一般地,我们把学习器的实际预测输出与样本之间的真实输出之间的差异称为误差(error),学习器在训练集上的误差称为“训练误差”,在测试集上的误差称为“泛化误差”。显然我们希望得到“泛化误差”小的学习器。通常我们假设测试样本也是从样本真实分布中独立同分布采样而得,需要注意的是,测试集应该尽可能与训练集互斥。数据集划分有以下几种方法:
1.留出法
留出法直接将数据集D划分成两个互斥的数据集 ,其中一个作为训练集S,另一个作为测试集T。
注意:
- 训练/测试集的划分尽可能保持数据分布的一致性,避免因为数据划分过程引入额外的偏差而对最终结果产生影响。比如在2分类任务中,至少要保证样本的类别比例相似。
- 即便给定一个训练/测试集的样本比例后,仍存在很多划分方式对初始数据集D进行分割,这些不同的划分,将会导致不同的训练/测试集,相应的,模型评估的结果也会有差别。因此单次使用留出法得到的估计结果往往是不够稳定可靠的,在使用留出法时,一般采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。例如,进行100次随机划分,每次产生一个训练/测试集用于实验评估,100次后就得到100个结果,而留出法返回的则是100个结果的平均。
方法:surprise.model_selection.split.train_test_split(data, test_size=0.2, train_size=None, random_state=None, shuffle=True)
- data是要划分的数据集,一般是dataframe
- random_state指是否要固定随机数种子
- shuffle指的是是否打乱数据集
注意:其实surprise的这个方法还不算是分层采样,因为这是随机划分的数据集。另外,这个函数是模仿sklearn.model_selection.train_test_split写的,这个函数里面有一个参数是stratify,若设置stratify=y,则按y的比例进行划分数据集,保证分层采样。而surprise里面的这个函数是没有这个参数设置的。
但是,我同时又会在想,推荐系统的数据大部分都是评分数据,不是分类数据,确实没有必要进行分层,所以开发 surprise的这个人丢弃了这个参数的设置???
实例代码:
- 导入surprise的内置的数据集
- 选择合适的推荐系统算法
- 划分训练/测试集
- 在训练集上训练算法,在测试集上测试算法
- 计算均方根误差
import numpy as np
from surprise import SVD
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
data = Dataset.load_builtin('ml-100k')
algo = SVD()
test_result = []
for i in range(10):
trainset,testset = train_test_split(data,test_size=0.25)
algo.fit(trainset)
predictions = algo.test(testset)
test_result.append(accuracy.rmse(predictions))
print("平均结果是{0}".format(np.mean(test_result)))
实例结果:

2.交叉验证法(cross validation)
交叉验证法先将数据集划分D划分为K个大小相似的互斥的子集,每个子集都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后每次用K-1个子集作为训练集,1个作为测试集,这样就可以进行K次训练和测试,最后返回的是K个结果的平均值。
注意:
- 很显然,交叉验证评估结果的稳定性和保真性在很大程度上取决于K的取值,为了强调这一点,我们通常把交叉验证方法叫做“K折交叉验证”。K通常的取值是10,此时称为10折交叉验证,如下图所示:
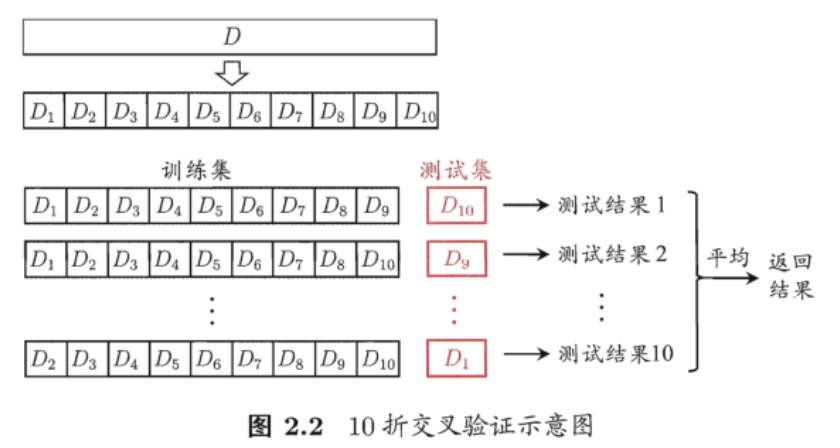
- 与留出法相似,将数据集D划分为K个子集同样存在多种划分方式,为减小因样本划分不同而引入的差别,K折交叉验证通常要随机使用不同的划分方式重复p次,最终的评估结果是这p次K折交叉验证结果的均值,例如,10次10折交叉验证 = 100次训练/测试。
- 假定数据集D中包含m个样本,若令K=m,则得到了交叉验证的特例:留一法(Leave-One-Out,简称LOO)。显然,留一法不受随机样本划分方式的影响,因为m个样本只有唯一的方式划分m个子集——每个子集里面包含一个样本;留一法使得训练集和初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法得到的评估结果往往会被认为比较准确。但是此方法还存在一个重要的缺陷,当数据集的数量比较大时,训练m个模型的计算开销将会是非常的巨大的。
方法:
在surprise.model_selection这个模块里面,存在以下的的交叉验证方法,可供选择与调用。另外它们返回的都是iterators,需要遍历才能得到评价验证结果
- KFold:一个最基本的交叉验证迭代器
surprise.model_selection.split.KFold(n_splits=5, random_state=None, shuffle=True)有内置函数split(data),返回训练集和测试集
- RepeatedKFold:重复KFold多次
surprise.model_selection.split.RepeatedKFold(n_splits=5, n_repeats=10, random_state=None)里面的参数大概的意思是重复10次5折交叉验证
- ShuffleSplit:一个基本的随机划分训练集和测试集的交叉验证迭代器
surprise.model_selection.split.ShuffleSplit(n_splits=5, test_size=0.2, train_size=None, random_state=None, shuffle=True)
其实有点不太懂这里为什么同时拥有n_splits和test_size两个字段???
- LeaveOneOut:在测试集只有一个用户的评分,即前面提到的留一法?
surprise.model_selection.split.LeaveOneOut(n_splits=5, random_state=None, min_n_ratings=0)
其中min_n_ratings的意思时每一个用户在训练集里面的最小的评分数量,如果=2,则表示当用户拥有超过2个评分数量的时候,随机留下一个评分在测试集,其余的都会留在训练集。这个值一般默认是0
- PredefinedKFold:当数据集是用load_from_folds方法导入的时候使用。
实例代码1(三折三次交叉验证)
- 导入surprise的内置的数据集
- 选择合适的推荐系统算法
- 划分训练/测试集
- 在训练集上训练算法,在测试集上测试算法
- 计算均方根误差
from surprise.model_selection import KFold
from surprise import SVD
from surprise import accuracy
from surprise import Dataset
import numpy as np
k1 = 3
k2 = 3
data = Dataset.load_builtin('ml-100k')
algo = SVD()
kf = KFold(n_splits=k1)
test_result_finally = []
for i in range(k2):
test_result = []
for trainset,testset in kf.split(data):
algo.fit(trainset)
predictions = algo.test(testset)
test_result.append(accuracy.rmse(predictions,verbose=True))
print("第{0}次{1}折交叉验证的结果是{2}".format(i+1,k2,np.mean(test_result)))
test_result_finally.append(np.mean(test_result))
print("{0}次{1}折交叉验证的结果是{2}".format(k1,k2,np.mean(test_result_finally)))
实例结果1

实例代码2
基本上KFold、RepeatedKFold、ShuffleSplit、LeaveOneOut这几个函数的使用方法都是如下模式,可以借鉴:
from surprise.model_selection import RepeatedKFold
from surprise import SVD
from surprise import accuracy
from surprise import Dataset
data = Dataset.load_builtin('ml-100k')
kf = RepeatedKFold(n_splits=3,n_repeats=4)
algo = SVD()
for trainset,testset in kf.split(data):
algo.fit(trainset)
predictions = algo.test(testset)
accuracy.rmse(predictions,verbose=True)
实例结果2
