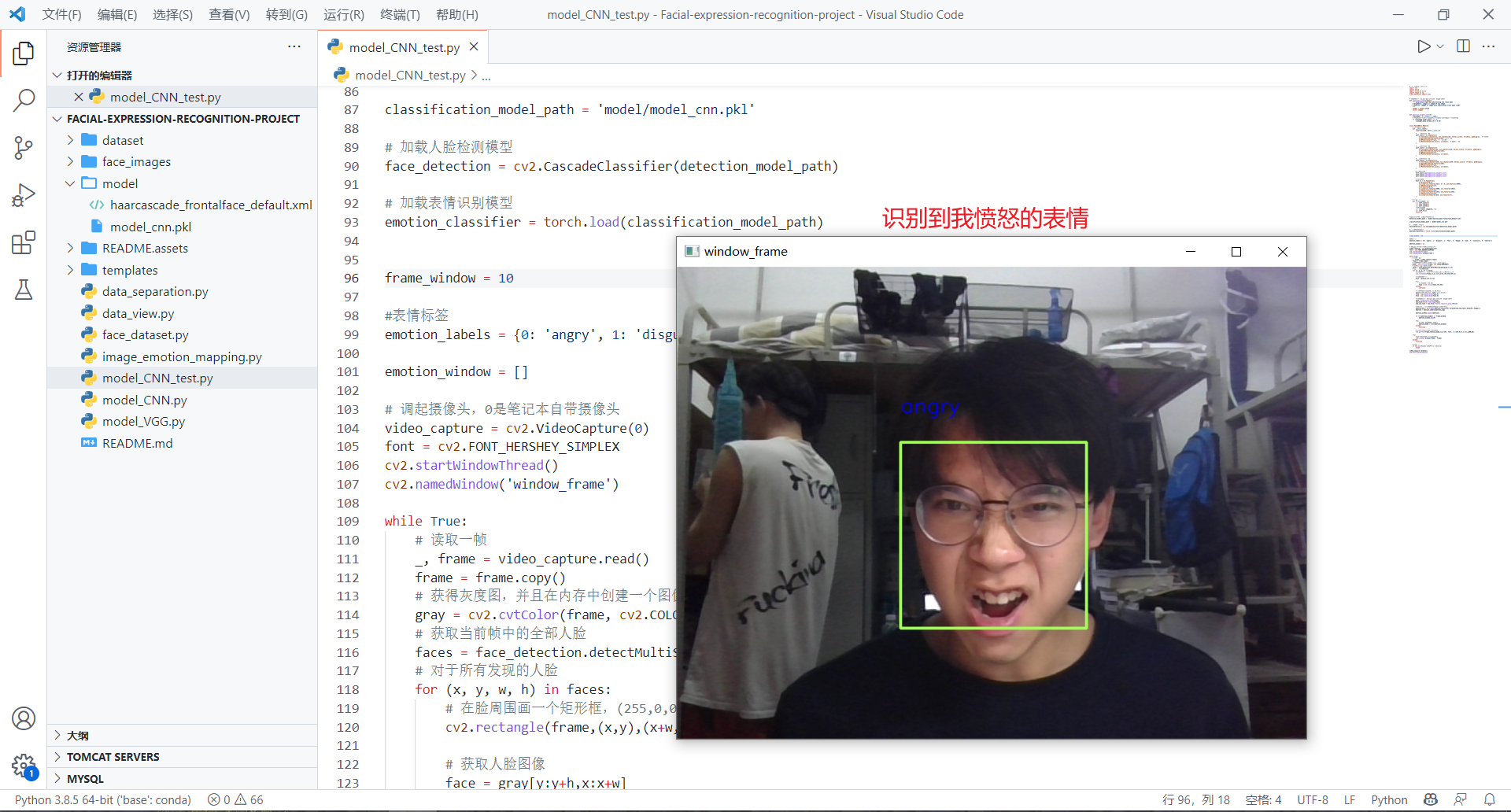
自己测试(看看自己想表达的表情和识别的结果是否一致)
使用视频进行测试
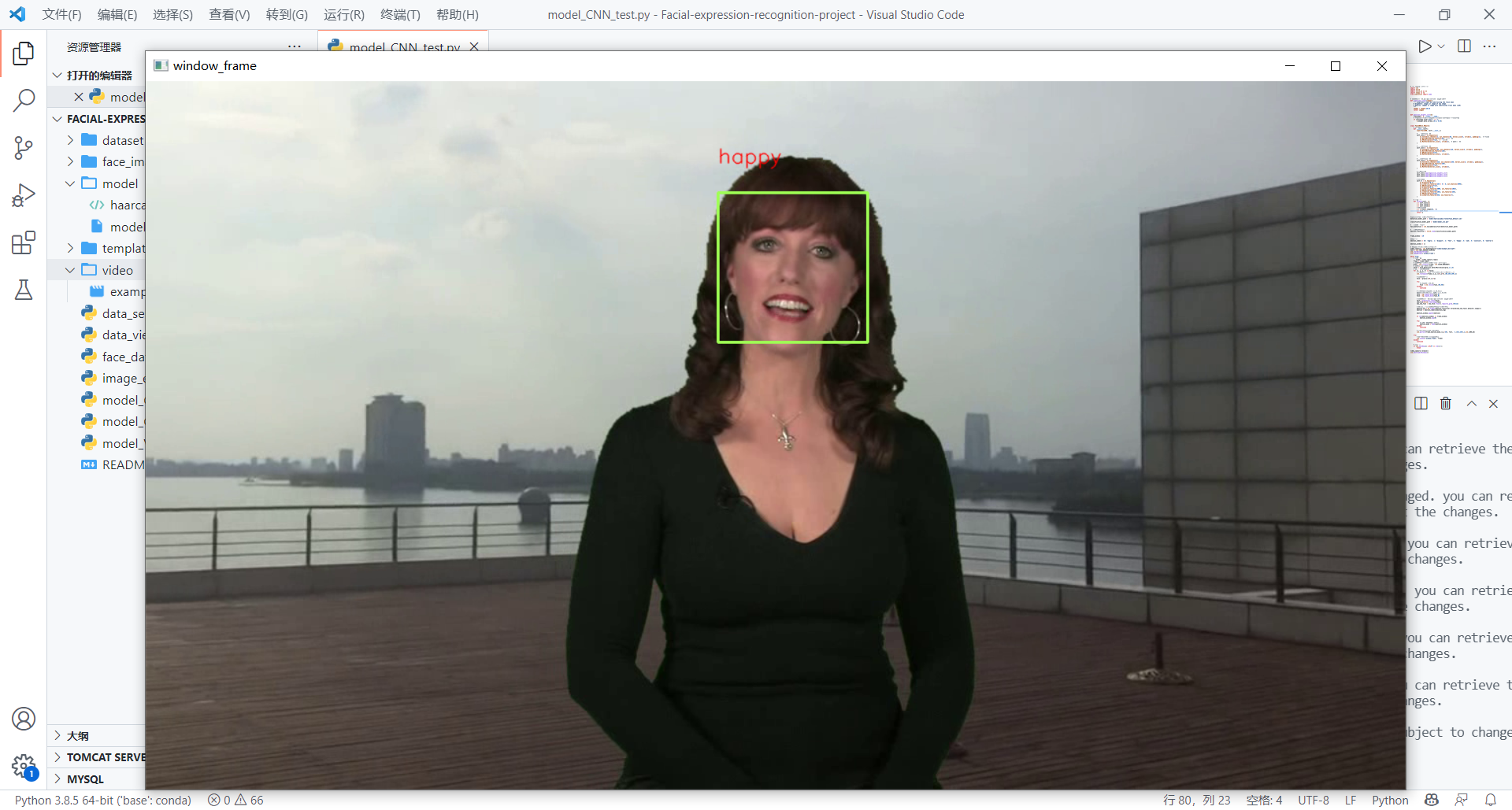
3.12 模型的优化
通过模型的测试,对于自己的面部表情识别,我自己想表达的表情和识别的结果匹配还是有些不一致的(正确率有误差),以及在视频测试中,我认为视频里的人的表情和实际识别的结果也有差异对于测试中存在的问题,有以下原因:
-
训练的数据集还不够
-
训练的模型不够完善
因此,我们可以用理论部分提出的另外两种模型VGG模型和ResNet模型,对现有的项目进行优化
3.12.1 采用VGG模型优化
有关VGG模型的代码原型,我在templates文件夹下整理好了给大家。数据集Flowers放在了dataset目录下,大家记得在代码原型里面更改相关路径的一些配置。
接下来,根据VGG模型的原理,我们可以通过继承nn.Module来定义我们自己的基于VGG的模型类,最后将我们自定义的VGG网络模型进行搭建。
模型的代码如下:
class VGG(nn.Module):
def __init__(self, *args):
super(VGG, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((2, 1, 32), (3, 32, 64), (3, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
VGG(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
将模型搭建好之后,我们可以来训练模型了,训练模型的代码如下:
train_loss = []
train_ac = []
vaild_loss = []
vaild_ac = []
y_pred = []
def train(model,device,dataset,optimizer,epoch):
model.train()
correct = 0
for i,(x,y) in tqdm(enumerate(dataset)):
x , y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
loss = criterion(output,y)
loss.backward()
optimizer.step()
train_ac.append(correct/len(data_train))
train_loss.append(loss.item())
print("Epoch {} Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(epoch,loss,correct,len(data_train),100*correct/len(data_train)))
def vaild(model,device,dataset):
model.eval()
correct = 0
with torch.no_grad():
for i,(x,y) in tqdm(enumerate(dataset)):
x,y = x.to(device) ,y.to(device)
output = model(x)
loss = criterion(output,y)
pred = output.max(1,keepdim=True)[1]
global y_pred
y_pred += pred.view(pred.size()[0]).cpu().numpy().tolist()
correct += pred.eq(y.view_as(pred)).sum().item()
vaild_ac.append(correct/len(data_vaild))
vaild_loss.append(loss.item())
print("Test Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(loss,correct,len(data_vaild),100.*correct/len(data_vaild)))
训练后,我们将训练好的模型进行保存,由于我的电脑配置比较拉跨,且用的是CPU,所以训练模型时间需要特别久,在这里就不等待模型最终的训练结果了,大家可以自己去试试。
完整的model_VGG.py代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
BATCH_SIZE = 128
LR = 0.01
EPOCH = 60
DEVICE = torch.device('cpu')
path_train = 'face_images/vgg_train_set'
path_vaild = 'face_images/vgg_vaild_set'
transforms_train = transforms.Compose([
transforms.Grayscale(),#使用ImageFolder默认扩展为三通道,重新变回去就行
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5),#随机调整亮度和对比度
transforms.ToTensor()
])
transforms_vaild = transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
data_train = torchvision.datasets.ImageFolder(root=path_train,transform=transforms_train)
data_vaild = torchvision.datasets.ImageFolder(root=path_vaild,transform=transforms_vaild)
train_set = torch.utils.data.DataLoader(dataset=data_train,batch_size=BATCH_SIZE,shuffle=True)
vaild_set = torch.utils.data.DataLoader(dataset=data_vaild,batch_size=BATCH_SIZE,shuffle=False)
class VGG(nn.Module):
def __init__(self, *args):
super(VGG, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((2, 1, 32), (3, 32, 64), (3, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
VGG(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
model = vgg(conv_arch, fc_features, fc_hidden_units)
model.to(DEVICE)
optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
#optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
train_loss = []
train_ac = []
vaild_loss = []
vaild_ac = []
y_pred = []
def train(model,device,dataset,optimizer,epoch):
model.train()
correct = 0
for i,(x,y) in tqdm(enumerate(dataset)):
x , y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
loss = criterion(output,y)
loss.backward()
optimizer.step()
train_ac.append(correct/len(data_train))
train_loss.append(loss.item())
print("Epoch {} Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(epoch,loss,correct,len(data_train),100*correct/len(data_train)))
def vaild(model,device,dataset):
model.eval()
correct = 0
with torch.no_grad():
for i,(x,y) in tqdm(enumerate(dataset)):
x,y = x.to(device) ,y.to(device)
output = model(x)
loss = criterion(output,y)
pred = output.max(1,keepdim=True)[1]
global y_pred
y_pred += pred.view(pred.size()[0]).cpu().numpy().tolist()
correct += pred.eq(y.view_as(pred)).sum().item()
vaild_ac.append(correct/len(data_vaild))
vaild_loss.append(loss.item())
print("Test Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(loss,correct,len(data_vaild),100.*correct/len(data_vaild)))
def RUN():
for epoch in range(1,EPOCH+1):
'''if epoch==15 :
LR = 0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
if(epoch>30 and epoch%15==0):
LR*=0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
'''
#尝试动态学习率
train(model,device=DEVICE,dataset=train_set,optimizer=optimizer,epoch=epoch)
vaild(model,device=DEVICE,dataset=vaild_set)
#保存模型
torch.save(model,'model/model_vgg.pkl')
if __name__ == '__main__':
RUN()
最后,我们只需要拿到我们训练好的model_vgg.pkl模型,放到模型测试代码里面,现实地测试一下(同CNN一样,测试自己和测试视频)看看效果如何,将识别结果和实际预期进行对比,看看是否比原来地CNN模型更加准确。(在此不再演示)
完整的model_VGG_test.py代码如下:
# -*- coding: utf-8 -*-
import cv2
import torch
import torch.nn as nn
import numpy as np
from statistics import mode
# 人脸数据归一化,将像素值从0-255映射到0-1之间
def preprocess_input(images):
""" preprocess input by substracting the train mean
# Arguments: images or image of any shape
# Returns: images or image with substracted train mean (129)
"""
images = images/255.0
return images
class VGG(nn.Module):
def __init__(self, *args):
super(VGG, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((2, 1, 32), (3, 32, 64), (3, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
VGG(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
#opencv自带的一个面部识别分类器
detection_model_path = 'model/haarcascade_frontalface_default.xml'
classification_model_path = 'model/model_vgg.pkl'
# 加载人脸检测模型
face_detection = cv2.CascadeClassifier(detection_model_path)
# 加载表情识别模型
emotion_classifier = torch.load(classification_model_path)
frame_window = 10
#表情标签
emotion_labels = {
0: 'angry', 1: 'disgust', 2: 'fear', 3: 'happy', 4: 'sad', 5: 'surprise', 6: 'neutral'}
emotion_window = []
# 调起摄像头,0是笔记本自带摄像头
video_capture = cv2.VideoCapture(0)
# 视频文件识别
# video_capture = cv2.VideoCapture("video/example_dsh.mp4")
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.startWindowThread()
cv2.namedWindow('window_frame')
while True:
# 读取一帧
_, frame = video_capture.read()
frame = frame[:,::-1,:]#水平翻转,符合自拍习惯
frame = frame.copy()
# 获得灰度图,并且在内存中创建一个图像对象
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 获取当前帧中的全部人脸
faces = face_detection.detectMultiScale(gray,1.3,5)
# 对于所有发现的人脸
for (x, y, w, h) in faces:
# 在脸周围画一个矩形框,(255,0,0)是颜色,2是线宽
cv2.rectangle(frame,(x,y),(x+w,y+h),(84,255,159),2)
# 获取人脸图像
face = gray[y:y+h,x:x+w]
try:
# shape变为(48,48)
face = cv2.resize(face,(48,48))
except:
continue
# 扩充维度,shape变为(1,48,48,1)
#将(1,48,48,1)转换成为(1,1,48,48)
face = np.expand_dims(face,0)
face = np.expand_dims(face,0)
# 人脸数据归一化,将像素值从0-255映射到0-1之间
face = preprocess_input(face)
new_face=torch.from_numpy(face)
new_new_face = new_face.float().requires_grad_(False)
# 调用我们训练好的表情识别模型,预测分类
emotion_arg = np.argmax(emotion_classifier.forward(new_new_face).detach().numpy())
emotion = emotion_labels[emotion_arg]
emotion_window.append(emotion)
if len(emotion_window) >= frame_window:
emotion_window.pop(0)
try:
# 获得出现次数最多的分类
emotion_mode = mode(emotion_window)
except:
continue
# 在矩形框上部,输出分类文字
cv2.putText(frame,emotion_mode,(x,y-30), font, .7,(0,0,255),1,cv2.LINE_AA)
try:
# 将图片从内存中显示到屏幕上
cv2.imshow('window_frame', frame)
except:
continue
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
3.12.2 采用ResNet模型优化
有关ResNet模型的代码原型,我也在templates文件夹下整理好了给大家。数据集Flowers放在了dataset目录下,大家记得在代码原型里面更改相关路径的一些配置。
同样的,根据ResNet模型的原理,我们可以通过继承nn.Module来定义我们自己的基于ResNet的模型类,最后将我们自定义的ResNet网络模型进行搭建。
模型的代码如下:
class Reshape(nn.Module):
def __init__(self, *args):
super(Reshape, self).__init__()
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
# 残差神经网络
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
resnet = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
resnet.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
resnet.add_module("resnet_block2", resnet_block(64, 128, 2))
resnet.add_module("resnet_block3", resnet_block(128, 256, 2))
resnet.add_module("resnet_block4", resnet_block(256, 512, 2))
resnet.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
resnet.add_module("fc", nn.Sequential(Reshape(), nn.Linear(512, 7)))
将模型搭建好之后,我们可以来训练并模型了,步骤和VGG的大同小异,这里不赘述。由于我的电脑配置比较拉跨,且用的是CPU,所以训练模型时间需要特别久,在这里就不等待模型最终的训练结果了,大家可以自己去试试。
完整的model_ResNet.py训练模型的代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
BATCH_SIZE = 128
LR = 0.01
EPOCH = 60
DEVICE = torch.device('cpu')
path_train = 'face_images/resnet_train_set'
path_vaild = 'face_images/resnet_vaild_set'
transforms_train = transforms.Compose([
transforms.Grayscale(),#使用ImageFolder默认扩展为三通道,重新变回去就行
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5),#随机调整亮度和对比度
transforms.ToTensor()
])
transforms_vaild = transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
data_train = torchvision.datasets.ImageFolder(root=path_train,transform=transforms_train)
data_vaild = torchvision.datasets.ImageFolder(root=path_vaild,transform=transforms_vaild)
train_set = torch.utils.data.DataLoader(dataset=data_train,batch_size=BATCH_SIZE,shuffle=True)
vaild_set = torch.utils.data.DataLoader(dataset=data_vaild,batch_size=BATCH_SIZE,shuffle=False)
class ResNet(nn.Module):
def __init__(self, *args):
super(ResNet, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
# 残差神经网络
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
resnet = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
resnet.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
resnet.add_module("resnet_block2", resnet_block(64, 128, 2))
resnet.add_module("resnet_block3", resnet_block(128, 256, 2))
resnet.add_module("resnet_block4", resnet_block(256, 512, 2))
resnet.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
resnet.add_module("fc", nn.Sequential(ResNet(), nn.Linear(512, 7)))
model = resnet
model.to(DEVICE)
optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
#optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
train_loss = []
train_ac = []
vaild_loss = []
vaild_ac = []
y_pred = []
def train(model,device,dataset,optimizer,epoch):
model.train()
correct = 0
for i,(x,y) in tqdm(enumerate(dataset)):
x , y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
loss = criterion(output,y)
loss.backward()
optimizer.step()
train_ac.append(correct/len(data_train))
train_loss.append(loss.item())
print("Epoch {} Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(epoch,loss,correct,len(data_train),100*correct/len(data_train)))
def vaild(model,device,dataset):
model.eval()
correct = 0
with torch.no_grad():
for i,(x,y) in tqdm(enumerate(dataset)):
x,y = x.to(device) ,y.to(device)
output = model(x)
loss = criterion(output,y)
pred = output.max(1,keepdim=True)[1]
global y_pred
y_pred += pred.view(pred.size()[0]).cpu().numpy().tolist()
correct += pred.eq(y.view_as(pred)).sum().item()
vaild_ac.append(correct/len(data_vaild))
vaild_loss.append(loss.item())
print("Test Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(loss,correct,len(data_vaild),100.*correct/len(data_vaild)))
def RUN():
for epoch in range(1,EPOCH+1):
'''if epoch==15 :
LR = 0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
if(epoch>30 and epoch%15==0):
LR*=0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
'''
#尝试动态学习率
train(model,device=DEVICE,dataset=train_set,optimizer=optimizer,epoch=epoch)
vaild(model,device=DEVICE,dataset=vaild_set)
torch.save(model,'model/model_resnet.pkl')
if __name__ == '__main__':
RUN()
最后,我们只需要拿到我们训练好的model_resnet.pkl模型,放到模型测试代码里面,现实地测试一下(同CNN一样,测试自己和测试视频)看看效果如何,将识别结果和实际预期进行对比,看看是否比原来地CNN模型更加准确。(在此不再演示)
完整的model_ResNet_test.py代码如下:
# -*- coding: utf-8 -*-
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from statistics import mode
# 人脸数据归一化,将像素值从0-255映射到0-1之间
def preprocess_input(images):
""" preprocess input by substracting the train mean
# Arguments: images or image of any shape
# Returns: images or image with substracted train mean (129)
"""
images = images/255.0
return images
class ResNet(nn.Module):
def __init__(self, *args):
super(ResNet, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
# 残差神经网络
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
resnet = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
resnet.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
resnet.add_module("resnet_block2", resnet_block(64, 128, 2))
resnet.add_module("resnet_block3", resnet_block(128, 256, 2))
resnet.add_module("resnet_block4", resnet_block(256, 512, 2))
resnet.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
resnet.add_module("fc", nn.Sequential(ResNet(), nn.Linear(512, 7)))
#opencv自带的一个面部识别分类器
detection_model_path = 'model/haarcascade_frontalface_default.xml'
classification_model_path = 'model/model_resnet.pkl'
# 加载人脸检测模型
face_detection = cv2.CascadeClassifier(detection_model_path)
# 加载表情识别模型
emotion_classifier = torch.load(classification_model_path)
frame_window = 10
#表情标签
emotion_labels = {
0: 'angry', 1: 'disgust', 2: 'fear', 3: 'happy', 4: 'sad', 5: 'surprise', 6: 'neutral'}
emotion_window = []
# 调起摄像头,0是笔记本自带摄像头
video_capture = cv2.VideoCapture(0)
# 视频文件识别
# video_capture = cv2.VideoCapture("video/example_dsh.mp4")
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.startWindowThread()
cv2.namedWindow('window_frame')
while True:
# 读取一帧
_, frame = video_capture.read()
frame = frame[:,::-1,:]#水平翻转,符合自拍习惯
frame = frame.copy()
# 获得灰度图,并且在内存中创建一个图像对象
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 获取当前帧中的全部人脸
faces = face_detection.detectMultiScale(gray,1.3,5)
# 对于所有发现的人脸
for (x, y, w, h) in faces:
# 在脸周围画一个矩形框,(255,0,0)是颜色,2是线宽
cv2.rectangle(frame,(x,y),(x+w,y+h),(84,255,159),2)
# 获取人脸图像
face = gray[y:y+h,x:x+w]
try:
# shape变为(48,48)
face = cv2.resize(face,(48,48))
except:
continue
# 扩充维度,shape变为(1,48,48,1)
#将(1,48,48,1)转换成为(1,1,48,48)
face = np.expand_dims(face,0)
face = np.expand_dims(face,0)
# 人脸数据归一化,将像素值从0-255映射到0-1之间
face = preprocess_input(face)
new_face=torch.from_numpy(face)
new_new_face = new_face.float().requires_grad_(False)
# 调用我们训练好的表情识别模型,预测分类
emotion_arg = np.argmax(emotion_classifier.forward(new_new_face).detach().numpy())
emotion = emotion_labels[emotion_arg]
emotion_window.append(emotion)
if len(emotion_window) >= frame_window:
emotion_window.pop(0)
try:
# 获得出现次数最多的分类
emotion_mode = mode(emotion_window)
except:
continue
# 在矩形框上部,输出分类文字
cv2.putText(frame,emotion_mode,(x,y-30), font, .7,(0,0,255),1,cv2.LINE_AA)
try:
# 将图片从内存中显示到屏幕上
cv2.imshow('window_frame', frame)
except:
continue
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
3.13 模型的对比分析
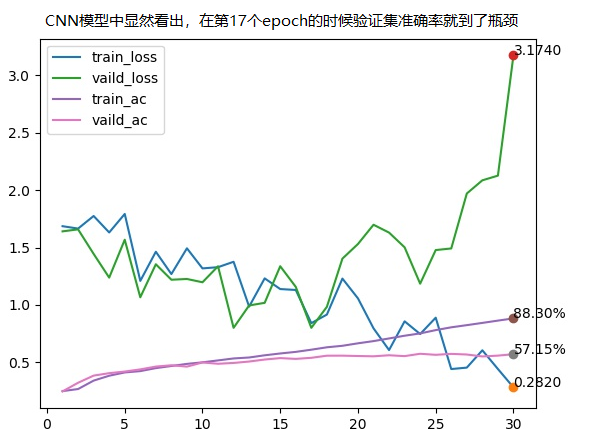 |
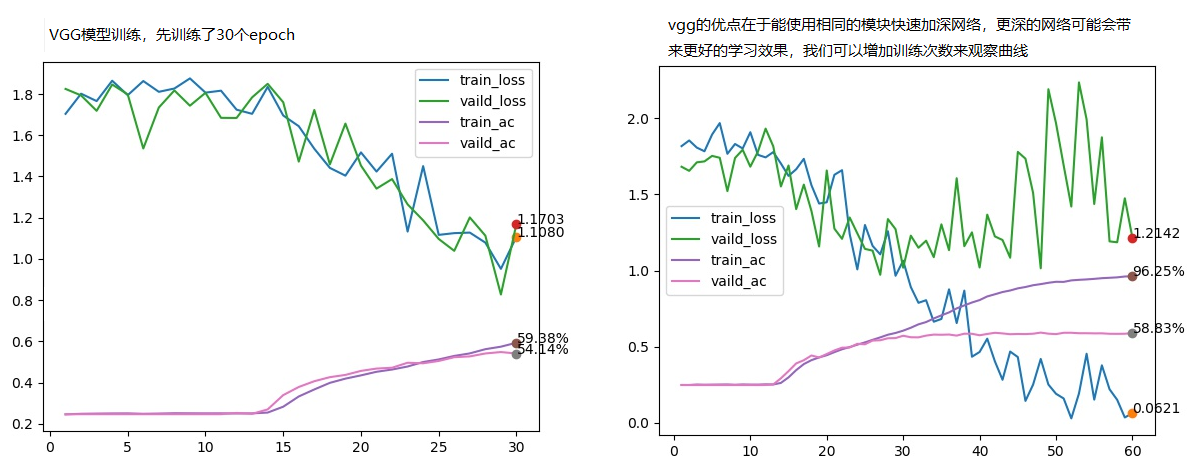 |
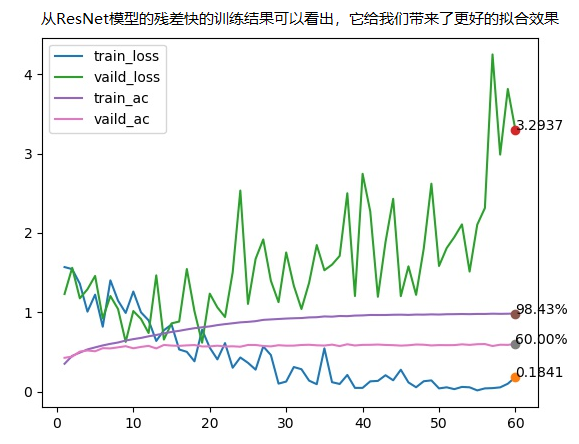 |
|---|---|---|
| CNN | VGG | ResNet |
模型的对比分析完整代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import pandas as pd
from PIL import Image
import os
import matplotlib.pyplot as plt
from tqdm import tqdm
BATCH_SIZE = 128
LR = 0.01
EPOCH = 60
DEVICE = torch.device('cpu')
path_train = '你选定模型的数据集'
path_vaild = '你选定模型的验证集'
transforms_train = transforms.Compose([
transforms.Grayscale(),#使用ImageFolder默认扩展为三通道,重新变回去就行
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ColorJitter(brightness=0.5, contrast=0.5),#随机调整亮度和对比度
transforms.ToTensor()
])
transforms_vaild = transforms.Compose([
transforms.Grayscale(),
transforms.ToTensor()
])
data_train = torchvision.datasets.ImageFolder(root=path_train,transform=transforms_train)
data_vaild = torchvision.datasets.ImageFolder(root=path_vaild,transform=transforms_vaild)
train_set = torch.utils.data.DataLoader(dataset=data_train,batch_size=BATCH_SIZE,shuffle=True)
vaild_set = torch.utils.data.DataLoader(dataset=data_vaild,batch_size=BATCH_SIZE,shuffle=False)
class Reshape(nn.Module):
def __init__(self, *args):
super(Reshape, self).__init__()
def forward(self, x):
return x.view(x.shape[0],-1)
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
CNN = nn.Sequential(
nn.Conv2d(1,64,3),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(64,256,3),
nn.ReLU(True),
nn.MaxPool2d(3,3),
Reshape(),
nn.Linear(256*7*7,4096),
nn.ReLU(True),
nn.Linear(4096,1024),
nn.ReLU(True),
nn.Linear(1024,7)
)
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
conv_arch = ((2, 1, 32), (3, 32, 64), (3, 64, 128))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 128 * 6* 6 # c * w * h
fc_hidden_units = 4096 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(
Reshape(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 7)
))
return net
# 残差神经网络
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
resnet = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7 , stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
resnet.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
resnet.add_module("resnet_block2", resnet_block(64, 128, 2))
resnet.add_module("resnet_block3", resnet_block(128, 256, 2))
resnet.add_module("resnet_block4", resnet_block(256, 512, 2))
resnet.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
resnet.add_module("fc", nn.Sequential(Reshape(), nn.Linear(512, 7)))
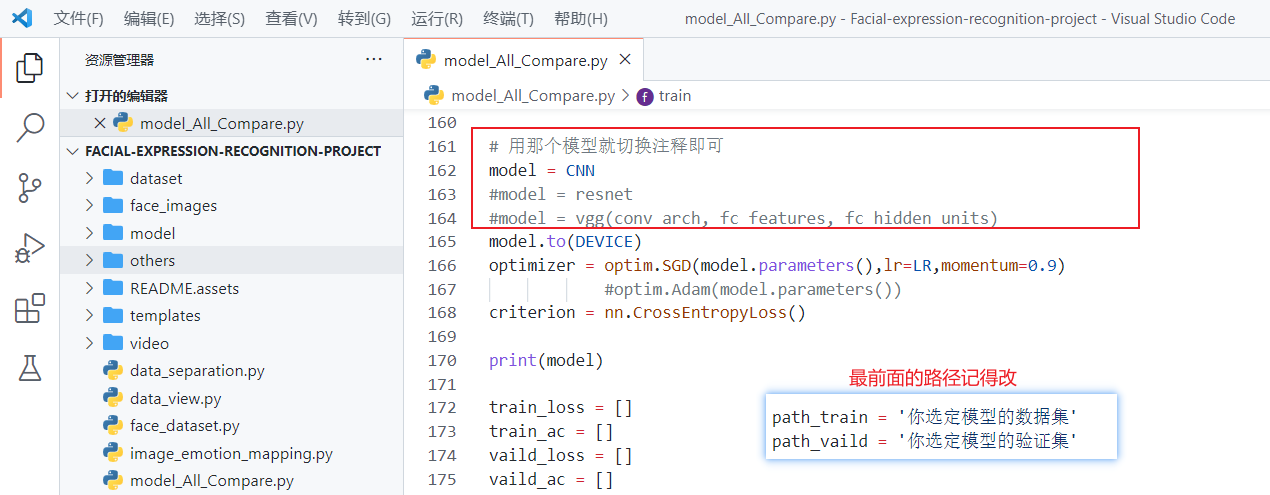
# 用那个模型就切换注释即可
model = CNN
#model = resnet
#model = vgg(conv_arch, fc_features, fc_hidden_units)
model.to(DEVICE)
optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
#optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
print(model)
train_loss = []
train_ac = []
vaild_loss = []
vaild_ac = []
y_pred = []
def train(model,device,dataset,optimizer,epoch):
model.train()
correct = 0
for i,(x,y) in tqdm(enumerate(dataset)):
x , y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
loss = criterion(output,y)
loss.backward()
optimizer.step()
train_ac.append(correct/len(data_train))
train_loss.append(loss.item())
print("Epoch {} Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(epoch,loss,correct,len(data_train),100*correct/len(data_train)))
def vaild(model,device,dataset):
model.eval()
correct = 0
with torch.no_grad():
for i,(x,y) in tqdm(enumerate(dataset)):
x,y = x.to(device) ,y.to(device)
output = model(x)
loss = criterion(output,y)
pred = output.max(1,keepdim=True)[1]
global y_pred
y_pred += pred.view(pred.size()[0]).cpu().numpy().tolist()
correct += pred.eq(y.view_as(pred)).sum().item()
vaild_ac.append(correct/len(data_vaild))
vaild_loss.append(loss.item())
print("Test Loss {:.4f} Accuracy {}/{} ({:.0f}%)".format(loss,correct,len(data_vaild),100.*correct/len(data_vaild)))
def RUN():
for epoch in range(1,EPOCH+1):
'''if epoch==15 :
LR = 0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
if(epoch>30 and epoch%15==0):
LR*=0.1
optimizer=optimizer = optim.SGD(model.parameters(),lr=LR,momentum=0.9)
'''
#尝试动态学习率
train(model,device=DEVICE,dataset=train_set,optimizer=optimizer,epoch=epoch)
vaild(model,device=DEVICE,dataset=vaild_set)
torch.save(model,'m0.pth')
RUN()
#vaild(model,device=DEVICE,dataset=vaild_set)
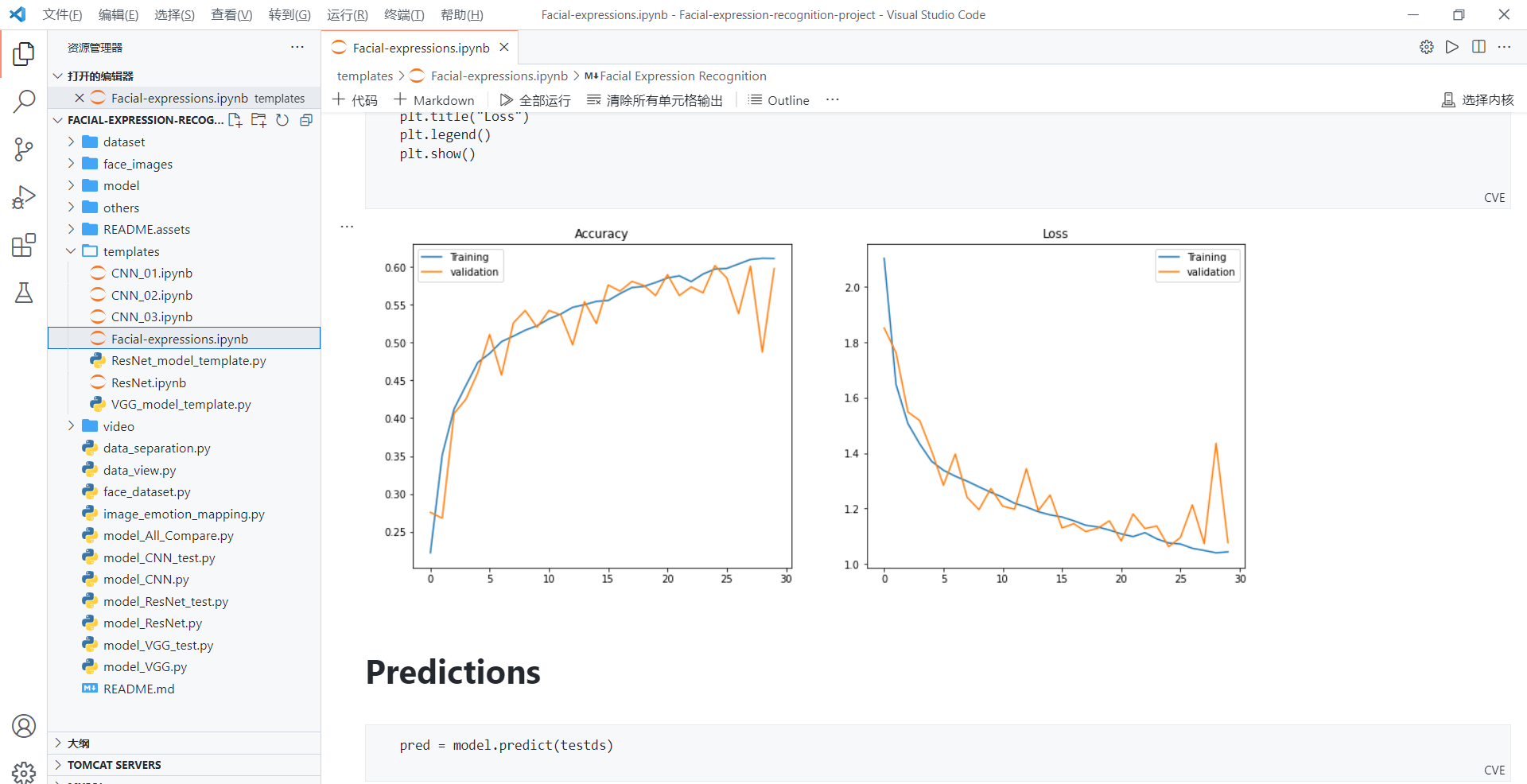
def print_plot(train_plot,vaild_plot,train_text,vaild_text,ac,name):
x= [i for i in range(1,len(train_plot)+1)]
plt.plot(x,train_plot,label=train_text)
plt.plot(x[-1],train_plot[-1],marker='o')
plt.annotate("%.2f%%"%(train_plot[-1]*100) if ac else "%.4f"%(train_plot[-1]),xy=(x[-1],train_plot[-1]))
plt.plot(x,vaild_plot,label=vaild_text)
plt.plot(x[-1],vaild_plot[-1],marker='o')
plt.annotate("%.2f%%"%(vaild_plot[-1]*100) if ac else "%.4f"%(vaild_plot[-1]),xy=(x[-1],vaild_plot[-1]))
plt.legend()
plt.savefig(name)
#print_plot(train_loss,vaild_loss,"train_loss","vaild_loss",False,"loss.jpg")
#print_plot(train_ac,vaild_ac,"train_ac","vaild_ac",True,"ac.jpg")
import seaborn as sns
from sklearn.metrics import confusion_matrix
emotion = ["angry","disgust","fear","happy","sad","surprised","neutral"]
sns.set()
f,ax=plt.subplots()
y_true = [ emotion[i] for _,i in data_vaild]
y_pred = [emotion[i] for i in y_pred]
C2= confusion_matrix(y_true, y_pred, labels=["angry","disgust","fear","happy","sad","surprised","neutral"])#[0, 1, 2,3,4,5,6])
#print(C2) #打印出来看看
sns.heatmap(C2,annot=True ,fmt='.20g',ax=ax) #热力图
ax.set_title('confusion matrix') #标题
ax.set_xlabel('predict') #x轴
ax.set_ylabel('true') #y轴
plt.savefig('matrix.jpg')
如果你还想看更多的不同模型的训练结果,以及相关数据读取,处理与分析,可以去FER2013数据集官网下载别人的代码参考学习,除了看不同模型的对比分析,还能学习其他有关深度学习与计算机视觉的知识(如基于Tensorflow的实现等)
这里我也给大家下载了一些模板参考:(放在了templates文件夹下)
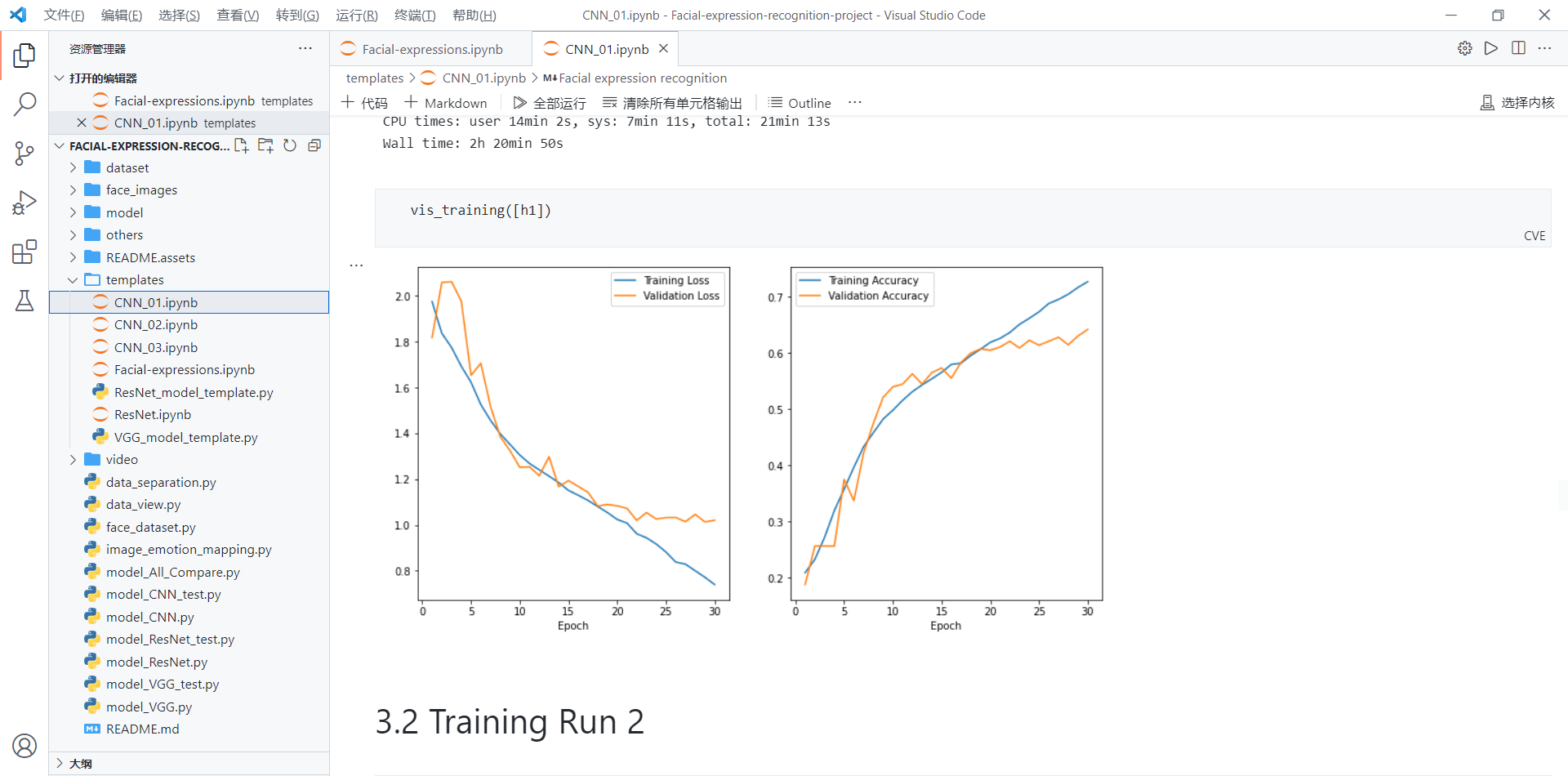
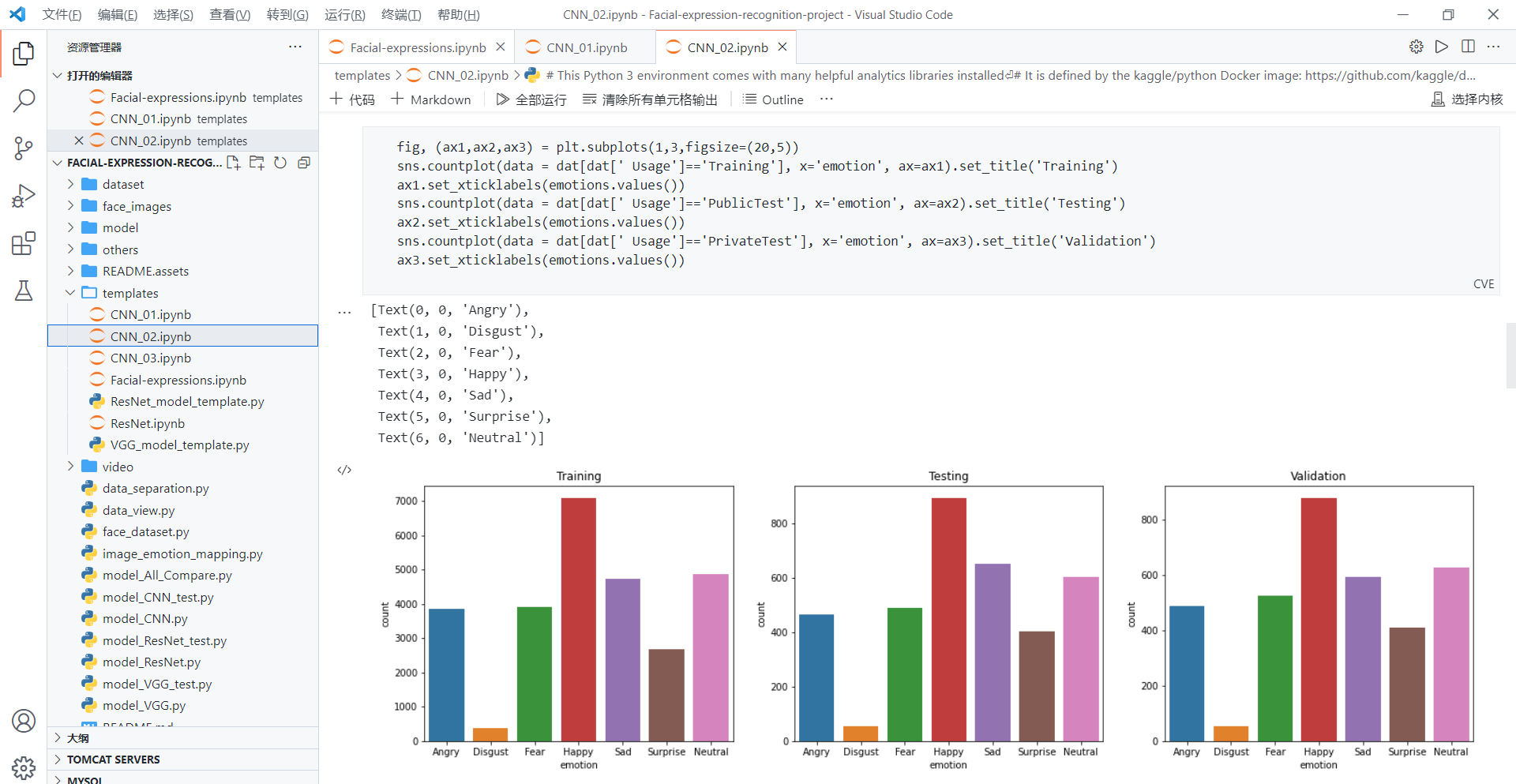
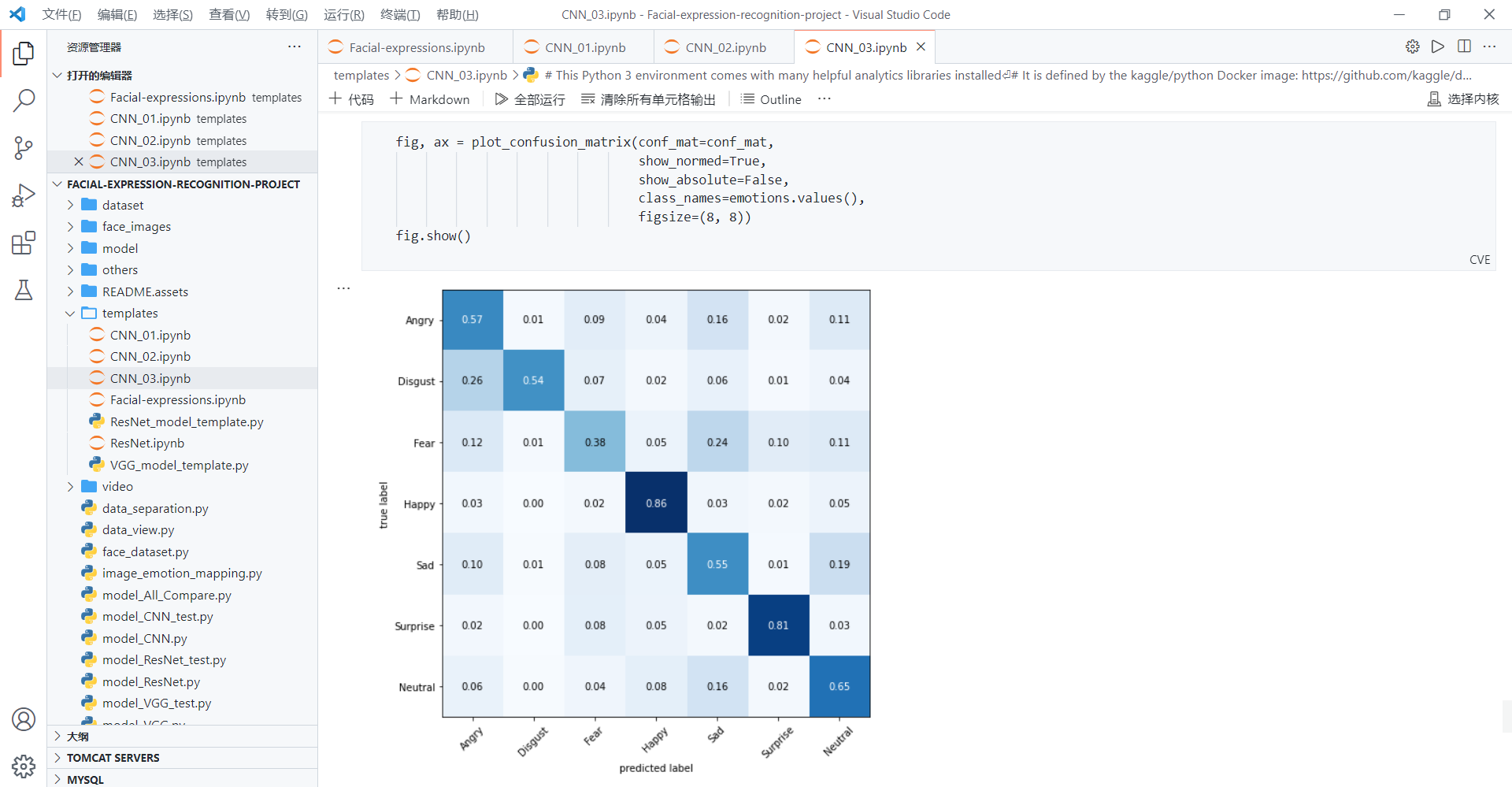
四、总结
这是我校本课程选修课程深度学习与计算机视觉期末大作业。本次作业参考学习了很多文章的经验与方法,自己也试着将其归纳总结。完成此次作业也可是不易,但也锻炼了自己的学习能力,虽然有些知识自己还不能够非常能完全掌握理解,但我相信,在后续的学习中,自己对这方面的知识的理解也会加强许多,学无止境,希望和大家一起加油进步吧!
本篇文章引用的资料都已在文末给出,如果需要转载此文,别忘了加上转载标签和地址哦!如果文章中有什么不对的地方,欢迎大家帮忙指出纠正!
本篇文章中的代码全部已经开源在了我的GitHub和Gitee上,欢迎大家前来clone和star!!!
GitHub地址:https://github.com/He-Xiang-best/Facial-Expression-Recognition
Gitee地址:https://gitee.com/hexiang_home/Facial-Expression-Recognition
本项目的数据集下载地址:https://download.csdn.net/download/HXBest/64847238
本项目的模型文件下载地址:https://download.csdn.net/download/HXBest/64955910
五、参考文献
数据集相关:
1、FER2013数据集官网:https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data
2、Pytorch中正确设计并加载数据集方法:https://ptorch.com/news/215.html
3、pytorch加载自己的图像数据集实例:http://www.cppcns.com/jiaoben/python/324744.html
4、python中的图像处理框架进行图像的读取和基本变换:https://oldpan.me/archives/pytorch-transforms-opencv-scikit-image
CNN相关:
1、常见CNN网络结构详解:https://blog.csdn.net/u012897374/article/details/79199935?spm=1001.2014.3001.5506
2、基于CNN优化模型的开源项目地址:https://github.com/amineHorseman/facial-expression-recognition-using-cnn
3、A CNN based pytorch implementation on facial expression recognition (FER2013 and CK+), achieving 73.112% (state-of-the-art) in FER2013 and 94.64% in CK+ dataset:https://github.com/WuJie1010/Facial-Expression-Recognition.Pytorch
VGG相关:
1、VGG论文地址:https://arxiv.org/pdf/1409.1556.pdf
2、VGG模型详解及代码分析:https://blog.csdn.net/weixin_45225975/article/details/109220154#18c8c548-e4c5-24bb-e255-cd1c471af2ff
ResNet相关:
1、ResNet论文地址:https://arxiv.org/pdf/1512.03385.pdf
2、ResNet模型详解及代码分析:https://blog.csdn.net/weixin_44023658/article/details/105843701
3、Batch Normalization(BN)超详细解析:https://blog.csdn.net/weixin_44023658/article/details/105844861
表情识别相关:
1、基于卷积神经网络的面部表情识别(Pytorch实现):https://www.cnblogs.com/HL-space/p/10888556.html
2、Fer2013 表情识别 pytorch (CNN、VGG、Resnet):https://www.cnblogs.com/weiba180/p/12600259.html#resnet
3、OpenCV 使用 pytorch 模型 通过摄像头实时表情识别:https://www.cnblogs.com/weiba180/p/12613764.html