初入数据结构的哈希表(Hash Table)
这次我们来总结一下关于哈希表的知识,首先我们要了解什么是哈希表,哈希函数的构造思路有哪些?怎么解决哈希冲突?最后再去分析一下哈希查找算法。
- 哈希表的概念
- 前提小知识
- 什么是哈希表?
- 哈希表的四个概念
- 关键字、值、哈希函数、哈希地址、哈希表之间的关系?
- 什么是哈希冲突
- 常见的哈希函数构造方法
- 怎么样才是好的哈希函数?
- 常见构建哈希函数的六个方法
- 直接定值法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
- 随机数法
- 常见解决哈希冲突的四种方法
- 开放定址法
- 再哈希法
- 链地址法(拉链法,位桶法)
- 公共溢出区
- 哈希查找算法分析
哈希表的概念
前提小知识
在实现编程中,常常面临着两个问题:存储和查询。存储和查询的效率往往决定了整个程序的效率。而我们常见存储数据的数据结构比如线性表,树等。数据在结构中的位置都是不明确的,当我们在这些数据结构中要查询一个数据,都避免不了的执行查询算法,去遍历数据结构,拿关键字和结构中的数据一一比较,从而得到想要的数据。整个查询的效率就决定了程序的执行效率,查询效率又依赖查找过程中所进行的比较次数。所以我们就希望能不能不通过比较就能获得我们想要的结果呢?
答案是有的,不经过任何比较,一次存储便能取得所查记录。但这就必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f。使得每个关键字和结构中一个唯一的存储位置相对应。这个关系就是我们所说的哈希函数f(x)。在这个思想上建立起来的表就称为哈希表。
什么是哈希表?
哈希表(Hash Table)又称为散列表。哈希表是一种可以根据以key-value键值对形式存储数据的数据结构,可以通过关键字Key直接找到数据Value的存储位置,而不需要经过任何的遍历和比较。
哈希表中的四个概念?
- 关键字(Key)
(哈希表是通过一个信息来查找另一个信息,将这两个信息在哈希表从形成映射关系,而关键字则是我们要提供的信息) - 值(Value)
(值是我们想要获取到的信息) - 哈希函数
(哈希函数是用来构成哈希表的工具,也是哈希表的核心思想,是关键字和对应数据的存储位置的一个映射关系,通过把关键字代入哈希函数中进行计算,可以得到关键字所对应的数据在哈希表中的存储位置,) - 哈希地址
(哈希地址记录的是我们所需要的数据在哈希表中的存储位置,哈希地址只是表示查找表中的存储位置,不是实际的物理存储位置)
关键字、值、哈希函数、哈希地址、哈希表之间的关系?
哈希表是通过哈希函数来构建的,我们把哈希函数想象成数学中的函数f()。而函数中的X就是关键字Key,既f(x)。然后将关键字带入一个公式中,如f(x) = x * 2 + 3 。然后经过运算就可以求出一个值,这个值表示要查询的数据(Value)在哈希表中的存储位置,也就是哈希地址。而记录这整个Key-Value信息的表就是哈希表。
我们现在把一个抽象的哈希表具体表现成下面的形式,可以说下面就是一个哈希表。我们把它想象成一本电话簿,该电话簿用拼音首字母来区分数据,数据记录了具体的人名和其电话号码。换成哈希表的概念,就是说ABCD是哈希地址,用于记录值所存储的位置。人名为查询关键字(Key)。电话号码是我们需要获得的数据(Value)。
| 哈希地址 | Key and Value |
|---|---|
| A | 艾力 13912345678 |
| B | 包三 15823457890 |
| C | 成五 15823457890 |
| … | … |
| F | 付六 15823457890 |
| G | 高飞 15823457890 |
| … | … |
为了简化流程且易懂,我们这里假设了哈希地址就是关键字的拼音首字母大写,那么哈希函数就是f(艾力)= A,f(包三) = B等…。我们通过将关键字(包三)代入计算公式(哈希函数)中,得到包三的电话号码所在的位置,既哈希地址(B)。那我们就能通过位置直接获得我们想要的数据,而不需要遍历比较。
什么是哈希冲突?
哈希冲突就是key1!=key2.但key1和key2所对应的数据的存储位置都一致,既哈希地址一致。这就是哈希冲突。我们看来下面的哈希表:
| 哈希地址 | Key and Value |
|---|---|
| A | 艾力 13912345678 ;爱丽丝 15823787890 |
| B | 包三 15823457890 |
如上表我们可以看到,艾力和爱丽丝两个人的拼音首字母大写都是A,这就意味着这两个人的电话号码都存储在哈希表(电话簿)的A区,这就存在冲突了。可能有人会说在这个例子中,这在现实意义上,好像也没什么问题,因为很多姓的拼音首字母都可以是A,一个A区的范围很大。但是这仅仅是我们哈希函数设计的太简单,如果我们哈希函数这么设计,我们取关键字拼音首字母对应的ASCII表的值与关键字拼音尾字母在ASCII表的值相乘再除以15取整得到的值作为哈希地址,这似乎就可以在一定程度上减少了哈希冲突的概率。(但实际上这个算法也太简单了)
特性:
通常情况下,可用关键字的集合大于哈希地址集。假设表常为m,则地址最大则是0到n-1。但关键字则可以有很多种可能,比如关键字可以定义为字母为首的8位字母或数字,那么关键字的集合大小为1.2888899*E+14。而表长仅仅1000。地址集合也就0到999。所以这就意味着哈希函数是一个压缩映像,这里的哈希冲突根本无法避免。那我们可以做的只是尽量避免冲突,所以我们可以将冲突的水平平均化,把关键字映射到地址集合中的每个一地址的概率是相等的,也就是我们后面会说到的均匀的哈希函数。
总结
所以在构建哈希表中,最为重要的核心就是哈希函数的设计。哈希冲突是一种想象,只能尽可能减少,是不能完全避免的
常见的哈希函数构造方法(既算法的设计思路)
怎么样才是好的哈希函数?
均匀的哈希函数:
若对于关键字集合中的任一个关键字,经过哈希函数映射到地址集合的任何一个地址的概率都是相等的,则称此类哈希函数为均匀的(Uniform)哈希函数,从而减少哈希冲突。
如何判断一个哈希函数的优劣:
- 能否将关键字均匀影射到哈希空间上
- 有无好的解决冲突的方法,
- 计算哈希函数是否简单高效。
常见构建哈希函数的六个方法
常见的哈希函数的构造思路有六种:
- 直接定值法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
- 随机数法
直接定值法
直接定制法的哈希函数是一个一次函数,取关键字和关机字的某个线性函数值为哈希地址,有如下两种形式:
| 第一种 | 第二种 |
|---|---|
| f ( Key ) = key | f ( key ) = a * key + b |
第一种形式的哈希地址就是Key关键字本身,第二种形式其中a和b是常数,通过关键字与常数的计算获得关键字。这类哈希函数叫做自身函数
举个例子:
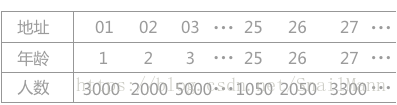
直接定制法的哈希表非常简单。如图上,我们想要查询26岁的人有多少个,我们直接传入关键字26。哈希函数直接就返回哈希地址26,我们直接取哈希表的第26个位置的值既可。以上是第一种形式的范例,第二种也差不多,这里就不举例了。相对来说非常简单。不过在实际的使用中,这类哈希函数的使用情况较少。
数字分析法
如果关键字由多位字符或者数字组成,就可以考虑抽取其中的 2 位或者多位作为该关键字对应的哈希地址,在取法上尽量选择变化较多的位,避免冲突发生。
举个例子:

上图展示出了大概8个关键字,每个关键字都是8位数的十进制数字。经过分析,我们会发现几个特征:
- 第1位和第2位的值都是固定不变。
- 第3位不是3就是4
- 第8位只在2、5、7中徘徊
综上所述,只有中间4位数的值接近随机。所以为了避免冲突,我们从4位接近随机的位数中取任意两位或者取其中两位与另外两位的和,再做舍去进位处理后得到的结果作为哈希地址。
平方取中法
平方取中法是对关键字做平方操作,取中间几位作为哈希地址(此方法是比较常用的构造哈希函数的方法)
例如关键字序列为{421,423,436},对各个关键字进行平方后的结果为{177241,178929,190096},我们则可以取中间的两位{72,89,00}作为其哈希地址。
折叠法
是将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。关键字位数很多,且关键字每一位上数字分布大致均匀时,可以采用折叠法。折叠又可以分为两种:
- 移位折叠
(移动折叠是将分割后的每一部分的最低位对齐,然后想加) - 间界折叠
(间接叠加是从一端向另一端来回折叠,然后相加)
举个例子:
现有图书馆中某藏书的编号为0-442-20586-4,先对其分别采用移位折叠(a)和间界折叠(b)。如下图

(a) 移位折叠将图书编号作为关键字,分割为几个小的部分,然后以最低位对齐,然后相加,再舍去进位,得4位数作为哈希地址
(b) 间界折叠就类似于折纸的步骤。从一端向另一端折叠。同样是分割几个小的部分,然后最低位对齐,相加,舍去进位。与移位折叠不同的是,分割部分的数字序列顺序不同。
除留余数法
若已知整个哈希表的最大长度 m,可以取一个不大于 m 的数 p,然后对该关键字 key 做取余运算,即
f(key) = key % p除留余数法也是最常用,也最简单的哈希函数构造方法。它不仅仅可以直接去模,也可以在折叠,平方取中后再去模。
注意:
除留余数法对p有很高的要求。若p选取的不好,很容易产生同义词。由以往经验可得,p一般取质数或不包含小于20的质因数的合数
随机数法
随机数法既是取关键字的一个随机函数值作为它的哈希地址,适用于关键字长度不一的情况,如
f (key) = random (key)注意:
这里的随机函数其实是伪随机函数,真随机函数是即使每次给定的 key 相同,但是 H(key)都是不同;而伪随机函数正好相反,每个 key 都对应的是固定的 H(key)。
小结:
实际工作中需是不同的情况采用不同的哈希函数。通常,考虑的因素有:
- 计算哈希函数所需要的时间(包括硬件指令的因素)
- 关键字的长度
- 哈希表的大小
- 关键字的分布情况
- 记录的查找频率
常见解决哈希冲突的三种方法
对于哈希表的构建过程中,哈希冲突有时候是无法避免的,所以我们也不能坐以待毙,必须采取适当的措施去处理这些冲突。常见解决冲突的方法有四种:
- 开放定址法
- 再哈希法
- 链地址法(拉链法,位桶法)
- 公共溢出区
开放定址法
H = (f(key) + d) MOD m //我们可以看作f(key) + d
f(key)是哈希函数,m是哈希表的长度,d是一个增量,可有三种取法:
- 线性探测法(线性探测再散列)
d = 1,2,3,4,5…,m-1 - 二次探测法(二次探测再散列)
d=1^2,-1^2,2^2,-2^2…k^2,-k^2(k<=m-1) - 伪随机数探测法(伪随机探测再散列)
d=伪随机序列
现有一个长度为11的哈希表,已填有关键字分别为17,60,29的三条记录。其中采用的哈希函数为f(key)= key MOD 11。现有第四个记录,关键字为38。根据以上哈希算法,得出哈希地址为5,跟关键字60的哈希地址一样,产生了冲突。根据增量d的取法的不同,有一下三种场景:
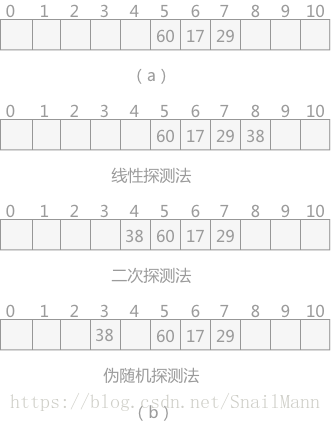
线程探测法:当发生了冲突,若用线性探测法处理的,因为f(key) + d,所以首先5+1=6,得到下一个哈希地址为6,又冲突,依次类推,最后得到空闲的哈希地址8,然后将数据填入哈希地址为8的空闲区域。
二次探测法:若二次探测法处理,首先d = 1^2,所以5+1=6,得到下一个哈希地址为6,发现冲突,所以d=-1^2,所以5+(-1)=4,得下一个哈希地址为4,是空闲区域,所以将数据放入哈希地址为4的空闲区。
伪随机数探测法:随机数法就完全是根据伪随机数列来决定的了,如根据一个随机数种子得到一个伪随机数列为{1,-2,2…k},那么首先地址,第一个得到的地址为6,冲突,第二个得到的地址是3,空闲则存入。
小结:
- 线性探测法对查找不利,但可以保证只要哈希表没填满,就一定能找到一个不发生冲突的位置。
- 二次探测法只要有在哈希表长度m在
4j+3的素数时才能使用(j为整数) - 随机数探测法则取决于伪随机序列
链地址法(拉链法,位桶法)
将产生冲突的关键字的数据存储在冲突哈希地址的一个线性链表中。
例如有一组关键字为{19,14,23,01,68,20,84,27,55,11,10,79},其哈希函数为:f (key)=key MOD 13,使用链地址法所构建的哈希表如图:
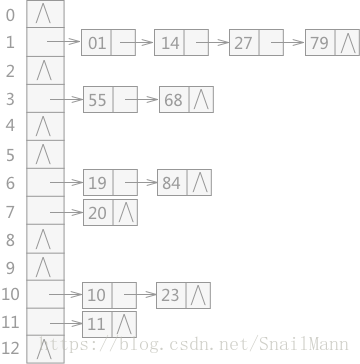
01,14,27,79 Mod 13 的都得1,所以将它们对应的数据都存储在哈希地址为1的一个线性链表中。
再哈希法
如果产生了冲突,则使用另一个哈希函数来计算该关键字的地址,直到不发生冲突。此方法会增加计算时间。
公共溢出区
建立一个公共溢出区也是解决冲突的其中一个方法。基本步骤是通过建立两张表,一张为基本表,另一张为溢出表。基本表存储没有发生冲突的数据,溢出表存放发生冲突的数据。不管关键字通过哈希函数得到的哈希地址是什么,只要发生了冲突,都存放在溢出表。
参考资料
首先声明,在哈希表的学习过程中,主要学习内容是@严长生所讲述,本人在此表示非常之感谢!!
《数据结构》(C语言版) - 作者:@严蔚敏