在学习Java集合HashMap源码时,了解到了HashMap是底层的数据结构是基于哈希表(也叫散列表),意识到以前对于哈希表的学习也是浅尝辄止的,故做了一番功课以后,写下这篇文章。
一. 定义
散列表(Hash table,也叫哈希表),是根据关键码值(Key)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
这样说可能有些抽象,但是别急,我们从哈希表的产生原因慢慢道来。
1.1 如何存储键值对?
我们知道,数组通过下标直接访问一个元素的是非常快速的,专业一点来讲就是时间复杂度只有O(1),其原因是因为数组在计算机内存内存储是直接申请了一块连续的内存,而数组的下标会直接对应一个元素的内存地址,也就是说CPU就可以直接拿到元素地址去访问。
但是有些特殊的需求,比如一个键值对("《新华字典》":"cn-12345")这种形式的数据,如果使用数组这种数据结构,是很难实现物理意义上键和值的映射关系的。
当然你可以使用一维数组强行实现。
// 一维数组强行实现键值对映射,但需要定义自己的分隔符(我们使用 :)
String keyValue = "《新华字典》:cn-12345";
String[] books = new String[10];
books[0] = keyValue;但是像我之前说的,这样就完全抹杀了数组的优越性,我们需要先遍历数组来判断键是否相等,然后取出值。
这时有人想到了,如果发明一种方法,把《新华字典》这个键,以一种形式转化为数组的下标,然后数组对应的位置直接存cn-12345这个值,读的时候就能直接使用数组下标访问了呢!
1.2 哈希算法
于是哈希算法就变成了首选的方式。
哈希算法并不是一个特定的算法而是一类算法的统称。哈希算法也叫散列算法,一般来说满足这样的关系:f(data)=key,输入任意长度的data数据,经过哈希算法处理后输出一个定长的数据key。同时这个过程是不可逆的,无法由key逆推出data。
注意几个关键点:
- 哈希算法可以让任意输入长度的data,经过处理以后得到一个定常的key。
- 哈希算法不可逆,不能由key逆推得到data。
由它的这两个特性,我们可以构造一种哈希函数,把我们需要存储的键值对中的键,通过哈希算法,将键(无论是什么数据形式)映射成为数组的下标。
举个简单的例子:
// 根据哈希值获取数组下标
public int myHash(Object object,int arrLength) {
// 根据数组长度取余,得到的一定是数字下标
return object.hashCode() % arrLength;
}我们知道,java.lang.Object类中的hashCode()方法,就是一个哈希算法函数,所有Java中的对象,都有一个自己的哈希值,你可以选择自己重写类中的hashCode()方法,当然也可以直接使用Object类中的native方法。
不过这都不是我们需要关心的,因为无论是JVM还是我们自己实现的hashCode()方法,都是一个哈希函数,这个函数返回的值就是一个不可逆的key
这时候再回头看我们自己写的函数,就会发现每个对象都能映射成为一个数组下标。
1.3 哈希表
了解了如何映射,我们就能明白哈希表这种结构是如何存储的了。

如上图,现在有一组姓名和电话号码的键值对,通过哈希函数可以将姓名映射为数组下标,而数组对应的位置存储的就是该用户的电话号码。
而哈希表,就是通过哈希函数获得数组存储位置,然后将相应的元素存储的一段连续的内存(数组)。
1.4 哈希冲突
理想情况下,哈希算法可以让所有的键(key)都有唯一的数组下标,但是事实上,没有一种哈希算法能做到这一点,这样就会导致有不同的键(key)映射到同一个数组内的位置,因此就出现了哈希冲突。
哈希冲突的解决方式一般有三种:
- 链地址法(拉链法):将所有哈希地址相等的元素构成一个链表,表头存在哈希表数组中。
- 开放地址法:哈希地址p冲突以后,以p为基地址,使用某种方式获得另一个哈希地址(比如直接找下一个地址)
- 再哈希法:第一种哈希算法得到的地址冲突以后,就换一种哈希方法,得到一个新的地址。
链地址法(Separate chaining)
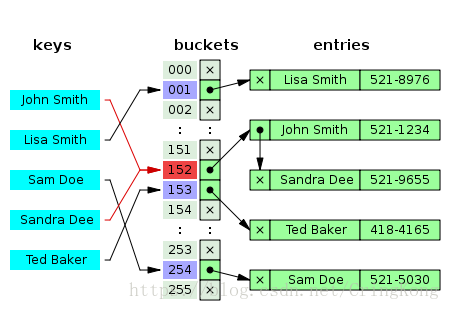
这是链地址法的一种组织形式,哈希表中实际存储的是链表的头节点地址,而发生哈希冲突的键(key)则以链表节点的形式,向后链接下去。

这是链地址法的另一种组织形式,哈希表作为基本表,而哈希冲突的数据作为溢出区的节点,同时作为基本表的后继节点。
开放地址法(Open addressing)

上图是一种最简单的方法,如果哈希地址冲突,就直接用下一个地址,直到找到空的地址。
当然也有其他的方式,但是其核心思想是以一种可逆的方式,获得冲突后的下一个空地址。
再哈希法(rehash)
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。