sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’)
estimator:数据对象
X:数据
y:预测数据
scoring:调用方法
cv:交叉验证生成器或迭代次数
n_jobs:同时工作的cpu数,-1代表全部
verbose:详细程度
fit_params:传递给估计器的拟合方法的参数
pre_dispatch:控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。
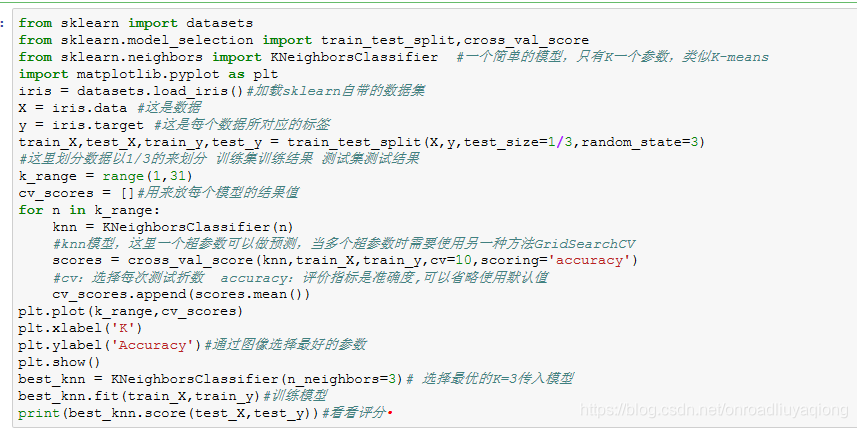
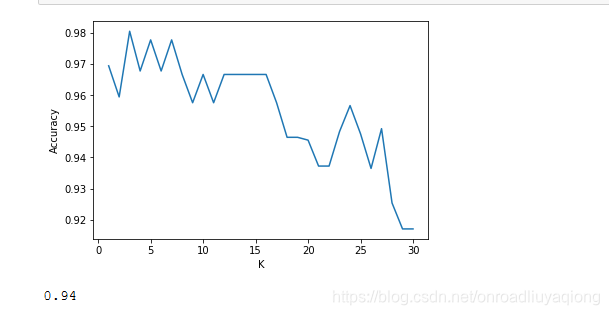
注:train_test_split是数据集按比例划分为测试集与训练集
cross_val_score是将划分的数据集与测试集带入模型交叉验证,可取最优解。
cross_val_score
猜你喜欢
转载自blog.csdn.net/onroadliuyaqiong/article/details/88957867
今日推荐
周排行