在构建模型时,调参是极为重要的一个步骤,因为只有选择最佳的参数才能构建一个最优的模型。但是应该如何确定参数的值呢?所以这里记录一下选择参数的方法,以便后期复习以及分享。
我知道的有两种方法:1、通过经常使用某个模型的经验和高超的数学知识。2、通过交叉验证的方法,逐个来验证。
很显然我是属于后者所以我需要在这里记录一下(如果你属于前者可以教教我)
sklearn的cross_val_score:
我使用是cross_val_score方法,在sklearn中可以使用这个方法。交叉验证的原理不好表述下面随手画了一个图:
有点丑,简单说下,比如上面,我们将数据集分为10折,做一次交叉验证,实际上它是计算了十次,将每一折都当做一次测试集,其余九折当做训练集,这样循环十次。通过传入的模型,训练十次,最后将十次结果求平均值。将每个数据集都算一次
交叉验证优点:
1:交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
2:还可以从有限的数据中获取尽可能多的有效信息。
我们如何利用它来选择参数呢?
我们可以给它加上循环,通过循环不断的改变参数,再利用交叉验证来评估不同参数模型的能力。最终选择能力最优的模型。
下面通过一个简单的实例来说明:(iris鸢尾花)
from sklearn import datasets #自带数据集
from sklearn.model_selection import train_test_split,cross_val_score #划分数据 交叉验证
from sklearn.neighbors import KNeighborsClassifier #一个简单的模型,只有K一个参数,类似K-means
import matplotlib.pyplot as plt
iris = datasets.load_iris() #加载sklearn自带的数据集
X = iris.data #这是数据
y = iris.target #这是每个数据所对应的标签
train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=1/3,random_state=3) #这里划分数据以1/3的来划分 训练集训练结果 测试集测试结果
k_range = range(1,31)
cv_scores = [] #用来放每个模型的结果值
for n in k_range:
knn = KNeighborsClassifier(n) #knn模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GndSearchCV
scores = cross_val_score(knn,train_X,train_y,cv=10,scoring='accuracy') #cv:选择每次测试折数 accuracy:评价指标是准确度,可以不要
cv_scores.append(scores.mean())
plt.plot(k_range,cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy') #通过图像选择最好的参数
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=3) # 选择最优的K=3传入模型
best_knn.fit(train_X,train_y) #训练模型
print(best_knn.score(test_X,test_y)) #看看评分最后得分0.94
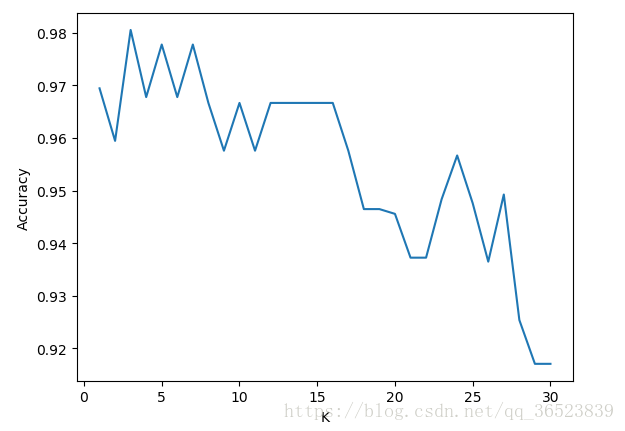
这应该是比较简单的一个例子了,上面的注释也比较清楚,如果我表达不清楚可以问我。
以上都是个人理解,如果有问题还望指出。