论文链接:https://arxiv.org/abs/1803.08494

提出背景:
Group Normalization(GN)是针对Batch Normalization(BN)在batch size较小时错误率较高而提出的改进算法,因为BN层的计算结果依赖当前batch的数据,当batch size较小时(比如2、4这样),该batch数据的均值和方差的代表性较差,因此对最后的结果影响也较大。
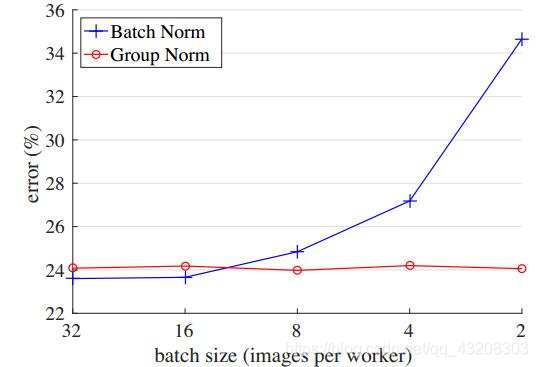
如下图所示,随着batch size越来越小,BN层所计算的统计信息的可靠性越来越差,这样就容易导致最后错误率的上升;而在batch size较大时则没有明显的差别。虽然在分类算法中一般的GPU显存都能cover住较大的batch设置,但是在目标检测、分割以及视频相关的算法中,由于输入图像较大、维度多样以及算法本身原因等,batch size一般都设置比较小,所以GN对于这种类型算法的改进应该比较明显。
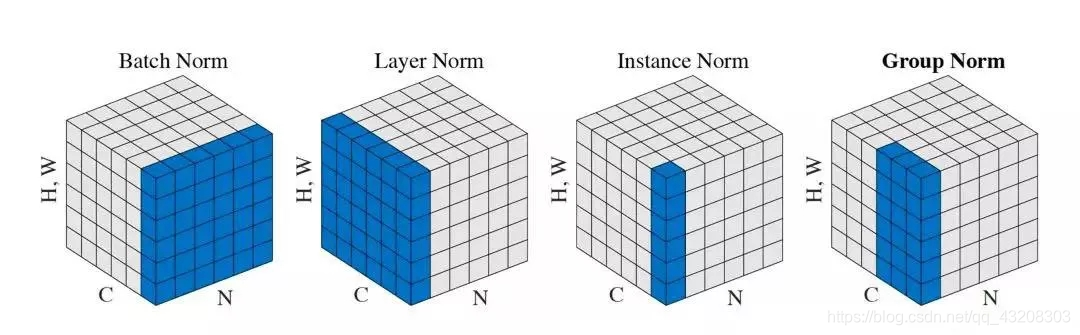
因此Group Normalization(GN)的思想并不复杂,简单讲就是要使归一化操作的计算不依赖batch size的大小,深度网络中的数据维度一般是[N, C, H, W]格式,N是batch size,H/W是feature的高/宽,C是feature的channel,压缩H/W至一个维度,自然想到能否把注意力纬度从batch这一纬转移至chanel这一纬度,Batch归一化有BD、MBGD、SGD,同样G归一化有Layer Normalization、Group Normalization、Instance Normalization,这些均按chanel大小划分,与batch纬无关。
引用论文原文中的话概括:
GN divides the channels into groups and computes within each group the
mean and variance for normalization. GN’s computation is independent
of batch sizes, and its accuracy is stable in a wide range of batch
sizes.
下面着重记录论文第三部分即理论部分,首先来看Figure2中提到的四种归一化方式的公式计算。首先常见的特征归一化算法(BN,LN,IN,GN)基本上都如公式1+公式6所示。公式1是减均值并除以标准差的操作,公式6是一个线性变换,来控制均值和方差让机器自动学习得到最佳的分布组合。


xi中i的含义如论文高亮部分,其实就是四个维度的坐标,这样xi就是feautre map中指定位置的一个点,下图中的k代表在map中索引的下标,S是满足k|条件后要计算均值的点集区域。 
BatchNorm:batch方向做归一化,相同通道的点才参与计算当前点的均值和标准差,假设要计算公式1的点的i.C是3(RGB=B),那么从公式3来看,只有kC=3的点才构成的集合Si才参与计算均值和方差,算NHW的均值(以batch方向,不同的N会相加,自然除以N算均值,下同)
LayerNorm:channel方向做归一化,**LN中Si如公式4所示,换句话说就是相同feature map(N这个维度)**的点才参与计算当前点的均值和标准差,算CHW的均值,(除以C,以channel方向,不同的C会相加,自然除以C算均值)
InstanceNorm:channel内做归一化,IN的Si如公式5所示,换句话说就是相同通道且相同feature map(N这个维度)的点才参与计算当前点的均值和标准差,算H*W的均值
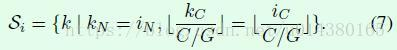
GroupNorm:channel方向分group,然后每个group内做归一化,算(C//G)HW的均值(图1中channel=6,group=2,三个通道为一组求均值)
Experiments:
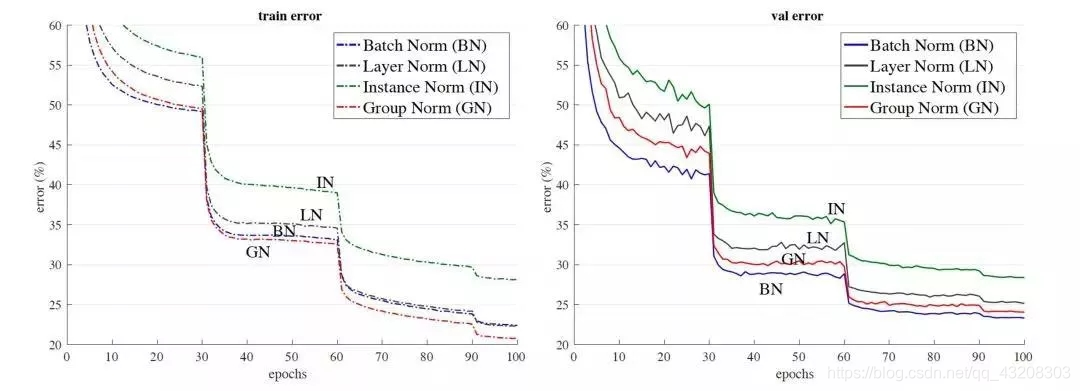
以resnet50为base model,batchsize设置为32在imagenet数据集上的训练误差(左)和测试误差(右)。GN没有表现出很大的优势,在测试误差上稍大于使用BN的结果。
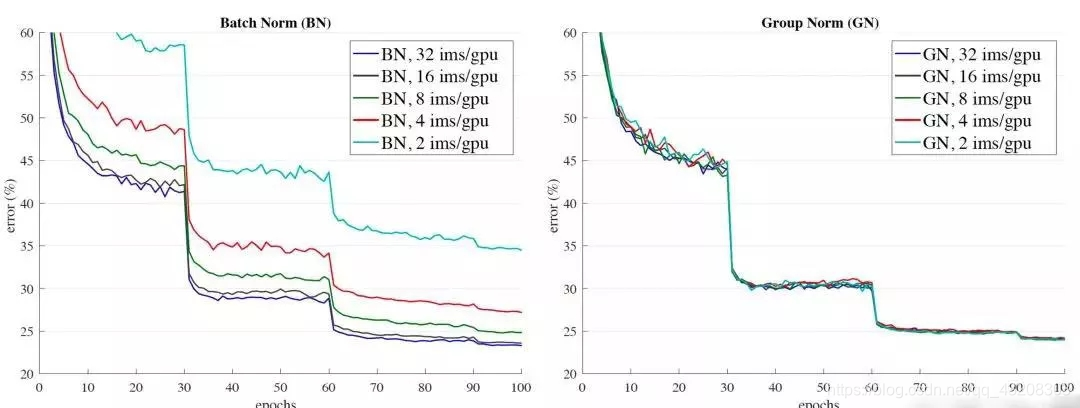
上图是验证batch size大小分别对BN和GN的影响。可以看出GN基本上不受batch size的影响,鲁棒性更强。
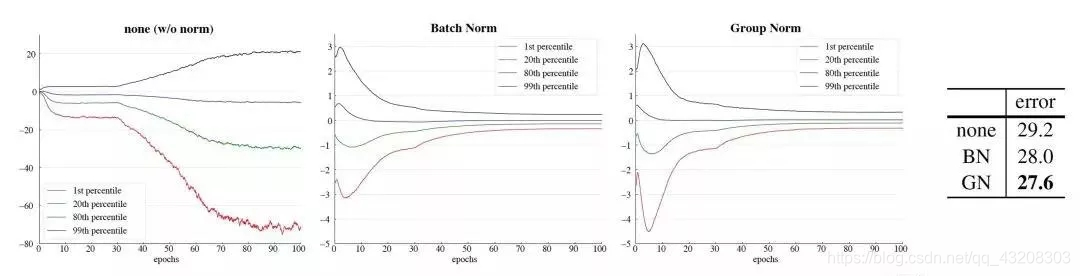
同时,作者以VGG16为例,分析了某一层卷积后的特征分布学习情况,分别根据不使用Norm 和使用BN,GN做了实验,实验结果如上图:统一batch size设置的是32,最左图是不使用norm的conv5的特征学习情况,中间是使用了BN结果,最右是使用了GN的学习情况,相比较不使用norm,使用norm的学习效果显著,而后两者学习情况相似,不过更改小的batch size后,BN是比不上GN的。