在机器学习中,许多算法中多个超参数,超参数的取值不同会导致结果差异很大,如何确定最优的超参数?此时就需要进行交叉验证的方法,sklearn给我们提供了相应的cross_val_score函数,可对数据集进行交叉验证划分。
一、K折交叉验证(Cross-validation)简介
正常情况下,在数据集划分阶段,通常会划分为训练集trainset和测试集testset,在数据集数量足够多的情况下进行划分,效果较好。但是,对于数据集特别少的情况下,直接划分为训练集和测试集进行训练,模型的效果可能不太好,此时便引入了交叉验证。
交叉验证Cross-validation思想很简单,就是对划分好的训练集再进行划分,分为训练集trainset和验证集validset。最终的数据集分为了三类,训练集trainset、验证集validset和测试集testset,通俗的理解为:训练集是学习知识,验证集是月考,测试集是期末考试。
模型在学习了一段知识之后,就定期进行月考试试手,模型训练完成好之后,再通过期末考试检验。就跟上初高中考试的感觉差不多,如果直接上来就是期末考试,谁顶得住啊,所以一般都会进行几次月考,然后查漏补缺,最终迎接期末考试。
举个例子:
原本数据集共1000张,训练集800张,测试集200张
交叉验证就是对那800张训练集再次进行划分,分为600张训练集和200张验证集

二、官网API
官网API
需要导包:from sklearn.model_selection import cross_val_score
这里的参数还是比较多的,具体的参数使用,可以根据官网给的demo进行学习,多动手尝试;这里就以一些常用的参数进行说明。
Cross-validation: evaluating estimator performance
交叉验证:评估评估器(estimator)性能
通过交叉验证评估分数
参数
①estimator
用于拟合数据的对象
也就是模型对象,例如可以是一个线性模型lasso = linear_model.Lasso()
具体官网详情如下:

②X
拟合数据X,可以是列表或数组。
具体官网详情如下:

③y
在监督学习的情况下,要尝试预测的目标变量,也就是自变量Y

具体官网详情如下:

④cv
确定交叉验证分割策略,也就是K折交叉验证中的K值
“None”,默认5倍交叉验证
int,用于指定(分层)KFold 中的折叠数,即K值
具体官网详情如下:

返回值
scores
交叉验证每次运行时估计器的得分数组,cv=k,就会得到k个估计器的得分数组
具体官网详情如下:
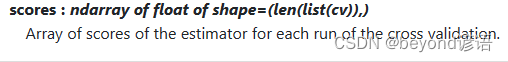
三、代码实现
①导包
若导入过程报错,pip安装即可
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
②加载数据集
数据集可以自己简单整个,csv格式即可,我这里使用的是6个自变量X和1个因变量Y
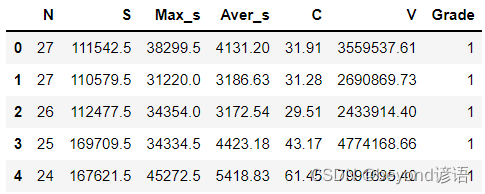
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③创建模型
很多模型都可以的,这里以SVM为例,可参考博文:三、支持向量机算法(SVC,Support Vector Classification)(有监督学习)
svc = SVC(C=3.0,kernel='sigmoid',gamma='auto',random_state=42)
④K折交叉验证
k-fold cross validation,K折交叉验证,将数据集分为k(这里k=3)个大小相似的子集,并将k-1(3-1=2)个子集的并集作为训练集,余下的1个子集作为评估集,由此可得到k(3)个不同的训练/评估集;
k_corss = cross_val_score(svc, X, Y, cv=3)
print(k_corss)
⑤完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)
print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
svc = SVC(C=3.0,kernel='sigmoid',gamma='auto',random_state=42)
k_corss = cross_val_score(svc, X, Y, cv=3)
print(k_corss)