今天小编利用美丽的汤来为大家演示一下如何实现京东商品信息的精准匹配~~
HTML
文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;因此可以说Beautiful Soup库是解析、遍历、维护“标签树”的功能库。
如何利用BeautifulSoup抓取京东网商品信息
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用bs4选择器进行下一步的数据采集。
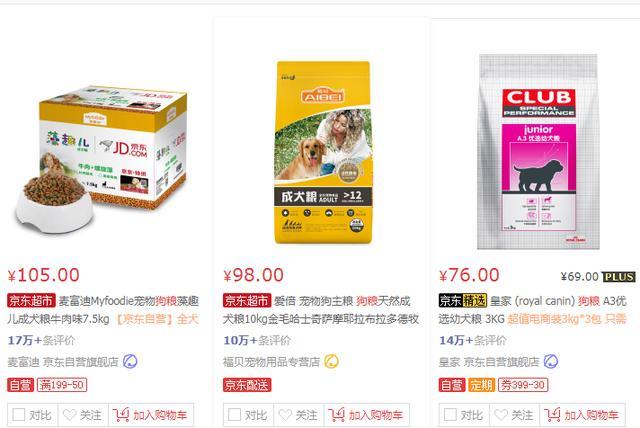
商品信息在京东官网上的部分网页源码如下图所示:

狗粮信息在京东官网上的网页源码
仔细观察源码,可以发现我们所需的目标信息是存在<li data-sku="*****" class="gl-item">标签下的,那么接下来我们就像剥洋葱一样,一层一层的去获取我们想要的信息。
直接上代码,如下图所示:
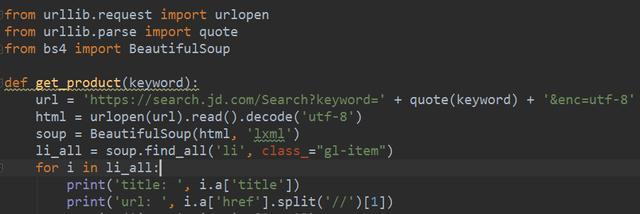
请求网页,获取源码
通常URL编码的方式是把需要编码的字符转化为%xx的形式,一般来说URL的编码是基于UTF-8的,当然也有的于浏览器平台有关。在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
之后利用美丽的汤去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:
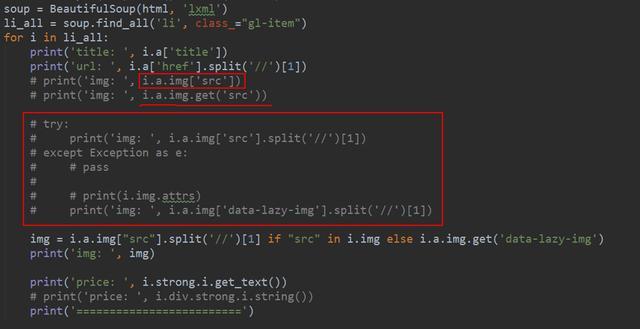
利用美丽的汤去提取目标信息
在本例中,有个地方需要注意,部分图片的链接是空值,所以在提取的时候需要考虑到这个问题。其解决方法有两个,其一是如果使用img['src']会有报错产生,因为匹配不到对应值;但是使用get['src']就不会报错,如果没有匹配到,它会自动返回None。此外也可以利用try+except进行异常处理,如果匹配不到就pass,小伙伴们可以自行测试一下,这个代码测速过程在上图中也有提及哈。使用get方法获取信息,是bs4中的一个小技巧,希望小伙伴们都可以学以致用噢~~~
最后得到的效果图如下所示:
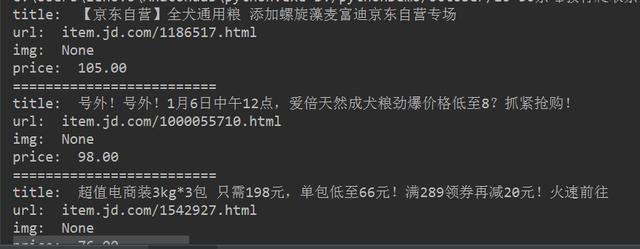
最终效果图
新鲜的狗粮出炉咯~~~
小伙伴们,有没有发现利用BeautifulSoup来获取目标信息比正则表达式要简单一些呢
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。