2018.6.2
上大学时数据结构肯定学过 哈希,不过很多细节都忘了,惭愧, 最近看 “算法图解”,阅读了一下。还是梳理一下以前所学知识。
如果用专业术语来表达的话, 散列函数就是“将输入映射到数字”。你可能认为散列函数输出的数字没什么规律,但其实散列函数必须满足一些要求。
它必须是一致的。例如,假设你输入apple时得到的是4,那么每次输入apple时,得到的都必须为4。如果不是这样,散列表将毫无用处。
它应将不同的输入映射到不同的数字。例如,如果一个散列函数不管输入是什么都返回1,它就不是好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
散列表是 一种包含额外逻辑的数据结构。数组和链表都被直接映射到内存,但散列表更复杂,它使用散列函数来确定元素的存储位置。
散列表的速度很快!关于数组和链表 你可以立即获取数组中的元素,而散列表也使用数组来存储数据,因此其获取元素的速度与数组一样快。
你可能根本不需要自己去实现散列表,任一优秀的语言都提供了散列表实现。Python/Java/C#等提供的散列表实现为字典 。 C#也还有 Hashtable 类(可以简单理解 泛型和非泛型版本), Hashtable and Dictionary Collection Types 官方有介绍两者区别。 但是没有看到有序无序的问题。 Difference between Hashtable and Dictionary 这里也有详细介绍 。 当我们在“Dictionary”中添加多个条目时,条目的添加顺序将保持不变(有序就是添加顺序)。 当我们从Dictionary中检索所有项时,我们将按照我们插入它们的相同顺序获取记录。 如果我们在Hashtable中添加相同的记录,但是这个顺序不会保留。 可以测试一下。
散列表用途广泛,介绍几个应用案例:
1 将散列表用于查找
2 防止重复
3 将散列表用作缓存(redis/memcache数据库都是作为缓存的!)
冲突
大多数语言都提供了散列表实现,你不用知道如何实现它们。 但你依然需要考虑性能!要明白散列表的性能,你得先搞清楚
什么是冲突。
冲突(collision):给两个键分配的位置相同(映射到同一个数字上了)。
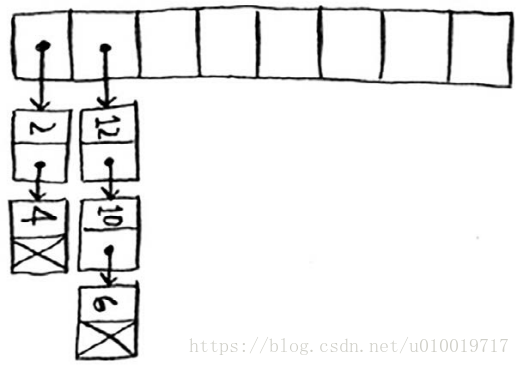
处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。 所谓的 拉链法
下面的两个key :apples, Avocados 都映射到 同一个位置了
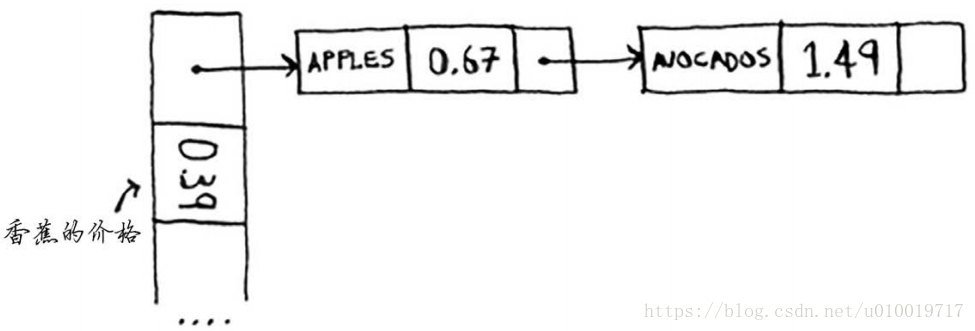
apple和avocado映射到了同一个位置,因此在这个位置存储一个链表。在需要查询香蕉的价格时,速度依然很快。但在需要查询苹果的价格时,速度要慢些:你必须在相应的链表中找到apple。如果这个链表很短,也没什么大不了——只需搜索三四个元素。但是,假设你工作的杂货店只销售名称以字母A打头的商品。
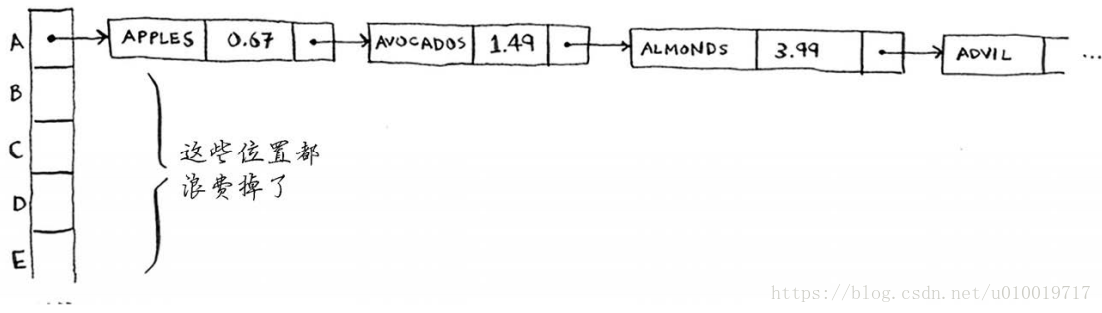
等等!除第一个位置外,整个散列表都是空的,而第一个位置包含一个很长的列表!换言之,这个散列表中的所有元素都在这个链表中,这与一开始就将所有元素存储到一个链表中一样糟糕:散列表的速度会很慢。

这里的经验教训有两个。
散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是,散列函数将键均匀地映射到散列表的不同位置。
如果散列表存储的链表很长,散列表的速度将急剧下降。然而,如果使用的散列函数很好,这些链表就不会很长!散列函数很重要,好的散列函数很少导致冲突。那么,如何选择好的散列函数呢?
要避免冲突,需要有:
较低的填装因子;
良好的散列函数。
1 填装因子

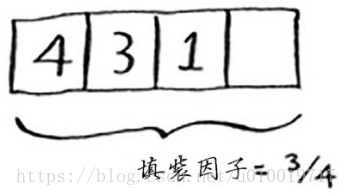
散列表的填装因子很容易计算。散列表使用数组来存储数据,因此你需要计算数组中被占用的位置数。例如,下述散列表的填装因子为2/5,即0.4。

下面这个散列表的填装因子为多少呢?
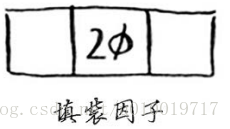
如果你的答案为1/3,那就对了。填装因子度量的是散列表中有多少位置是空的。
假设你要在散列表中存储100种商品的价格,而该散列表包含100个位置。那么在最佳情况下,每个商品都将有自己的位置。
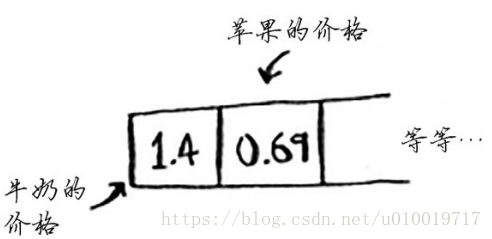
这个散列表的填装因子为1。如果这个散列表只有50个位置呢?填充因子将为2。不可能让每种商品都有自己的位置,因为没有足够的位置!填装因子大于1意味着商品数量超过了数组的位置数。一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度(resizing)。例如,假设有一个像下面这样相当满的散列表。
你就需要调整它的长度。为此,你首先创建一个更长的新数组:通常将数组增长一倍。

接下来,你需要使用函数hash将所有的元素都插入到这个新的散列表中。

这个新散列表的填装因子为3/8,比原来低多了!填装因子越低,发生冲突的可能性越小,散列表的性能越高。一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。你可能在想,调整散列表长度的工作需要很长时间!你说得没错,调整长度的开销很大,因此你不会希望频繁地这样做。但平均而言,即便考虑到调整长度所需的时间,散列表操作所需的时间也为O(1)。
2 良好的散列函数
良好的散列函数让数组中的值呈均匀分布。

糟糕的散列函数让值扎堆,导致大量的冲突。
什么样的散列函数是良好的呢? 如果你好奇,可研究一下SHA函数 。你可将它用作散列函数。
比如在版本控制git中就用到了hash:在git中,文件内容为键值,并用SHA算法作为hash function,将文件内容对应为固定长度的字符串(hash值)。如果文件内容发生变化,那么所对应的字符串就会发生变化。git通过比较较短的hash值,就可以知道文件内容是否发生变动。
再比如计算机的登陆密码,一般是一串字符。然而,为了安全起见,计算机不会直接保存该字符串,而是保存该字符串的hash值(使用MD5、SHA或者其他算法作为hash函数)。当用户下次登陆的时候,输入密码字符串。如果该密码字符串的hash值与保存的hash值一致,那么就认为用户输入了正确的密码。这样,就算黑客闯入了数据库中的密码记录,他能看到的也只是密码的hash值。上面所使用的hash函数有很好的单向性:很难从hash值去推测键值。因此,黑客无法获知用户的密码。
还有两种解决冲突的方法:
a)开放地址法
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,...m-1,称线性探测再散列。
如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
称二次探测再散列。如果di取值可能为伪随机数列。称伪随机探测再散列。仍然以学生排号作为例子,
现有两名同学,李四,吴用。李四与吴用事先已排好序,现新来一名同学,名字叫王五,对它进行编制
| 10.. | .... | 22 | .. | .. | 25 |
| 李四.. | .... | 吴用 | .. | .. | 25 |
| 10.. | .. | 22 | 23 | 25 |
| 李四.. | 吴用 | 王五 |
| 10... | 20 | 22 | .. | 25 |
| 李四.. | 王五 | 吴用 |
| 1... | 10... | 22 | .. | 25 |
| 王五.. | 李四.. | 吴用 |
b)再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止
就这三种方法!
哈希散列方法
1)除留取余法2)平方散列法
3)Fibonacci散列法