1. Logistic Regression基本模型
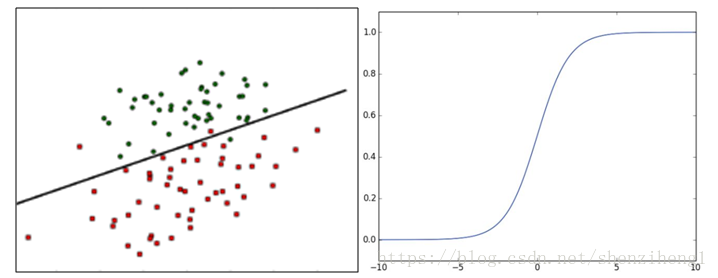
Logistic Regression 模型是广义线性模型中的一种,属于线性分类模型。对于类似上图的分类问题,需要找到一条直线,将两个不同的类区分开。多维情况下,可以利用如下线性函数描述该超平面。
W为权重,b为偏置。多维情况下,两者都是向量。实际应用中,通过对训练样本的学习确定该超平面。其中,我们可以使用阈值函数将样本映射到正负两个类别中。其中,sigmoid函数是最常应用的阈值函数,其函数表达式和导数如下所示。
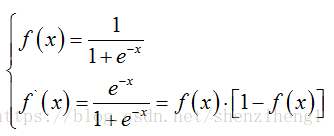
在实际应用中,假设W,b已经利用训练样本得到有效的估计。新样本的类别判别y=0or1如下:
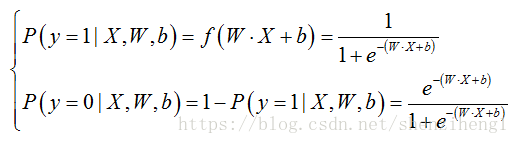
2. 损失函数设计
Logistic Regression分类是典型的监督学习算法。所以,我们常用利用优化算法拟合训练集对参数进行求解。最常用到的优化算法就是梯度下降算法。为了使用优化算法,我们首先应该定义模型的损失函数。
对于LR算法,其属于类别y的概率计算如下:

假设训练集有m个训练样本,我们可以采用最大似然法对参数W,b估计。假设
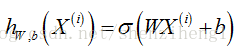
则训练样本集的似然函数为:
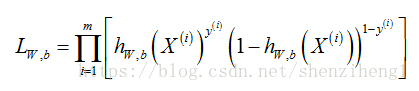
如果训练样本的数量非常庞大,优化连乘很容易造成损失值超过/低于机器精度。因此,通常我们使用“负对数似然函数(Negative Log-Likelihood,NLL)”作为优化的损失函数。那么,函数损失的优化过程就是求NLL的最小值。
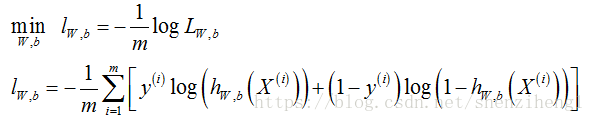
3. 梯度下降算法训练LR模型
梯度下降法的优点在于:求解过程中,只需要求解损失函数的一阶导数,计算成本小。梯度下降法的直观理解:通过当前点的梯度方向寻找到新的迭代点,并从当前点移动到新的迭代点继续寻找新的迭代点(注意梯度下降法通常获得的是局部极小值,改进的随机梯度下降算法获得全局极小值得概率更大)。Gradient Decent算法流程如下:

利用GD训练LR算法的关键在于求参数W,b的梯度方向。我们首先将原始的线性超平面改写成如下形式:
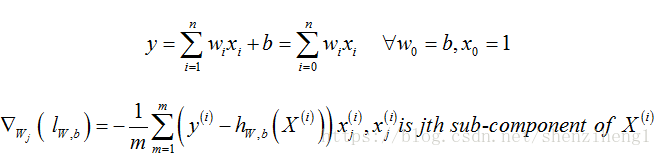
那么,根据GD算法的更新公式, Wj更新公式为:
因此利用上式就可以完成对LR模型的训练。
注意1:关于梯度下降算法中的步长选择问题可以参考一些文献,关键一点,大的步长容易在极值附近出现震荡,小的步长收敛太慢。目前,自适应步长收敛策略还是很不错的
注意2:关于模型过拟合的问题,后面会讨论正则化约束,这里先不涉及