随着信息技术和互联网行业的发展,信息过载成了人们处理信息的挑战。对于用户而言,如何在以指数增长的资源中快速、准确地定位到自己需要的内容是一个非常重要且极具挑战的事情。对于商家而言,如何把恰当的物品及时呈现给用户,从而促进交易量和经济增长,也是一件颇具难度的事情。推荐系统的诞生极大地缓解了这个困难。推荐系统近年来非常流行,应用于各行各业。推荐的对象包括:电影、音乐、新闻、书籍、学术论文、搜索查询、以及其他产品。也有一些推荐系统专门为寻找专家、合作者、笑话、餐厅、美食、金融服务、生命保险、网络交友,以及微信微博页面而设计。
当前推荐系统的两种最流行的方法是协同过滤和基于内容的推荐。 在本文中,我们将重点放在协同过滤的方法上,即:将与当前用户有相似偏好(口味)的其他用户,把他们过去购买过的商品推荐给当前用户, 换句话说,该方法通过使用用户之间的相似性来预测当前用户可能会喜好哪些商品,并将这些商品推荐给当前用户。
我们将使用由Nicolas Hug建立的Surprise库和一个用于开发推荐系统算法的书籍评级数据集Book-Crossing。好了,废话少说,让我们撸起袖子干起来!
数据预处理
首先我们去Book-Crossing网站下载数据,Book-Crossing数据包括三个表,我们将使用其中两个:users表和book rating表。数据下载好以后,开始编写我们的代码,我们先导入需要的包:
import pandas as pd
from surprise import Reader
from surprise import Dataset
from surprise.model_selection import cross_validate
from surprise import NormalPredictor
from surprise import KNNBasic
from surprise import KNNWithMeans
from surprise import KNNWithZScore
from surprise import KNNBaseline
from surprise import SVD
from surprise import BaselineOnly
from surprise import SVDpp
from surprise import NMF
from surprise import SlopeOne
from surprise import CoClustering
from surprise.accuracy import rmse
from surprise import accuracy
from surprise.model_selection import train_test_split我们首先分别查看user表和book-rating表的数据
user = pd.read_csv('./data/BX-CSV/BX-Users.csv', sep=';', error_bad_lines=False, encoding="latin-1")
user.columns = ['userID', 'Location', 'Age']
rating = pd.read_csv('./data/BX-CSV/BX-Book-Ratings.csv', sep=';', error_bad_lines=False, encoding="latin-1")
rating.columns = ['userID', 'ISBN', 'bookRating']
print(len(user))
user.head()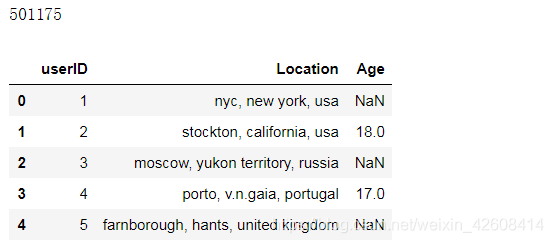
print(len(rating))
rating.head()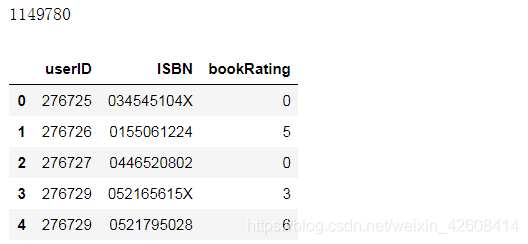
从上面的输出结果可知,用户数量为501175,评级数据量为1149780,接下来我们要做的是数据清洗,我们先将user表和rating表做内连接(inner join)
df = pd.merge(user, rating, on='userID', how='inner')
df.drop(['Location', 'Age'], axis=1, inplace=True)
print(len(df))
df.head()
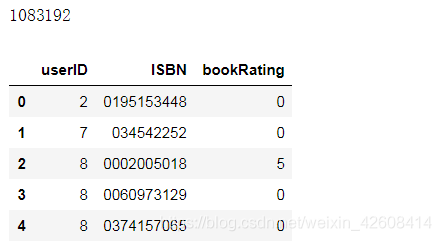
经过内连接以后的数据量为1083192,接下来我们使用直方图来查看bookrating的分布情况
from plotly.offline import init_notebook_mode, plot, iplot
import plotly.graph_objs as go
init_notebook_mode(connected=True)
data = df['bookRating'].value_counts().sort_index(ascending=False)
trace = go.Bar(x = data.index,
text = ['{:.1f} %'.format(val) for val in (data.values / df.shape[0] * 100)],
textposition = 'auto',
textfont = dict(color = '#000000'),
y = data.values,
)
# Create layout
layout = dict(title = 'Distribution Of {} book-ratings'.format(df.shape[0]),
xaxis = dict(title = 'Rating'),
yaxis = dict(title = 'Count'))
# Create plot
fig = go.Figure(data=[trace], layout=layout)
iplot(fig)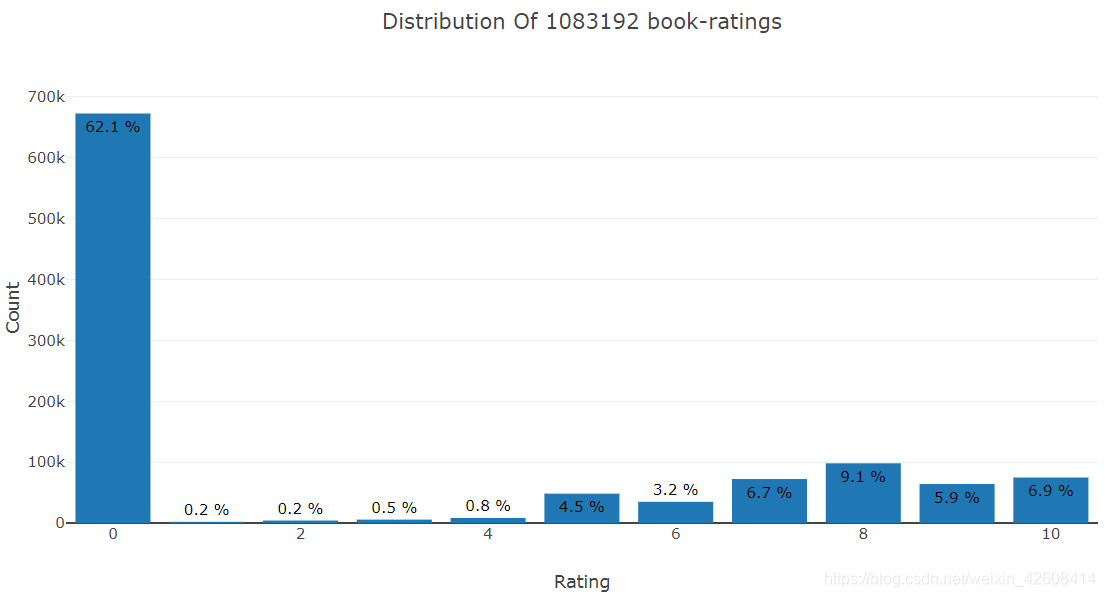
从rating的分布情况来看, 评分为0分的所占比重最高为62.1%,1分,2分,3分所占比重相当低,评分越低的书一定很差,不受欢迎。
接下来我们对书籍ISBN进行分组并查看所有书籍的评分次数的分布情况
# Number of ratings groupy book
data = df.groupby('ISBN')['bookRating'].count().clip(upper=50)
# Create trace
trace = go.Histogram(x = data.values,
name = 'Ratings',
xbins = dict(start = 0,
end = 50,
size = 2))
# Create layout
layout = go.Layout(title = 'Distribution Of Number of Ratings for Books (Clipped at 50)',
xaxis = dict(title = 'Number of Ratings for Books'),
yaxis = dict(title = 'Count'),
bargap = 0.2)
# Create plot
fig = go.Figure(data=[trace], layout=layout)
iplot(fig)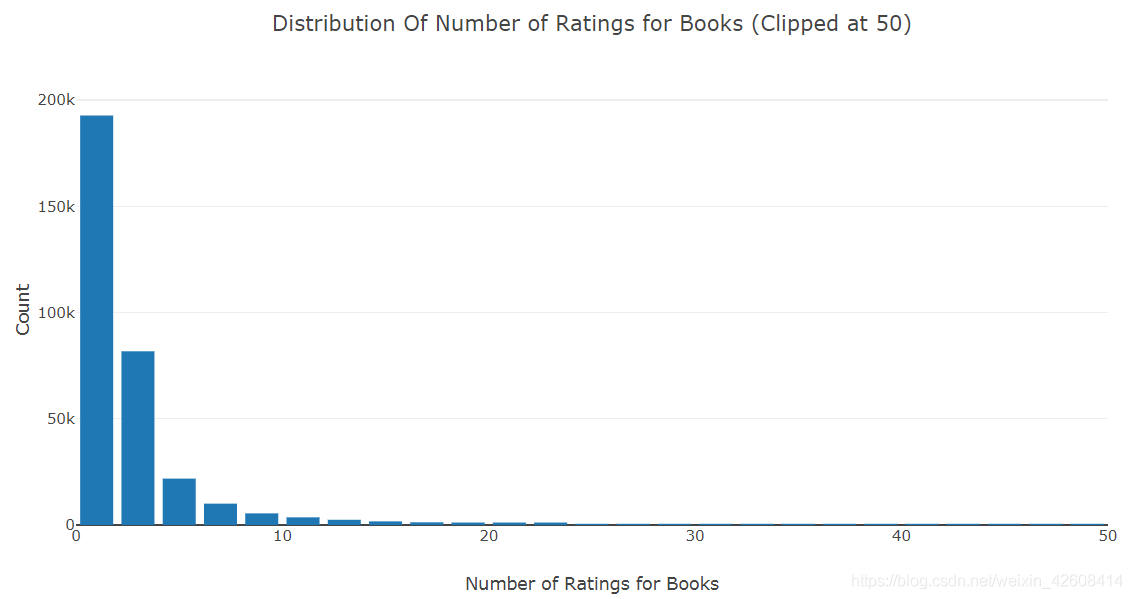
上面的直方图中,x轴表示所有书籍被评分的次数,Y轴表示书籍的数量,从直方图上可知,大部分书籍的评分次数都小于5次,评分次数超过30次的书逐渐减少.我们拦截掉了评分次数超过50次以后的数据。
df.groupby('ISBN')['bookRating'].count().reset_index().sort_values('bookRating', ascending=False)[:10]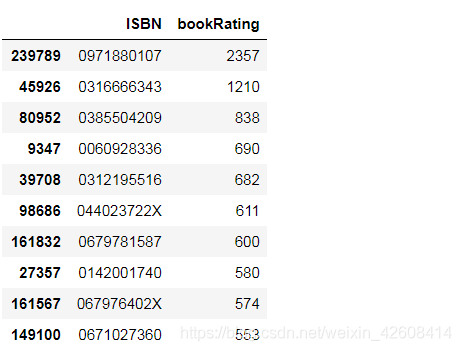
极少数书籍有非常多的评分次数,个别书籍的评分次数达到了2357次,
接下来我们对userID进行分组并查看所有用户的评分次数的分布情况
# Number of ratings per user
data = df.groupby('userID')['bookRating'].count().clip(upper=50)
# Create trace
trace = go.Histogram(x = data.values,
name = 'Ratings',
xbins = dict(start = 0,
end = 50,
size = 2))
# Create layout
layout = go.Layout(title = 'Distribution Of Number of Ratings for Users (Clipped at 50)',
xaxis = dict(title = 'Number of Ratings for Users'),
yaxis = dict(title = 'Count'),
bargap = 0.2)
# Create plot
fig = go.Figure(data=[trace], layout=layout)
iplot(fig)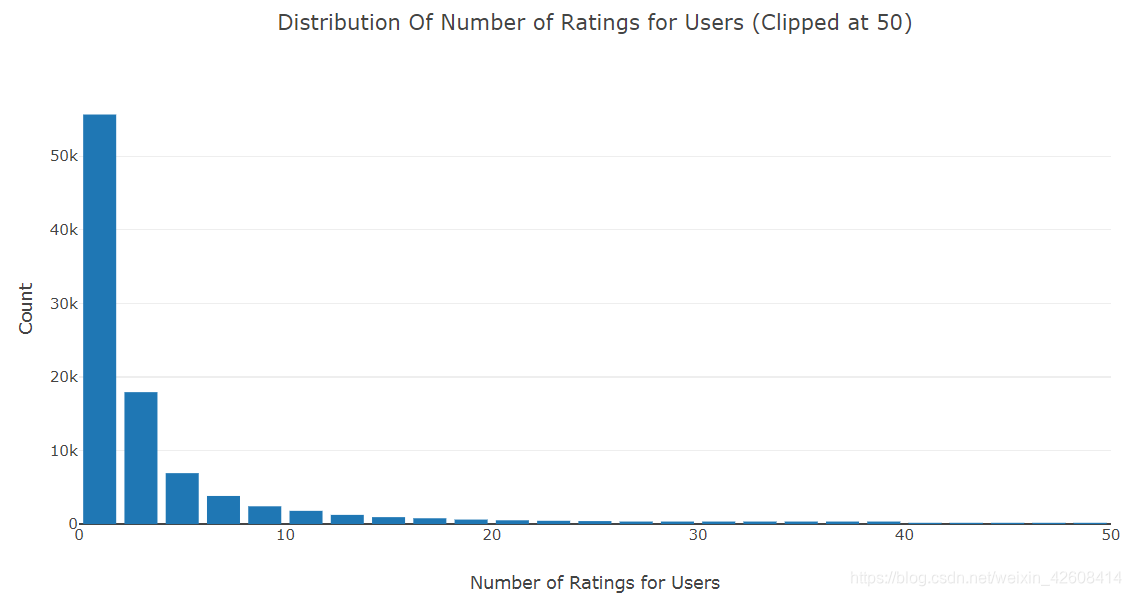
df.groupby('userID')['bookRating'].count().reset_index().sort_values('bookRating', ascending=False)[:10]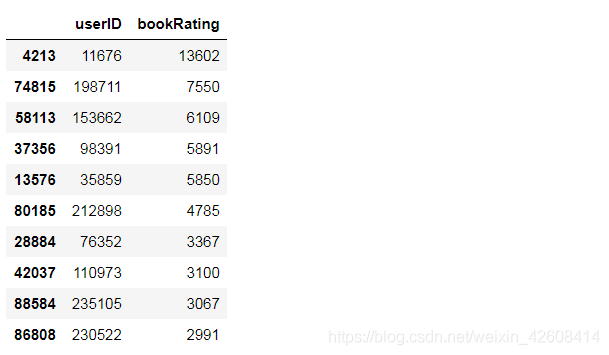
上面的直方图中,x轴表示所有用户的评分的次数,Y轴表示用户的数量。上面的直方图中可以看出,大部分用户的评分次数小于5次,有极少数用户有很高的评分次数,个别用户的评分次数居然高达13602次。
相信大家已经发现,上面的两个直方图呈现相似的分布特性。按书籍分组的评分次数和按用户分组的评分次数都呈现出指数衰减趋势。为了减少计算的复杂度,避免在计算时出现内存泄漏的问题,我们要降低数据的维度,将那些评分次数很低(小于50次)的书籍和用户过滤掉。
min_book_ratings = 50
filter_books = df['ISBN'].value_counts() > min_book_ratings
filter_books = filter_books[filter_books].index.tolist()
min_user_ratings = 50
filter_users = df['userID'].value_counts() > min_user_ratings
filter_users = filter_users[filter_users].index.tolist()
df_new = df[(df['ISBN'].isin(filter_books)) & (df['userID'].isin(filter_users))]
print('The original data frame shape:\t{}'.format(df.shape))
print('The new data frame shape:\t{}'.format(df_new.shape))![]()
经过过滤以后,数据规模由原来的百万级降到了十万级。到此为止数据预处理工作基本完成。
Surprise
我们将使用load_from_df()方法从上面的 pandas dataframe 加载数据,我们还需要一个Reader对象,并且必须指定rating_scale参数。 数据必须有包含3列,对应于userID,ISBN和bookRating,必须严格按照这样的顺序排列。
reader = Reader(rating_scale=(0, 9))
data = Dataset.load_from_df(df_new[['userID', 'ISBN', 'bookRating']], reader)我们使用Surprise库,对以下算法进行测试:
基准算法
基准算法包含两个主要的算法NormalPredictor和BaselineOnly
NormalPredictor
NormalPredictor 从训练集估计得到一个正态分布(均值和标准差),基于该正态分布进行随机预测。
BaselineOnly
BaselineOnly算法预测给定用户和项目的基线估计。
最大近邻算法(KNN)
KNN算法主要包含KNNBasicm,KNNWithMeans,KNNWithZScore,KNNBaseline等算法
KNNBasic
KNNBasic是一种基本协同过滤算法。
KNNWithMeans
KNNWithMeans是基于每个用户的平均评分的基本的协同过滤算法。
KNNWithZScore
KNNWithZScore是基于每个用户的Z分数的基本的协同过滤算法。
KNNBaseline
KNNBaseline是基基准评分的基本的协同过滤算法。
基于矩阵分解的算法
SVD
SVD算法等效于概率矩阵分解
SVDpp
SVDpp算法是SVD的扩展,其考虑了隐式评级。
NMF
NMF是一种基于非负矩阵分解的协同过滤算法。 它与SVD非常相似。
Slope One
Slope One算法是基于不同物品之间的评分差的线性算法,预测用户对物品评分的个性化算法
Co-clustering
Coclustering是一种基于协同聚类的协同过滤算法。
我们使用均方根误差RMSE作为我们预测的评估指标
benchmark = []
# 尝试所有算法
for algorithm in [SVD(), SVDpp(), SlopeOne(), NMF(), NormalPredictor(), KNNBaseline(), KNNBasic(), KNNWithMeans(), KNNWithZScore(), BaselineOnly(), CoClustering()]:
# 在交叉验证集上的表现
results = cross_validate(algorithm, data, measures=['RMSE'], cv=3, verbose=False)
#记录结果
tmp = pd.DataFrame.from_dict(results).mean(axis=0)
tmp = tmp.append(pd.Series([str(algorithm).split(' ')[0].split('.')[-1]], index=['Algorithm']))
benchmark.append(tmp)
surprise_results = pd.DataFrame(benchmark).set_index('Algorithm').sort_values('test_rmse')
surprise_results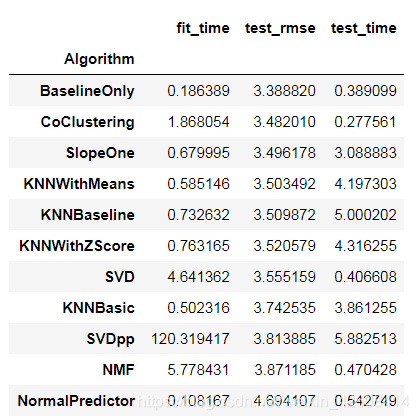
从以上结果看到BaseOnly算法的表现最好,它rmse的误差值最小为3.38,
训练和预测
BaselineOnly算法给了我们最好的rmse,因此,我们将使用BaselineOnly训练和预测,并使用交替最小二乘法(ALS)寻找最优值。
print('Using ALS')
bsl_options = {'method': 'als',
'n_epochs': 5,
'reg_u': 12,
'reg_i': 5
}
algo = BaselineOnly(bsl_options=bsl_options)
cross_validate(algo, data, measures=['RMSE'], cv=3, verbose=False)
我们使用train_test_split()方法创建训练集和测试集,并使用rmse作为评估指标。 然后我们将使用fit()方法在训练集上进行训练,最后使用test()方法将返回测试集上做出的预测结果。
trainset, testset = train_test_split(data, test_size=0.25)
algo = BaselineOnly(bsl_options=bsl_options)
predictions = algo.fit(trainset).test(testset)
accuracy.rmse(predictions)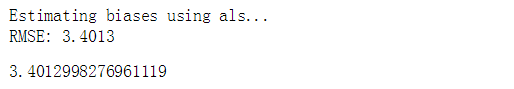
为了详细检查我们的预测,我们将构建一个包含所有预测的pandas的数据集。 以下代码主要来自这个notebook。
def get_Iu(uid):
""" return the number of items rated by given user
args:
uid: the id of the user
returns:
the number of items rated by the user
"""
try:
return len(trainset.ur[trainset.to_inner_uid(uid)])
except ValueError: # user was not part of the trainset
return 0
def get_Ui(iid):
""" return number of users that have rated given item
args:
iid: the raw id of the item
returns:
the number of users that have rated the item.
"""
try:
return len(trainset.ir[trainset.to_inner_iid(iid)])
except ValueError:
return 0
df = pd.DataFrame(predictions, columns=['uid', 'iid', 'rui', 'est', 'details'])
df['Iu'] = df.uid.apply(get_Iu)
df['Ui'] = df.iid.apply(get_Ui)
df['err'] = abs(df.est - df.rui)
best_predictions = df.sort_values(by='err')[:10]
worst_predictions = df.sort_values(by='err')[-10:]最好的预测结果:
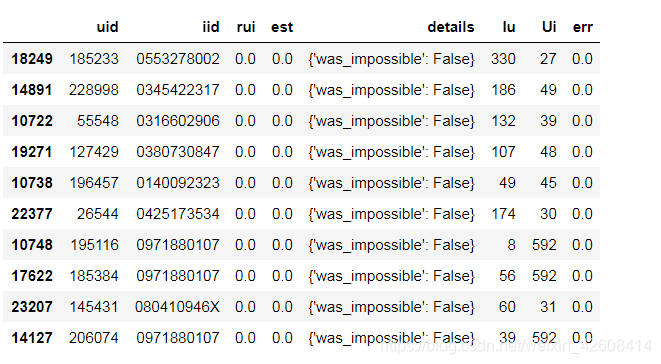
我们来说明一下最好的预测结果,其中uid表示原始数据中userID,iid表示原始数据中的ISBN,rui表示原始数据中的bookRating,est表示预测的评分,detail字段存储有关可能对以后分析有用的预测的其他详细信息,Iu表示物品数量,即当前uid用户评分过的书籍数的量,Ui表示用户数量,即当前iid被多少个用户评分过。err表示误差的绝对值,即|rui-est|,很明显最好的预测结果的误差都是0
最差的预测结果:
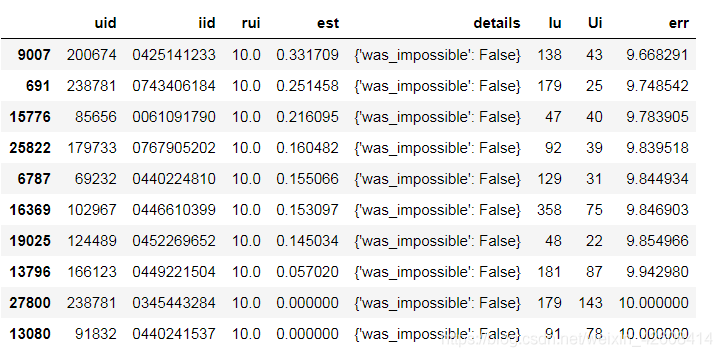
最差的预测结果看上去有点奇怪。 让我们看看最后一个ISBN“0440241537”的更多细节。 该书被78个用户评分过,用户“91832”评分为10,而我们的BaselineOnly算法预测该用户将评分为0。我们查看一下这本书的实际评分
import matplotlib.pyplot as plt
%matplotlib notebook
df_new.loc[df_new['ISBN'] == '0440241537']['bookRating'].hist()
plt.xlabel('rating')
plt.ylabel('Number of ratings')
plt.title('Number of ratings book ISBN 0440241537 has received')
plt.show();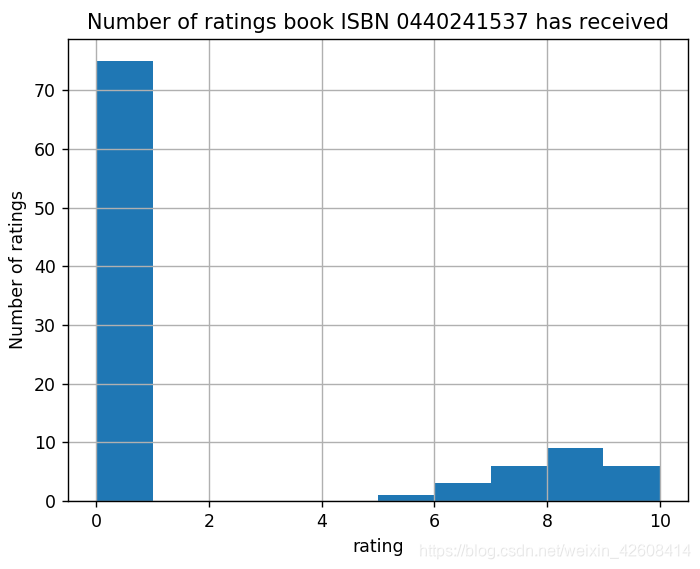
事实证明,0440241537这本书得到的大部分评分都为0,换句话说,数据中的大多数用户将0440241537本书评为0分,只有少数用户评为10。 似乎对于每个预测,都有一些特别列外的用户。