● 每周一言
对待别人的轻视,最好的回击是站在更高的位置。
导语
上一节讲了如何理解增强学习中的马尔科夫决策过程,并举了具体的例子来描述其求解方法,对算法熟悉的人或许已经看出上节示例中使用的方法是动态规划学习法。那么,除了动态规划法,增强学习的价值学习方法还有哪些?这些方法的不同之处又是什么?
RL价值学习方法
动态规划(Dynamic Programming)是一种解决复杂问题的算法,该算法通过把满足最优子结构的复杂问题分解为子问题,然后逐步求解子问题的方式最终得到整个问题的解。关于DP的讲解可参见小斗之前算法系列的一篇文章 算法基础篇(4)——贪心与动归。

上一节中所讲的“方格世界”,就是一个满足最优子结构的例子,即每一次最优移动都是基于前一次最优移动的基础之上。倘若中间某一次移动并非最优移动,那之后的所有移动都不会是最优移动。
增强学习中的DP价值学习法不需要基于样本学习,而是在已知模型的基础上直接寻找最优策略和最优价值函数,所以DP法可以说是一种基于模型而不基于样本的、比较理想化的价值学习法。

在实际问题当中,通常无法或者很难得到问题的真实模型结构。换言之,便是很难掌握MDP的具体细节,因此DP很难派上用场。不过好消息是,实际问题可以通过样本数据不断地探索试错来优化策略。
这一类优化方法,便是基于样本而不基于模型的价值学习方法,有两个:蒙特卡洛法(Monte-Carlo) 和 时序差分法(Temporal-Difference)。
虽然DP没有实际利用样本数据,由于是从最优子结构逐层完全求解策略与价值函数,因此DP可以用如下示意图作为与MC和TD法的对比。
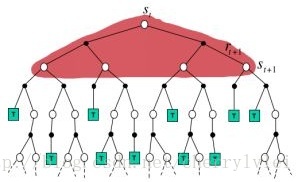
而蒙特卡洛法每次对样本进行完整的采样模拟,用最终的实际价值收获来更新策略和价值函数,MC法的执行步骤示意图如下:
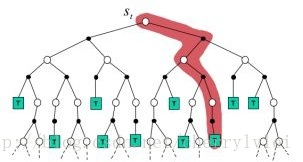
相比于蒙特卡洛法,时序差分法则不需要完整的采样模拟,而是在模拟过程当中动态更新策略和价值函数,TD法的执行步骤示意图如下:
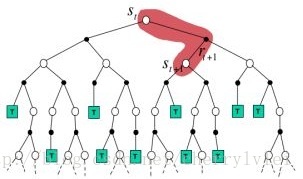
当每次既考虑所有样本,又进行完整的采样模拟时,就变成了暴力搜索,即 穷举法。如果用采样广度表示样本考虑情况,采样深度表示采样模拟情况,则可以用如下表格归纳上述四种方法之间的差别。

以上便是RL价值学习方法的总体介绍,之后会带来MC法和TD法的详细讲解,敬请期待下节内容。
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
