数学是达成目的的工具, 理解才是达成目的桥梁, 所以这篇文章用浅显易懂的动画阐述了复杂的机器学习概念.
强烈推荐通过动画的形式了解.
代码实现请来这里看: Python 实现
一 引子
对房屋售价进行预测时,我们的特征仅有房屋面积一项,但是,在实际生活中,卧室数目也一定程度上影响了房屋售价。下面,我们有这样一组训练样本:
| 房屋面积(英尺) | 卧室数量(间) | 售价(美元) |
|---|---|---|
| 2104 | 3 | 399900 |
| 1600 | 3 | 329900 |
| 2400 | 3 | 369000 |
| 1416 | 2 | 232000 |
| 3000 | 4 | 539900 |
| 1985 | 4 | 299900 |
| .... | ... | .... |
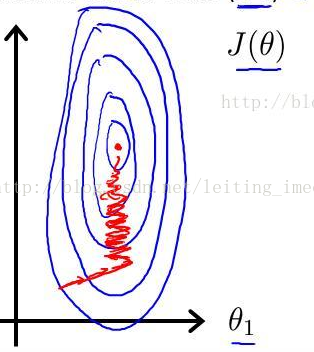
注意到,房屋面积及卧室数量两个特征在数值上差异巨大,如果直接将该样本送入训练,则代价函数的轮廓会是“扁长的”,在找到最优解前,梯度下降的过程不仅是曲折的,也是非常耗时的:
二 归一化
该问题的出现是因为我们没有同等程度的看待各个特征,即我们没有将各个特征量化到统一的区间。
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两种常用的归一化方法:Standardization
Standardization又称为Z-score normalization,量化后的特征将服从标准正态分布:


量化后的特征将分布在区间。
大多数机器学习算法中,会选择Standardization来进行特征缩放,但是,Min-Max Scaling也并非会被弃置一地。在数字图像处理中,像素强度通常就会被量化到[0,1]区间,在一般的神经网络算法中,也会要求特征被量化[0,1]区间。
进行了特征缩放以后,代价函数的轮廓会是“偏圆”的,梯度下降过程更加笔直,收敛更快性能因此也得到提升:

普通数据标准化
Batch Normalization, 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法. 在之前 Normalization 的简介视频中我们一提到, 具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律.
每层都做标准化

在神经网络中, 数据分布对训练会产生影响. 比如某个神经元 x 的值为1, 某个 Weights 的初始值为 0.1, 这样后一层神经元计算结果就是 Wx = 0.1; 又或者 x = 20, 这样 Wx 的结果就为 2. 现在还不能看出什么问题, 但是, 当我们加上一层激励函数, 激活这个 Wx 值的时候, 问题就来了. 如果使用 像 tanh 的激励函数, Wx 的激活值就变成了 ~0.1 和 ~1, 接近于 1 的部已经处在了 激励函数的饱和阶段, 也就是如果 x 无论再怎么扩大, tanh 激励函数输出值也还是 接近1. 换句话说, 神经网络在初始阶段已经不对那些比较大的 x 特征范围 敏感了. 这样很糟糕, 想象我轻轻拍自己的感觉和重重打自己的感觉居然没什么差别, 这就证明我的感官系统失效了. 当然我们是可以用之前提到的对数据做 normalization 预处理, 使得输入的 x 变化范围不会太大, 让输入值经过激励函数的敏感部分. 但刚刚这个不敏感问题不仅仅发生在神经网络的输入层, 而且在隐藏层中也经常会发生.

只是时候 x 换到了隐藏层当中, 我们能不能对隐藏层的输入结果进行像之前那样的normalization 处理呢? 答案是可以的, 因为大牛们发明了一种技术, 叫做 batch normalization, 正是处理这种情况.
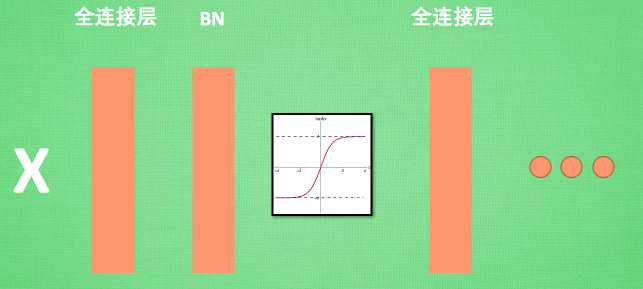
BN 添加位置
Batch normalization 的 batch 是批数据, 把数据分成小批小批进行 stochastic gradient descent. 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行 normalization 的处理,
BN 效果
Batch normalization 也可以被看做一个层面. 在一层层的添加神经网络的时候, 我们先有数据 X, 再添加全连接层, 全连接层的计算结果会经过 激励函数 成为下一层的输入, 接着重复之前的操作. Batch Normalization (BN) 就被添加在每一个全连接和激励函数之间.

之前说过, 计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 normalization, 下者进行了 normalization, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程.

没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值. Batch normalization 不仅仅 normalize 了一下数据, 他还进行了反 normalize 的手续. 为什么要这样呢?
BN 算法

我们引入一些 batch normalization 的公式. 这三步就是我们在刚刚一直说的 normalization 工序, 但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.

最后我们来看看一张神经网络训练到最后, 代表了每层输出值的结果的分布图. 这样我们就能一眼看出 Batch normalization 的功效啦. 让每一层的值在有效的范围内传递下去.
一、BatchNormalization
keras.layers.normalization.BatchNormalization(epsilon=1e-6, weights=None)
将前一层的激活输出按照数据batch进行归一化。
** inputshape: 任意。当把该层作为模型的第一层时,必须使用该参数(是一个整数元组,不包括样本维度)
** outputshape: 同input shape一样。
** 参数**:
epsilon :small float>0,Fuzz parameter。
weights:初始化权值。含有2个numpy arrays的list,其shape是[(input_shape,), (input_shape,)]