之前看到防止过拟合的方法有dropout,L2正则化和Batch Normalization等,自己对前两种比较容易理解,而Batch Normalization为什么可以防止过拟合不太容易理解,于是上网查了一下资料,结合自己的想法总结一下。
BN会使参数搜索问题变得更加容易,使神经网络对超参数的选择更加稳定,超参数的范围会变得庞大,工作效果也很好,容易训练深层网络。
首先,BN提出来是为了解决internal covariate shift的(随着神经网络层数的增加,使得每一层的输入的分布在训练过程中发生很大变化,所以我们需要使数据改变分布),而BN就是在神经网络的训练过程中对每层的输入数据加一个标准化处理。
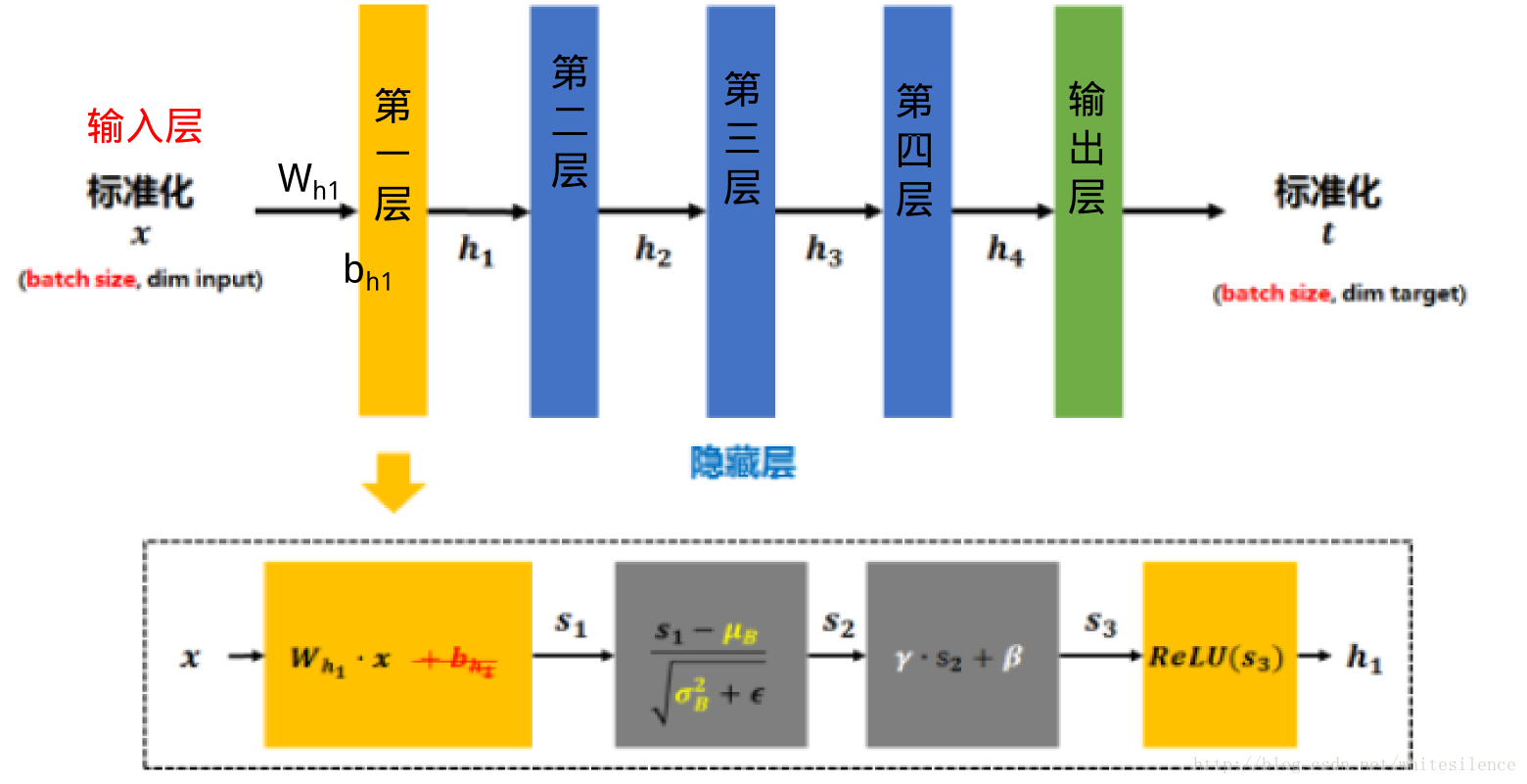
具体过程就是对网络所有卷积层的激活值进行批归一化处理,然后利用可学习的重构参数对归一化后的数据进行还原,最后对重构参数进行训练
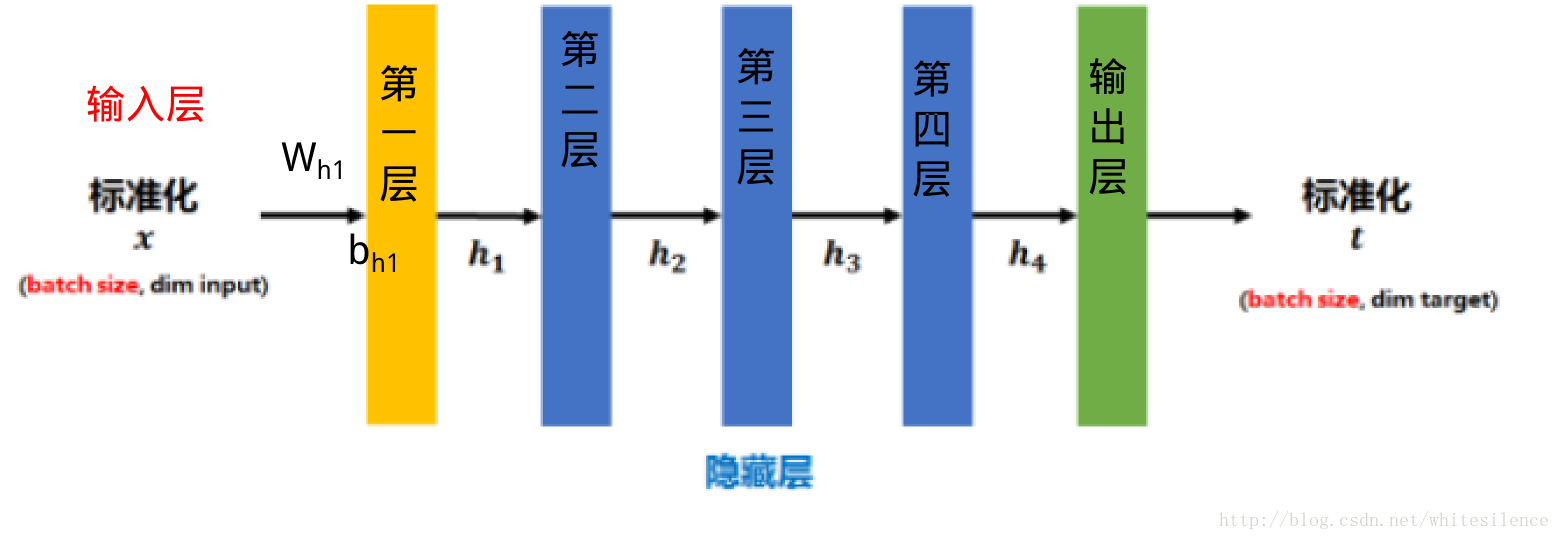
传统的神经网络,只是在将样本xx输入输入层之前对xx进行标准化处理(减均值,除标准差),以降低样本间的差异性。BN是在此基础上,不仅仅只对输入层的输入数据xx进行标准化,还对每个隐藏层的输入进行标准化。
Batch Normalization 限制了在前层的参数的更新,减少了输入值改变的问题,使输出值更加稳定,因此有轻微的正则化的效果。
Batch Normalization给隐藏层增加了噪音,有一定的正则化效果。

参考链接:
https://www.zhihu.com/question/275788133/answer/391635180
https://blog.csdn.net/whitesilence/article/details/75667002
https://blog.csdn.net/whitesilence/article/details/75667002