回归算法是一种通过最小化预测值与实际结果值之间的差距,而得到输入特征之间的最佳组合方式的一类算法。对于连续值预测有线性回归等,而对于离散值/类别预测,我们也可以把逻辑回归等也视作回归算法的一种。这次我们来详细了解一下线性回归
1、算法思想
线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。直白的说就是根据一些连续的数据拟合出一条线,通过这条线就可以实现有监督学习的预测。
线性回归分析又分为一元回归和多元回归:
一元回归分析:y=wx+b 可表示为
只有一个自变量和因变量,他们之间呈线性关系(可用一条直线表示)
多元回归分析:
包含两个以上的自变量而且自变量与因变量之间也是线性关系
线性回归分析的值与实际值的距离的平均值,损失函数得到的值越小,损失也就越小,此处损失函数为最小二乘,均方误差形式
有了损失函数既可以就可以使用梯度下降进行求解拟合
梯度下降法:就是最小化损失函数的过程,通过不断调整权重使得损失函数最小达到一个局部最优值。
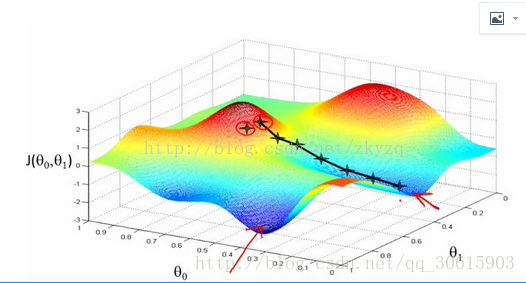
吴恩达网易云课堂上有一个例子很生动的解释了梯度下降,想想我们在山上想要找到一条一条路下山,每次我们都会选择一条斜率最大方向向下走,这个三维空间的斜率就可以理解成我们的梯度,我们每次走的步长就是
也就是所谓的学习率,然后重复选择最大斜率直到我们达到一个局部最优解山脚下。
所以我么就可写出他的梯度更新公式
2、公式推导
线性回归:
假设目标函数:
其中
为误差,是独立相同分布的,服从均值为0方差为
的高斯分布,根据中心极限定理所得
高斯分布的概率密度函数为
可以得出
极大似然函数
然后取对数
因为极大似然函数要极大值所以问题可转化为求
的最小值
所以得出线性回归的损失函数为
3、代码实现
import tensorflow as tf
import numpy
import matplotlib.pyplot as plt
rng = numpy.random
# 设定的超参数
learning_rate = 0.01
training_epochs = 1000
display_step = 50
# 构造一些数据
train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y = numpy.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0]
# tf 计算图的 输入
X = tf.placeholder("float")
Y = tf.placeholder("float")
# 设定模型权重
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
# 构建一个线性回归模型
pred = tf.add(tf.mul(X, W), b)
# 均方误差
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
# 梯度下降
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# 初始化变量
init = tf.initialize_all_variables()
# 在session中启动计算图
with tf.Session() as sess:
sess.run(init)
# 拟合训练数据
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
#每个epoch输出信息
if (epoch+1) % display_step == 0:
c = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print "Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c), \
"W=", sess.run(W), "b=", sess.run(b)
print "Optimization Finished!"
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
print "Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b), '\n'
#Graphic display
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()