哈希表简介(Intorduction to Hash Table)
作者:Bluemapleman([email protected])
麻烦不吝star和fork本博文对应的github上的技术博客项目吧!谢谢大家的支持!
知识无价,写作辛苦,欢迎转载,但请注明出处,谢谢!
文章目录
前言:哈希表是最常用的数据结构之一,大部分情况下它的查询性能一般都是O(1)。了解它对于考虑实际项目过程当中应该使用哪种数据结构是非常有必要的。比如在数据库建立索引时,应该选用哈希索引(无序)还是B树索引(有序),就需要参考你的业务对于索引字段的查询要求。比如如果对于索引字段基本都是用于where条件子句中的等值查询,那么哈希一般会性能更好一点;而如果是范围查询,则B树一般会更好一点。
哈希的动机
符号表
哈希表本质上是一个符号表(symbol table)。符号表是一种存储键值对的数据结构并且支持两种操作:将新的键值对插入符号表中(insert);根据给定的键值查找对应的值(search)。符号表中每一个用来放键值对的位置称作一个槽(slot)。Symbol Table(符号表)
键的集合
假定有一个小的可能的键的集合(small universe of keys):
U={0,1,2,…,9}
针对这个键的集合,我们可以考虑用**直接地址表(Direct-address tables)**来存储它们。
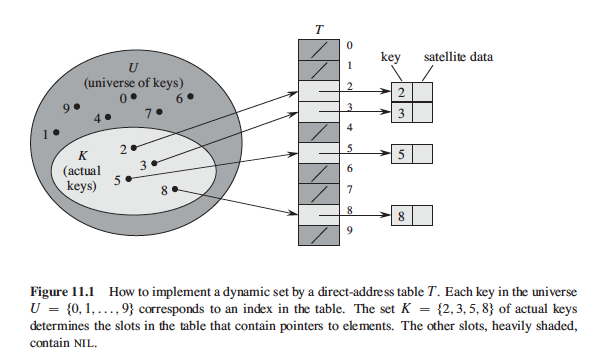
直接地址表的做法是,每个slot直接指向存储的那个唯一的键。而直接地址表的搜索,插入和删除操作显然都是O(1)时间复杂度的。
但是直接地址表的做法的缺陷很明显的,就是若键的集合(所有可能取得值)是非常大的,我们如果要存储这样一个键的集合的时候,就需要相当尺寸的直接地址表,这样对空间的要求是比较高的。
加假如我们所拥有的符号表的尺寸m就是只能远远小于全集的大小的,那么我们可以考虑选择一个**“哈希函数(Hash Function)”:h: U -> {0,1,…,m-1},将所有的键值都映射到我们的符号表中。这种利用哈希函数来对键做映射的符号表,就叫做哈希表(Hash Table)**。
但是因为键的全集的元素数目大于符号表的尺寸m,故肯定有不同的键被映射到同一个符号表的位置中来,这种情况叫做冲突/碰撞(collision)。我们怎么处理冲突的情况呢?一个简单的做法是:用链表做链式哈希(Chaining),即把有冲突的键用链表的形式连接起来,每个键我们用一个链表的节点来存储(node)。
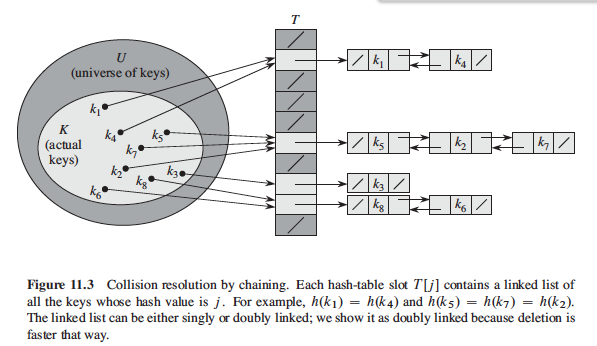
哈希表的操作复杂度分析
查找(Search)
首先我们假设哈希函数h是随机的,即对于任意的键,哈希函数h将该键映射到m个slot中的每个slot里的概率都是相等的,等于1/m。(简单一致哈希假设[Simple Uniform Hashing])
我们还定义一个**负载因子(Load Factor)**的概念, ,n是哈希表中的键的数目。
此时,我们来思考一个问题:含有n个键的尺寸为m的哈希表里,任意slot里的链表的期望长度是多少呢?(多少个键被映射到该slot呢)
答: 由于h是随机的,故每个键分配到每个slot的概率都是相同的,为1/m。故每个槽中的期望的键的数目为n*1/m=n/m,即正好为负载因子 的值。
为什么要考虑slot对应的链表的期望长度呢?因为它和查找操作的时间复杂度是线性相关的。
对于一个目标查找对象x,它的key为 。当我们试图在哈希表中查找它时,首先肯定要对它的键进行哈希,即计算h( ),然后在对应的slot中去找它。但无论对应的slot中是否有x,这个查找操作平均的耗时都是O(1+ ),O(1)是计算哈希值的时间复杂度,O( )是遍历链表的平均时间复杂度。故如若我们能保证哈希表的尺寸m与存储的元素的数目是成一定比例,或者说规模是相当的,那么我们就有n=O(m),那么此时 =n/m,也就是复杂因子就等于O(m)/m=O(1)。那么也就是说,查找操作的平均时间复杂度就是O(1)了!
插入(Insertion)
而哈希表的插入操作也很简单,就是直接将键插入到对应h( )的链表的表头(此处我们假设插入的元素x之前是不存在于哈希表中的),故插入也是O(1)的。
删除(Deletion)
删除操作的时间复杂度要取决于链表是单向链表(Singly linked list)还是双向链表(doubly linked list)。
- 如果是双向链表,由于传入删除操作的参数是元素x本身,故我们可以直接改变一下x元素前后的元素的指针指向即可完成删除,所以是O(1)。
- 而若是单向链表,那么我们首先得用Search()找到元素x的前一个元素,然后再做链表删除。这就是在查找操作上加了一个改变指针指向的操作,故时间复杂度等于 了。
综上所述,如若哈希表的尺寸m足够大,那么查找、插入和删除操作都是可以在O(1)的时间复杂度上完成的。
- 小问题思考
假设有随机一致的哈希函数h,和n个即将存储的键,以及一个尺寸为O(n)的哈希表,那么该哈希表中的最长的链表的期望长度是多少呢?
这个问题等价于往一个有n个槽的盒子里随机抛n个球,问有最多球的槽里面的期望的球的数目是多少。
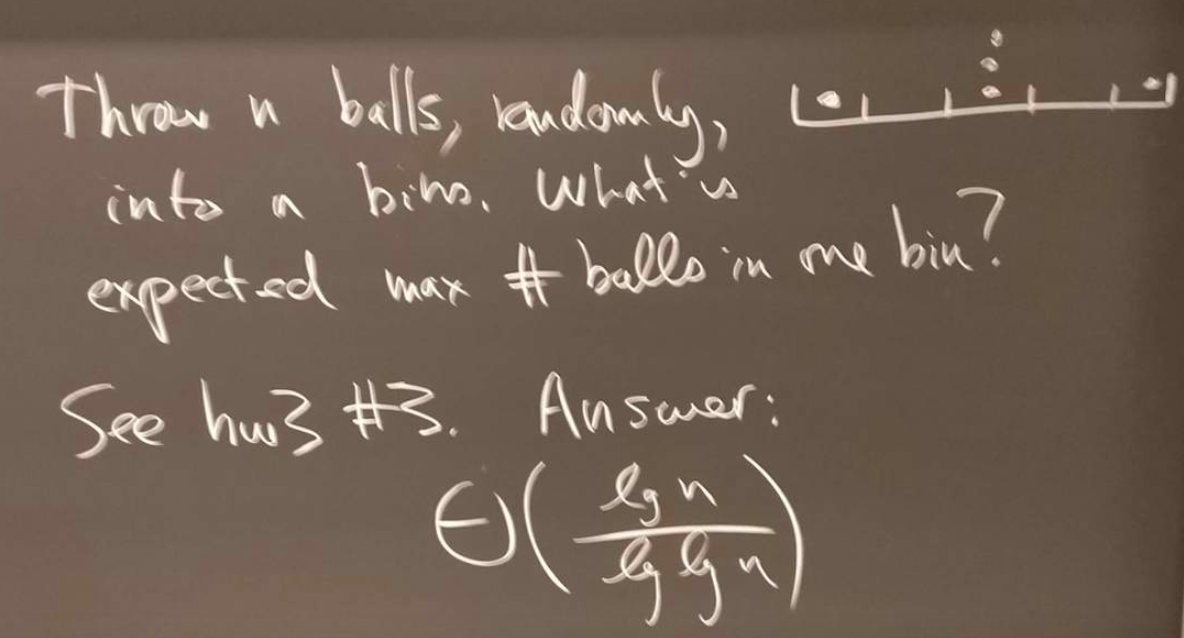
可参考[1]的Page 283的Problem11-2 Slot-size bound for chaining。
现在看来,我们的哈希表的性能主要是受以下几个关键因素的影响的:
- 哈希表尺寸m
- 键集合即键集合的大小n。
- 哈希函数h
哈希函数h的选择
之前我们一直假设哈希函数是随机的。那我们现在来研究一下,为什么要哈希函数随机。
试想极端情况下,如果哈希函数h的输出为一个常数c,即对任意的键,都映射到同一个slot中,那么查找操作的时间复杂度就变成O(n)了,因为要遍历长度为n的链表。
因此,我们之所以希望哈希函数的效果是随机的,就是希望能够将所有的键尽可能均匀地分配到每个slot中,这样才能尽可能保证哈希表的性能。
通常,针对一个简单的键,比如一个字符(本质上也是一个整数),一个整数,我们都可以选择用取余的方式来直接映射它们,即直接用键值除以某个固定参数值的余数,作为该键的哈希值。
但是如果一个键由多个部分组成呢?按理来说,我们计算它的哈希值时应该考虑到它的每个部分。比如像字符串这样的元素,它本质上是字符的一个序列。而我们的一种做法可以是:把字符串的所有字符对应的数值加总,然后取余。但是这种做法的问题是,如果两个字符串含有相同的字符,只是字符的位置不一样的话(互为anagram),也都会映射到相同的slot中,这就很容易导致映射的不够均匀。
而如何解决字符串的映射问题会比较好呢?我们来看看Java中的String的哈希值的计算方法:
可以比较明显地看出,这个哈希值的结果时取决于每个字符在字符串中的位置的,故anagram的情况不一定会映射到同一slot中了。另外使用31作为乘数的主要原因是:使用和哈希表尺寸m互质的数作为乘数可以使得键的映射更均匀,或者说降低冲突率(更细致的解释可以看这篇文章)。
节约内存
我们之前解决冲突的方法一只默认是链式哈希,即用node来存储键,然后用链表的形式把这些node连接起来。这样的做法存在一个问题是,我们需要在哈希表之外,为每个键耗用O(1)的空间,总的来看就是O(n)的额外空间。
那么如果我们想节省一点空间,有没有什么方法呢?或者从本质上来说,除了链式哈希,还有没有别的解决冲突的方法呢?
开放地址法(Open Addressing)
开放地址法的做法是:将键直接存在哈希值对应的slot中。这种做法要求:n<=m, ,一般大概要求为1/2左右。
那么如果用开放地址法,存在冲突时,我们该如何解决呢?答案是探测(Probe)。
具体来说,对于键k1,我们会按照一个探测序列(probe sequence)[h(k1,0),h(k1,1),…,h(k1,m-1)]来探测我们的键可以放入的slot。即如果当前的slot为空,那么就放入我们的键;如果不为空,我们就去查看探测序列中的下一个槽,直到找到空的槽为止。这个顺序取决于探测的方式,如果是线性探测(linear probing),那么这个序列就是[h(k1),h(k1)+1,h(k1)+2,…,h(k1)+m-1]

开放地址法的查找和插入操作都是比较好理解的。查找就是按照探测序列去一个个找就可以,而插入操作也是按照探测序列先查找,找到空的槽插入即可。
但是删除操作就有一个要注意的地方了,就是:如果我们删除了某个探测序列中的某个slot中的键k_del,但是如果该slot对应的下一个探测slot中有键值k_next的话,那么如果我们要查找k_next的话,我们显然会在探测到删除k_del所在的slot时,发现该slot为空,于是停止探测,并认为k_next不存在。下图是一个这样的例子。

解决这个问题有两种方式:
(1)在删除的结点处放一个标志,该标志表示该结点后续仍然有需要探测的slot。
(2)重新对哈希表中的所有键进行哈希。

参考文献
[1] Introduction to Algorithm: Third Edition, Thomas et al.