自动交叉验证法
from surprise import SVD
from surprise import Dataset
from surprise.model_selection import cross_validate
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
algo = SVD() #使用SVD算法
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True) #采用5折交叉验证并打印结果结果如下:
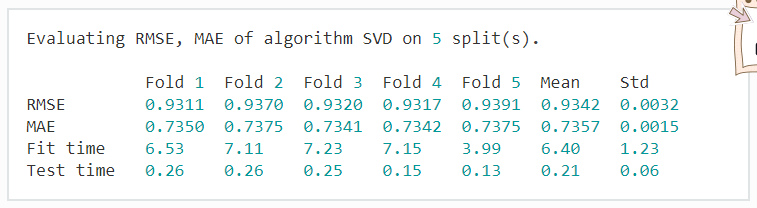
load_builtin()方法将提供下载movielens-100k数据集(如果尚未下载),并将其保存.surprise_data在主目录中的文件夹中(也可以选择将其保存在其他地方)。
我们在这里使用众所周知的 SVD 算法,但还有许多其他算法可用。请参阅 使用预测算法获取更多详细信
该cross_validate() 函数根据cv参数运行交叉验证程序,并计算一些accuracy措施。我们在这里使用经典的5倍交叉验证,但可以使用更漂亮的迭代器(请参见此处)。
Train-test split和fit()方法
如果不想使用完全的交叉验证方法,可以用 train_test_split() 方法来得到给定样本规模的测试集和训练集,并且可以自己选择精度的衡量方法 accuracy metric 。训练的时候使用 fit() 方法作用于训练集,测试的时候使用 test()方法,它将会返回作用于测试集上的预测结果。栗子如下:
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
trainset, testset = train_test_split(data, test_size=.25) #随机抽样选出训练集和测试集,这里选取了25%作为测试集
algo = SVD() #使用SVD算法
algo.fit(trainset) #做训练
predictions = algo.test(testset) #做测试
accuracy.rmse(predictions) #计算RMSE结果是:
RMSE: 0.9411
你也可以用以下一行来完成测试和训练:
predictions = algo.fit(trainset).test(testset)某些情况下,训练集和测试集是给定的,请参阅本节以处理此类情况。
训练整个训练集和预测()方法
显然,我们也可以简单地将我们的算法作用于整个数据集,而不是进行交叉验证。这可以通过使用build_full_trainset()方法建立trainset对象来完成 :
from surprise import KNNBasic
from surprise import Dataset
data = Dataset.load_builtin('ml-100k') #加载movielens-100k数据集
trainset = data.build_full_trainset() #纠正/取出训练集
algo = KNNBasic() #建立算法并训练
algo.fit(trainset) 那么现在就可以使用 predict() 方法来预测评分。假设你对用户id = 192和电影id = 302(要确保他们在训练集中)感兴趣,,并且知道真正的评分是rui=4:
uid = str(196) # 原始user id (在评分文件中的). 注意,是个字符串
iid = str(302) # 原始item id (其他同上)
pred = algo.predict(uid, iid, r_ui=4, verbose=True) #对某一个具体的user和item给出预测运行结果是: