爬取中国基金网数据时中文部分出现乱码
原code如下:
url=r'http://data.chinafund.cn/'
urlString= urlopen(url)
soup= BeautifulSoup(urlString, 'html.parser')
nameList= soup.findAll('div',{'id':'content'}) #print(nameList)
for name in nameList:
nameString= name.getText(',') #get raw data
nameString= nameString.replace('--','0')
#'--' means NA on this website. replaced as '0' to easy the next steps like float()
nameString= nameString.splitlines() # split lines by '\r'(the default method)
#print(nameString)
data=[] #data empty list
for line in nameString:
lines= line.split(',') #split text by ','
data+=[lines[1:5]] # the 2nd, 3rd, 4th, 5th data in each line
colnames=['Date','Symbol','Fundname','NAV'] # assign col names
dataFrame=pd.DataFrame(data,columns=colnames)
dataFrame=dataFrame[4:len(dataFrame)-2] #delete the first 4 lines and the last 2 lines which are invalid
##print(dataFrame)
dataFrame['Symbol']= dataFrame['Symbol'].astype(float) #transfer NAVs to float
dataFrame['NAV']= dataFrame['NAV'].astype(float)
# transfer Symbol to float(I need to do that to remove first few zeroes for easy work)
filePath= ('D:/MS/Allprice.csv') #My filepath
dataFrame.to_csv(filePath,encoding='utf8',index=False) #encoding=utf-8
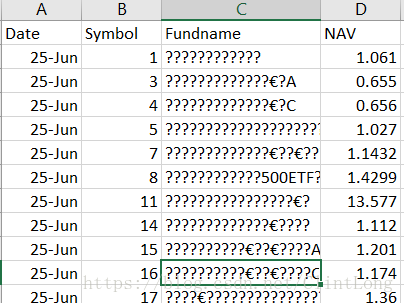
如果使用以上代码,最后column['Fundname']下是乱码,即使我在最后已经使用了 encoding=‘utf8’了。为了解决这个问题,我改变了encoding,最后一行代码变为dataFrame.to_csv(filePath,encoding='utf_8_sig',index=False) 。这样跑出来的数据显示是正常的,而且也可以用作后续的读取与计算。
最后结果:
