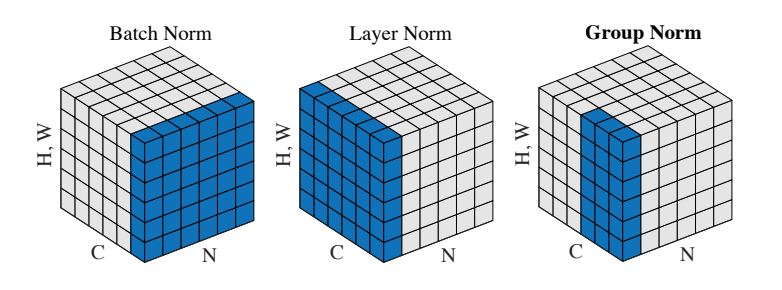
继Batch Normalization,Layer Normalization后又整出了分组归一化(Group Normalization)
作业应该是2018年新出的,答案如下:
将Feature Channel分为G组,按组归一化
def spatial_groupnorm_forward(x, gamma, beta, G, gn_param):
out, cache = None, None
eps = gn_param.get('eps',1e-5)
###########################################################################
# TODO: Implement the forward pass for spatial group normalization. #
# This will be extremely similar to the layer norm implementation. #
# In particular, think about how you could transform the matrix so that #
# the bulk of the code is similar to both train-time batch normalization #
# and layer normalization! #
###########################################################################
N,C,H,W = x.shape
x_group = np.reshape(x, (N, G, C//G, H, W)) #按G将C分组
mean = np.mean(x_group, axis=(2,3,4), keepdims=True) #均值
var = np.var(x_group, axis=(2,3,4), keepdims=True) #方差
x_groupnorm = (x_group-mean)/np.sqrt(var+eps) #归一化
x_norm = np.reshape(x_groupnorm, (N,C,H,W)) #还原维度
out = x_norm*gamma+beta #还原C
cache = (G, x, x_norm, mean, var, beta, gamma, eps)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return out, cache
def spatial_groupnorm_backward(dout, cache):
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for spatial group normalization. #
# This will be extremely similar to the layer norm implementation. #
###########################################################################
N,C,H,W = dout.shape
G, x, x_norm, mean, var, beta, gamma, eps = cache
# dbeta,dgamma
dbeta = np.sum(dout, axis=(0,2,3), keepdims=True)
dgamma = np.sum(dout*x_norm, axis=(0,2,3), keepdims=True)
# 计算dx_group,(N, G, C // G, H, W)
# dx_groupnorm
dx_norm = dout * gamma
dx_groupnorm = dx_norm.reshape((N, G, C // G, H, W))
# dvar
x_group = x.reshape((N, G, C // G, H, W))
dvar = np.sum(dx_groupnorm * -1.0 / 2 * (x_group - mean) / (var + eps) ** (3.0 / 2), axis=(2,3,4), keepdims=True)
# dmean
N_GROUP = C//G*H*W
dmean1 = np.sum(dx_groupnorm * -1.0 / np.sqrt(var + eps), axis=(2,3,4), keepdims=True)
dmean2_var = dvar * -2.0 / N_GROUP * np.sum(x_group - mean, axis=(2,3,4), keepdims=True)
dmean = dmean1 + dmean2_var
# dx_group
dx_group1 = dx_groupnorm * 1.0 / np.sqrt(var + eps)
dx_group2_mean = dmean * 1.0 / N_GROUP
dx_group3_var = dvar * 2.0 / N_GROUP * (x_group - mean)
dx_group = dx_group1 + dx_group2_mean + dx_group3_var
# 还原C得到dx
dx = dx_group.reshape((N, C, H, W))
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbeta Jupyter Notebook 结果(在练习的最后面):
特点
- 和二维的层归一化一样不受batch size影响,论文中和BN的比较图:
