1. 构造预测函数h(x)
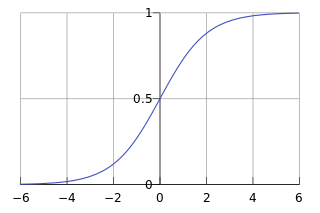
1) Logistic函数(或称为Sigmoid函数),函数形式为: 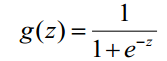
对于线性边界的情况,边界形式如下:
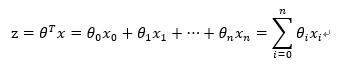
其中,训练数据为向量 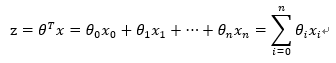
最佳参数

构造预测函数为:

函数h(x)的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1│x;θ)=h_θ (x)
P(y=0│x;θ)=1-h_θ (x)
2.构造损失函数J(m个样本,每个样本具有n个特征)
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
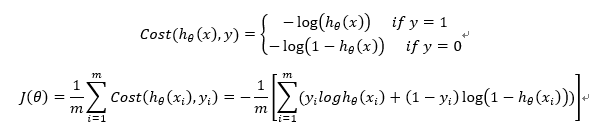
3. 损失函数详细推导过程
1) 求代价函数
概率综合起来写成: 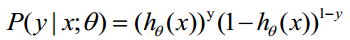
取似然函数为: 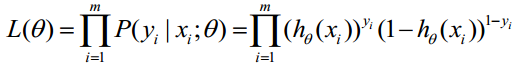
对数似然函数为:
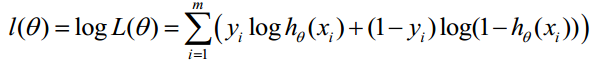
最大似然估计就是求使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。
在Andrew Ng的课程中将J(θ)取为下式,即:
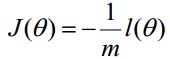
2) 梯度下降法求解最小值
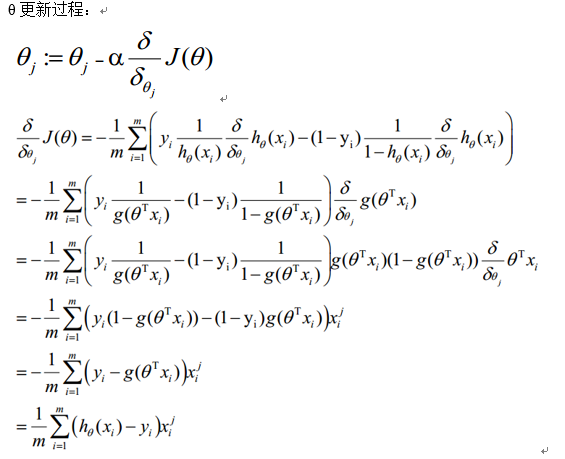
θ更新过程可以写成:
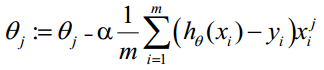
4. 向量化
ectorization是使用矩阵计算来代替for循环,以简化计算过程,提高效率。
向量化过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。
θ更新过程可以改为:
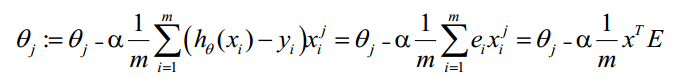
综上所述,Vectorization后θ更新的步骤如下:
- 求 A=x*θ
- 求 E=g(A)-y
- 求
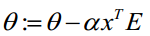
5、Logistic Regression的适用性
1) 可用于概率预测,也可用于分类。
并不是所有的机器学习方法都可以做可能性概率预测(比如SVM就不行,它只能得到1或者-1)。可能性预测的好处是结果又可比性:比如我们得到不同广告被点击的可能性后,就可以展现点击可能性最大的N个。这样以来,哪怕得到的可能性都很高,或者可能性都很低,我们都能取最优的topN。当用于分类问题时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
2) 仅能用于线性问题
只有在feature和target是线性关系时,才能用Logistic Regression(不像SVM那样可以应对非线性问题)。这有两点指导意义,一方面当预先知道模型非线性时,果断不使用Logistic Regression; 另一方面,在使用Logistic Regression时注意选择和target呈线性关系的feature。
3) 各feature之间不需要满足条件独立假设,但各个feature的贡献是独立计算的。
逻辑回归不像朴素贝叶斯一样需要满足条件独立假设(因为它没有求后验概率)。但每个feature的贡献是独立计算的,即LR是不会自动帮你combine 不同的features产生新feature的 (时刻不能抱有这种幻想,那是决策树,LSA, pLSA, LDA或者你自己要干的事情)。举个例子,如果你需要TF*IDF这样的feature,就必须明确的给出来,若仅仅分别给出两维 TF 和 IDF 是不够的,那样只会得到类似 a*TF + b*IDF 的结果,而不会有 c*TF*IDF 的效果。