● 每周一言
想工作高效,合作不可或缺。
导语
上一节介绍了PCA降维,PCA是一种无监督降维方法。本节将介绍另外一种常见的有监督降维方法,线性判别分析LDA,以及其具体的算法思想和步骤。
线性判别分析
我们知道,降维的最终目的是一方面能将特征维数大大降低,另一方面则是能够最大程度的保持原样本数据的多样性。

前一节所讲的PCA模型,可以将样本数据投影到方差最大的低维空间中,保证了样本数据的多样性。但是,由于是无监督学习,并未考虑到样本所属的类别,因此会出现不同类别数据在降维之后相互掺杂的情况,从而很难进行后续的分类。
线性判别分析,除了能够最大程度的保持原样本数据的多样性,由于其考虑到了样本的类别标签,还能使降维后的同类别样本距离尽可能小,而不同类别的样本尽可能大。

我们不妨通过一个二分类的例子,来熟悉一下LDA的具体算法思想和步骤,了解其是如何做到降维后还能划分开不同类别样本之间的数据的。
样本xi表示第i个样本的特征向量,yi表示第i个样本的类别标签。在二分类问题中,LDA通过z = ωx把原样本数据映射到一维空间中。

为了描述“同类别样本距离尽可能小,而不同类别的样本尽可能大”这个目标,我们先定义几个变量。根据z = ωx,每一个样本xi都转化成了zi。我们用Xc表示原空间C类别的样本集合,Zc表示降维空间C类别的样本集合。
定义样本集合Xc的均值如下:
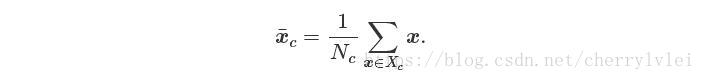
定义样本集合Zc的均值如下:
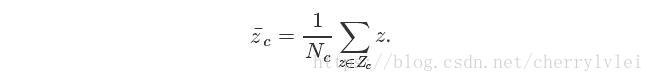
有了上面的公式,我们就能定义同类别样本之间的距离如下:

同样的,也可以定义类别之间的距离如下:
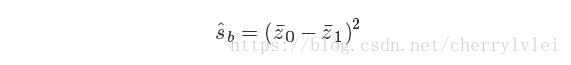
根据上面两个式子,就能定义LDA的目标函数了。LDA的目标就是寻找最大化这个目标函数的ω值,使得“同类别样本距离尽可能小,而不同类别的样本尽可能大”。
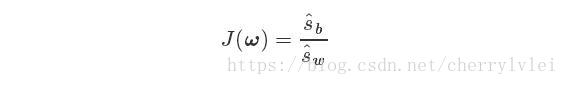
求解这个函数的方法是拉格朗日乘子法,感兴趣的读者可以参考前面我对拉格朗日乘子法的讲解 机器学习方法篇(12)——拉格朗日乘子法,这里不再描述求解的公式推导过程。
以上便是线性判别分析的介绍,敬请期待下节内容。
扫描二维码关注公众号,回复:
1747015 查看本文章

参考:
https://blog.csdn.net/victoriaw/article/details/78213252
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
