基于CNN的人脸识别(上)
具体代码实现可参看
Keras深度学习应用1——基于卷积神经网络(CNN)的人脸识别(下)
代码下载
Github源码下载地址:
https://github.com/Kyrie-leon/CNN-FaceRec-keras
一、 CNN概述
1.1 CNN发展历程
卷积神经网络由生物学自然视觉认知机制启发而来。1962年,诺贝尔奖得主D.H.Hubel和T.N.Wiesel,这两位学者通过对猫脑部皮层中特定的神经元进行研究时,发现了其独特的网络结构。根据这个启发有学者提出了新识别机(recognition)的概念,这也是深度学习中第一个在真正意义上实现的卷积神经网络。自此以后,科学家们开始对CNN进行了深入的研究和改进。
卷积神经网络是属于前馈神经网络下多层神经网络的一种深度机器学习方法,如下图所示,可以看出神经网络的大致分布。

图1-1 神经网络分布图
与传统的图像处理算法相比,CNN的优点为它能够有效避免在前期准备中,需要对图像进行大量的、繁琐的人工提取特征工作。这也说明,CNN能够直接从图像原始像素出发,只需通过一些预处理过程,就可以识别出图像上的特征规律。但在当时因为研究环境不理想,比如,训练数据集数量有限,并且计算机的图形处理能力跟不上,使得深度学习依赖的两大基础因素:“燃料”和“引擎”,都不能达到理想的运行标准。这也导致了我们熟知的LeNet-5神经网络结构,其在复杂问题的处理上表现的并不理想。随着之后神经网络的发展进入了低潮期,CNN的研究工作也一直没有突破性的进展。
从2006年起,在大数据和高性能计算平台的推动下,科学家们开始重新改造CNN,并设法克服难以训练深层CNN的困难。其中最著名的CNN结构被命名为:AlexNet,它同样也是一个比较经典的结构。在图像识别任务上,AlexNet取得了重大突破,并以创纪录的成绩夺得了当年的ImageNet冠军。它整体的框架与LeNet-5类似,但经过改进后层数要更深一些。
在AlexNet模型取得显著的成绩后,科学家们又相继提出了其他功能完善、效果良好的改进模型。至此,卷积神经网络的发展脉络如下图所示。

卷积神经网络的演变历程(实线表示模型改进,虚线表示模型革新)
从结构看,CNN发展的一个显著特点就是层数变得越来越深,结构也变得越来越复杂,通过增加深度,网络能够抽象出更深层、更抽象的特征。
1.2 CNN基本结构
卷积神经网络,顾名思义,其得名自卷积(convolution)操作,而卷积的目的则是将某些特征从图像中提取出来,正如视觉系统辨识具有方向性的物体边缘一样:首先检测横线、竖线、斜线等具有方向性的基本的物体边缘,然后将若干个边缘组合城物体的部分,最后再根据检测到的物体的部分分析物体具体是什么。
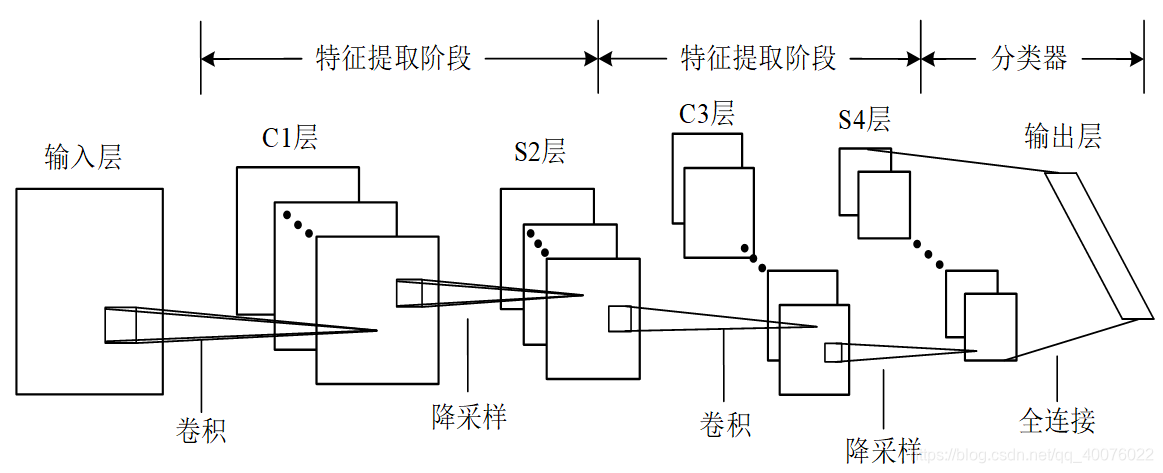
典型的卷积神经网络是一种多层网络结构,每一层中都包含了一定数量的二维平面,在这些二维平面上有许多独立的神经元结构。CNN网络中通常还含有1到3个特征提取阶段,由卷积和池化组成,之后是一个分类器,该部位通常由1到2个全连接层所组成。
一个简单的卷积神经网络模型如图1-3所示。从图中可以看出,该网络模型含有两个特征提取阶段,一个分类器(全连接层)。在CNN的一般结构中,主要由输入层、隐藏层和输出层三部分构成,在隐藏层中同样包含三部分:卷积层(用于特征提取)、池化层(用于特征优化选取)、全连接层(相当于传统多层感知机中的隐藏层)。
二、 CNN算法原理
2.1 CNN基本网络结构
一个典型的卷积神经网络主要由输入层、卷积层、池化层、全连接层、激励层,5种结构构成。一张图像从输入层输入,依次经过卷积层、池化层等多层的特征提取,最终抽象成信息量最高的特征从全连接层输入到Softmax层进行分类。

2.1.1输入层
输入层,顾名思义就是整个CNN的数据输入,通常把一个经过预处理的图像像素矩阵输入到这一层中,对于不同类型的图片输入时需定义图片类型,例如黑白图片就是一幅单通道图像、RGB图片就是三通道图像。
当一幅图像输入到卷积神经网络中后,会经过若干个卷积层和池化层的运算,直至全连接层降维,因此图片的数量和分辨率都会对模型的性能造成一定的影响。
2.1.2卷积层
卷积层是整个卷积神经网络的核心部分,其作用为提取图像特征和数据降维。卷积层包含有多个卷积核,该卷积核的尺寸通常由人工指定为3×3或5×5。
假设卷积核的大小为3×3,其中卷积核为:

如图详细解释了卷积运算的执行过程。首先选取图中的3×3尺寸的conv卷积核,接下来从矩阵A的左上角开始划分出一个和卷积核尺寸同样大小的矩阵,将这个矩阵与conv对应位置上的元素逐个相乘然后求和,得到的值即为新矩阵的第一行第一列的值,然后按照从左到右从上到下的窗口滑动顺序,重复以上步骤(即图中step2-step9),最终得到一个新的矩阵(step9中右侧矩阵)。这个矩阵保存了图像卷积操作后的所有特征。

对于图片的边界线点,CNN的卷积核有两种处理方式。一种是对输入的矩阵不采取任何操作,直接按照上所示的顺序进行卷积操作,但经过该处理方式后输出矩阵的大小发生改变,输入矩阵大于输出矩阵。另一种处理方式是对原矩阵边界进行全0填充(zero-padding)后再进行卷积计算,这种处理方式使得矩阵在输出后尺寸仍然不发生改变,如图所示。

2.1.3池化层
池化(pooling)也称采样(sub sampling)或下采样(down sampling)。池化层可以在保留原图片特征的前提下,非常有效的缩小图片尺寸,减少全连接层中的参数。因此,该步骤又称为降维。添加池化层不仅加速了模型的计算,而且可以防止模型出现的过拟合现象。
池化也是通过一个类似于卷积核的窗口按一定顺序移动来完成的。与卷积层不同的是池化不需要进行矩阵节点的加权运算,常用的池化操作有最大值运算和平均值运算。其相应的池化层也分别被称为最大池化层(max pooling)和平均池化层(average pooling)。其余的池化运算实践中使用较少,本文不做过多赘述。
池化窗口也需要人工指定尺寸,是否使用全零填充等设置。本文选用最大池化层,池化窗口尺寸为2×2,不使用全零填充,则池化过程如图2-3所示。首先将该特征矩阵划分为4个2×2尺寸的矩阵,然后分别取出每个2×2矩阵中的最大像素值Max,最后将每4个矩阵中的最大像素值组成一个新的矩阵,大小为池化窗口的尺寸,即为2×2。如图2-3所示右侧矩阵经过最大池化运算后的操作结果。同样的,分别对每个2×2矩阵取平均值得到的新矩阵即为平均池化操作结果。

2.1.4全连接层
全连接层主要用于综合卷积层和池化层的特征。由于卷积层和池化层都能够提取人脸的特征,因此经过多层的处理后,图像中的信息已经被提取成信息量更高的特征。这些特征通过全连接层后成为一幅图像信息的最终表达,并作为输入特征输入到分类器中完成分类任务。全连接层是整个网络最难训练的部分,如果训练样本过少,则可能造成过拟合现象。因此,采用随机失活(dropout)技术,抑制模型出现的过拟合现象。所谓随机失活是在学习过程中通过将隐藏层(一般为全连接层)的部分节点权重随机归零,从而降低节点间的相互依赖性。
2.1.5 激励层
多层神经网络比单层感知机强大的原因之一,是因为激活函数为它引入了非线性的学习和处理能力。单层感知机因其结构较简单,所以学习能力十分有限,在单一模型的限制下只能被用来解决线性可分问题,不能进行深入的研究。
在神经网络的研究中,常见的激活函数主要有阶跃函数、sigmoid函数、ReLU函数等。其中,阶跃函数可以直接将输入的数据映射为1或者0(1表示处于激活,0表示抑制),但是因为它不连续、不光滑、不可导,所以在实际应用中通常不会将其作为激活函数。sigmoid函数近年来也很少被采用,因为它会在神经网络进行反向传播训练时产生不可解决的梯度消失问题,从而导致训练深层网络的效果不理想。所以这里主要对ReLU函数进行介绍。
在多层神经网络中,要研究的对象更加复杂,需要一个稳定、快速,且具有更好的预测性能的函数作为激活函数。为解决这个需求,线性整流函数(ReLU)于2012年Hinton等人发表的论文中被提出。通过研究发现ReLU的收敛速度相比于其他激活函数要快很多,且能更有效的避免梯度爆炸和梯度消失(层数太大)的问题。目前ReLU函数已作为常用激活函数被应用于多层神经网络。通常情况下将其定义为式:
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
也可以写成

ReLU函数定义了当前神经元在经过线性变换之后的非线性输出结果,其输出可以表示为 。从它函数数学定义上可以看出:当输入大于0的时候,输出就是输入,而当输入小于0时,输出就保持为0了,如图2-4所示。
