哈希是什么
引入:我们在学习数组的时候,使用数组元素的下标值即可访问到该元素,所花费的时间是O(1),与数组元素的个数n没有关系,这就是哈希方法的核心思想。
哈希方法:以关键值K为自变量,通过一定的函数关系h(K)(哈希函数)计算出对应的函数值,把这个值解释为结点的存储地址,将结点的关键码(key)和属性数据(value)一起存入此存储单元中。检索时,用同样的函数计算出地址,找到对应的数据。
哈希表:按哈希存储方式构造的存储结构称为哈希表(hash table)
举例:已知线性表关键码值集合为S={and, begin, do, else, for,golang},假设哈希函数是关键码K的第一个字母在字母表中的序号,哪么可以建立如下的哈希表:
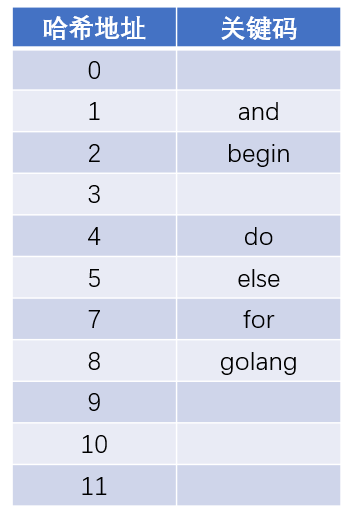
当然这个例子特别简单,细心的同学很快就发现了二个问题:
- 如果S中有类似于and,apple这样的关键码,哪么这个表还怎么存放,在1的位置存放and还是apple呢?(这种现象称为冲突)
- 分配的空间大小比实际所需的要大一点(一般情况下,哈希表的空间(H)比结点的集合(M)大,这样虽然浪费了空间,但是换来了检索效率,称α=M/H为哈希表的负载因子)
其实这就是接下来要谈到的哈希函数的选择和冲突解决策略。
哈希函数
哈希方法的核心就是哈希函数的选择,理想的哈希函数应该使得结点“分布均匀”,且冲突少
为了简单起见,以下的哈希函数我们假设关键值都是整数(如果不是整数,哪也有特定的方法可以把它转换为整数,毕竟在计算机世界里,任何东西都是01组成的串)
除余法:
关键值码k除以M(往往取哈希表的长度),并取余数作为哈希地址。
乘余取整法
先让关键码k乘上一个常数A(0<A<1),提取乘积的小数部分。然后,再用整数n乘以这个值,对结果向下取整,将其作为哈希的地址。
有许多种哈希函数可以选择,每种都有其适用的场景,但是作为软件开发工程师,我们只要理解它的思想就可以,至于什么场景选择什么哈希函数,哪大概率是数学家应该研究的问题。
优秀的哈希函数可以尽可能的避免产生冲突,但是冲突的产生是不可避免地,这就是接下来要谈到的冲突解决策略
冲突解决策略
冲突解决技术可以分为两类,拉链法和开地址法,这两种方法的不同之处在于,拉链法把发生冲突的关键码存储在哈希表主表之外,而开地址法把发生冲突的关键码存储在表中另一个槽内。
拉链法
拉链法的一种简单形式是把哈希表中的每一个槽定义为一个链表的表头,哈希到一个特定槽的所有记录都放到这个槽的链表中。
假设S={and, apple, begin, do, dog, else, for, go, golang},哈希函数还是关键码K的第一个字母在字母表中的序号。哪么可以建立如下的哈希表:

开地址法
开地址法把所有记录直接存储在哈希表中。每个记录关键码K有一个由哈希函数计算出来的基位置,即h(k)。如果要插入一个关键码k,而另一个记录的关键码已经占据了k的基位置(发生冲突)则把k存储在表中的其他地址内,至于其他地址怎么选择,有多种算法,我们以顺序探测法为例。
已知一组关键码为{26,36,41,38,44,15,68,12,06,51,25},哈希表长度L=15,用线性探查法解决冲突构造的哈希表的过程如下:
利用除余数作为哈希函数,假设选择M=13,则散列函数为:h(k)=k%13,按顺序插入各个结点:
h(26)=0, h(36)=10,h(41)=2, h(38)=12, h(44)=5,
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26 | 25 | 41 | 44 | 36 | 38 |
h(15)=0,发生碰撞,因此需要进行探查,按照顺序探测法,显然3为开放的空闲地址,因此可以将其放在3单元。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26 | 25 | 41 | 15 | 44 | 36 | 38 |
68和12也类似,最后的哈希表如下所示:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26 | 25 | 41 | 15 | 68 | 44 | 6 | 36 | 38 | 12 | 51 |
小结
本文简述了哈希表的基本概念和思想,作为软件工程师,掌握这些知识足够我们从事工程开发了,至于一些偏数学方面的知识,比如散列方法的效率分析,以及相关的一些优化,本文就不再讲述。
参考资料:《数据结构与算法》张铭 编著