一、BN, LN等一系列Normalization方法的动机
- 因为一个网络中某层的参数的梯度,最终是由训练样本中这层输入的各个feature的具体数值决定的,如果feature的数值变化范围过大(比如不同特征的含义就导致了取值范围不在一个数量级),就会导致网络中梯度的取值范围很大,会有梯度爆炸和梯度消失,以及网络不稳定的问题。而且梯度的取值范围很大也会导致loss的震荡。因为当梯度的取值范围很大时,由于梯度是一个向量,那么梯度的方向和大小变化范围都会很大,可以理解为一会让loss下降路线往右走,一会又往左走,导致loss在训练过程中出现震荡。
- 缓解梯度消失问题,因为梯度爆炸问题一般通过梯度裁剪就可以较好的解决,所以很多时候还是围绕更难解决的梯度消失来阐述,所以更容易出现梯度消失。不用BN使得梯度消失出现的原因就是:分布不稳定,出现极端情况,例如前几层输入的均值非常大,有可能会导致nn的蝴蝶效应,小幅度的变化会因为多层前向传播而产生大幅度的明显变化,即后几层的输入数据变得过大,从而掉进sigmoid或tanh这样的激活函数的饱和区,而sigmoid或tanh的饱和区的梯度是非常小的,即出现梯度消失的问题,从而使得模型的训练过程提前终止,还会出现过拟合问题,因为该神经元的权重无法更新,从而无法学习新的特征,导致网络出现过拟合现象;
- 而且如果某一层激活值的方差过大,那么对于以这个激活值作为输入的下一层来说,它的梯度会变得很大,使得反向传播时的梯度消失或爆炸。通过控制每层激活值的方差,可以减少这种情况的发生,使得反向传播的梯度更加平稳,从而有助于稳定地训练神经网络。
下图即为Normalizaton的一般操作:

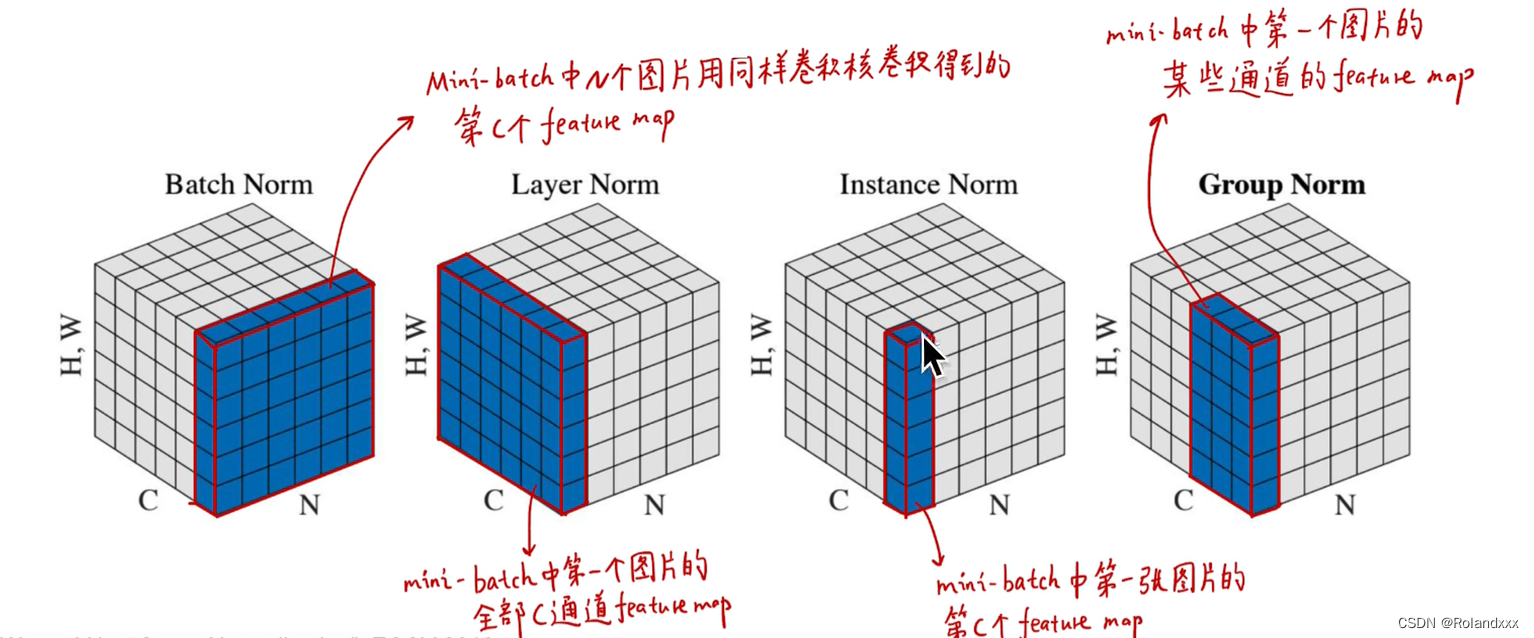
二、Batch Normalization理解:
总结:基于第一节讲到的Normalization能为神经网络带来的种种好处,面临的下一个问题就是针对不同的任务,网络每一层的多维的数据在哪个维度进行Normalization是最合适的,于是就有了Batch Normalization(BN) 。在CV中常常使用BN,因为CV领域的特征更依赖于不同样本间的统计参数。它是在NHW维度进行了归一化,这样归一化抹杀了一个样本内不同特征(通道)之间的大小关系,保留了不同样本间的大小关系。所以总结一下:选择什么样的归一化方式,取决于你关注数据的哪部分信息,当然不能同时对数据既做BN又做LN,比如你先用BN做norm,再用LN做norm的时候会把BN已经norm好的结果破坏掉了。
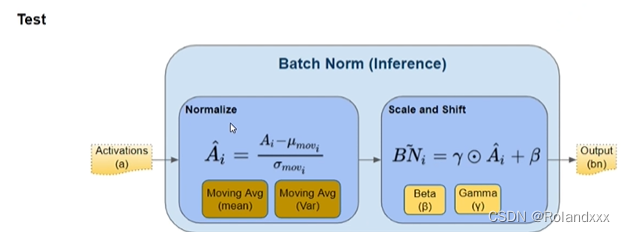
还需注意的是Batch Normalization在训练时和推理时用的参数是不一样的。
训练用的是每个mini-batch训练样本均值和方差,同时还会一直计算Moving Average,Moving Average的初始均值和方差是0和1。
推理用的是所有mini-batches训练样本均值和方差的累计滑动平均结果(Moving Average),推理中的所有参数都是固定住的。

Refer:
Pytorch Batch Normalization 对照原理实践
【炼丹技巧】指数移动平均(EMA)的原理及PyTorch实现
三、其余Normalization
Layer Normalization(批标准化):对一个样本内所有通道的元素进行标准化
Instance Normalization(实例标准化):对一个样本内对每个通道的元素分别进行标准化,即在H*W维度上进行标准化
Group Normalization(组标准化):对一个样本内对几个通道的元素分别进行标准化