欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/136623432
注意力(Attention)机制是大型语言模型中的一个重要组成部分,帮助模型决定在处理信息时,所应该关注的部分。在自然语言处理中,一个序列由一系列的元素组成。注意力机制通过为序列中的每个元素分配一个权重来工作,这个权重反映了每个元素对于任务的重要性。模型会更加关注权重高的元素。自注意力(Self-Attention)是一种特殊的注意力机制,不是将输入序列与输出序列关联起来,而是关注序列内部元素之间的关系。
1. Transformer
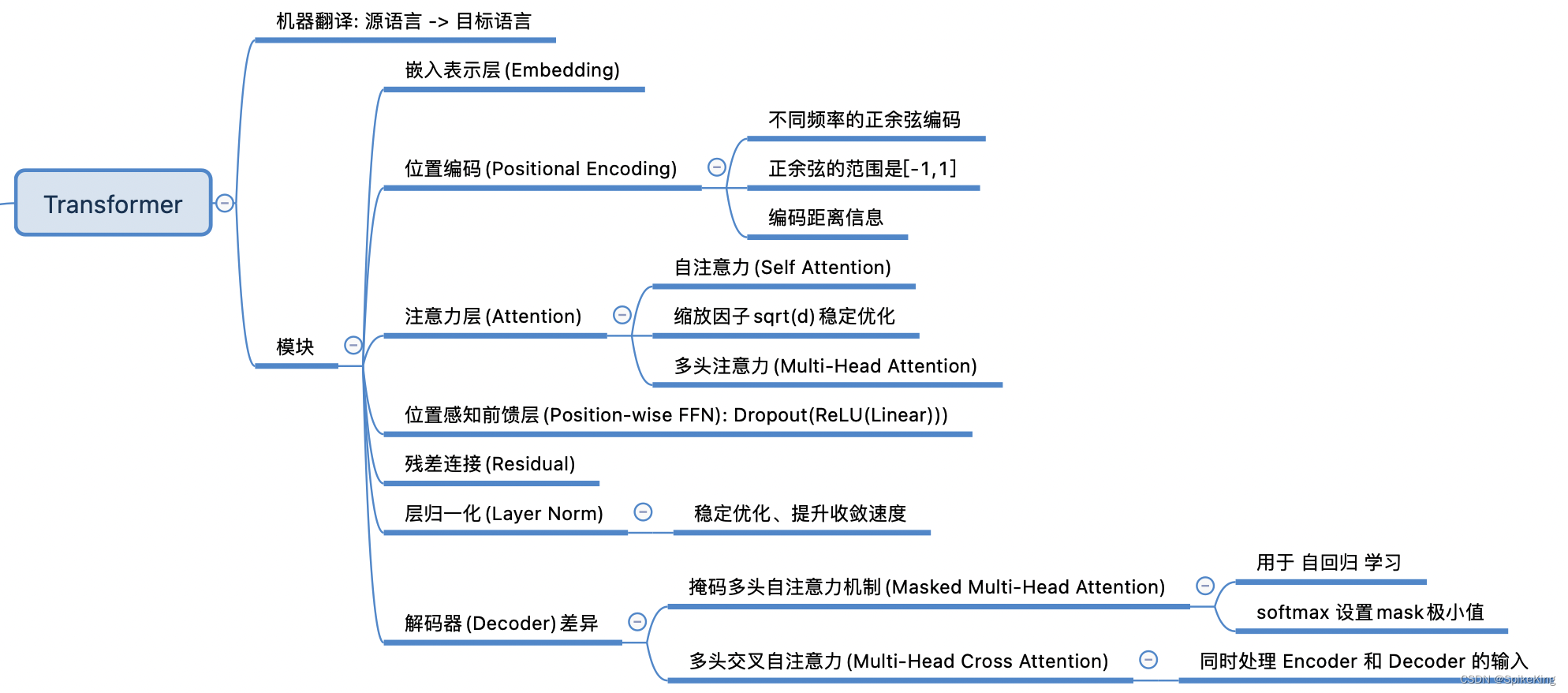
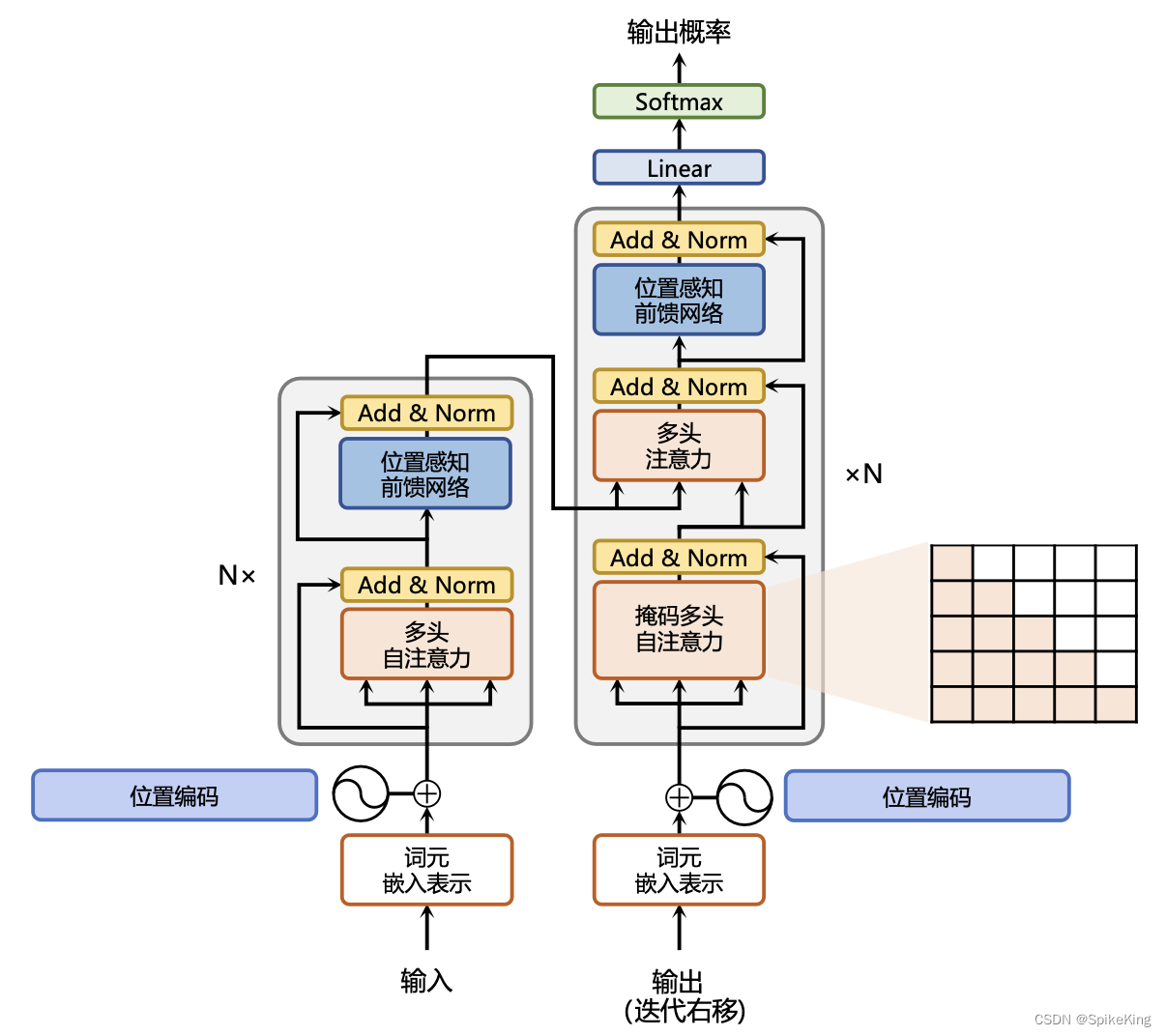
Transformer是一种重要的神经网络架构,在2017年由Google的研究者在论文“Attention Is All You Need”中提出。这个架构特别适用于处理序列数据,能够捕捉到输入数据中长距离的依赖关系。Transformer的核心是自注意力(Self-Attention)机制,这使得模型能够在序列中的任何位置关注到其他位置的信息,从而更好地理解文本的上下文。
Transformer架构主要由两部分组成,即编码器(Encoder)和解码器(Decoder)。每个部分都包含多个相同的层,每层都有自注意力和前馈神经网络。Transformer模型的一个关键创新是位置编码(Positional Encoding),给模型提供了单词在序列中位置的信息。由于模型本身不像RNN那样逐个处理序列,位置编码对于保持序列的顺序信息至关重要。
编码器负责处理输入序列,每个编码器层都包含2个子层:
- 多头自注意力机制(Multi-Head Self-Attention):允许模型同时关注序列中的不同位置,这有助于捕捉文本中的多种关系。
- 前馈神经网络(Feed-Forward Neural Network):对于自注意力层的输出进行进一步的处理。
解码器负责生成输出序列,每个解码器层除了包含编码器层中的2个子层外,还增加了1个子层:
- 编码器-解码器注意力机制(Encoder-Decoder Attention):交叉注意力,允许解码器关注编码器的输出,这有助于解码器在生成序列时利用输入序列的信息。
Transformer架构的这些特点使其在NLP领域取得了巨大的成功,不仅在机器翻译等任务中取得了突破性的表现,而且还催生了BERT、GPT等一系列强大的后续模型。
2. GPT
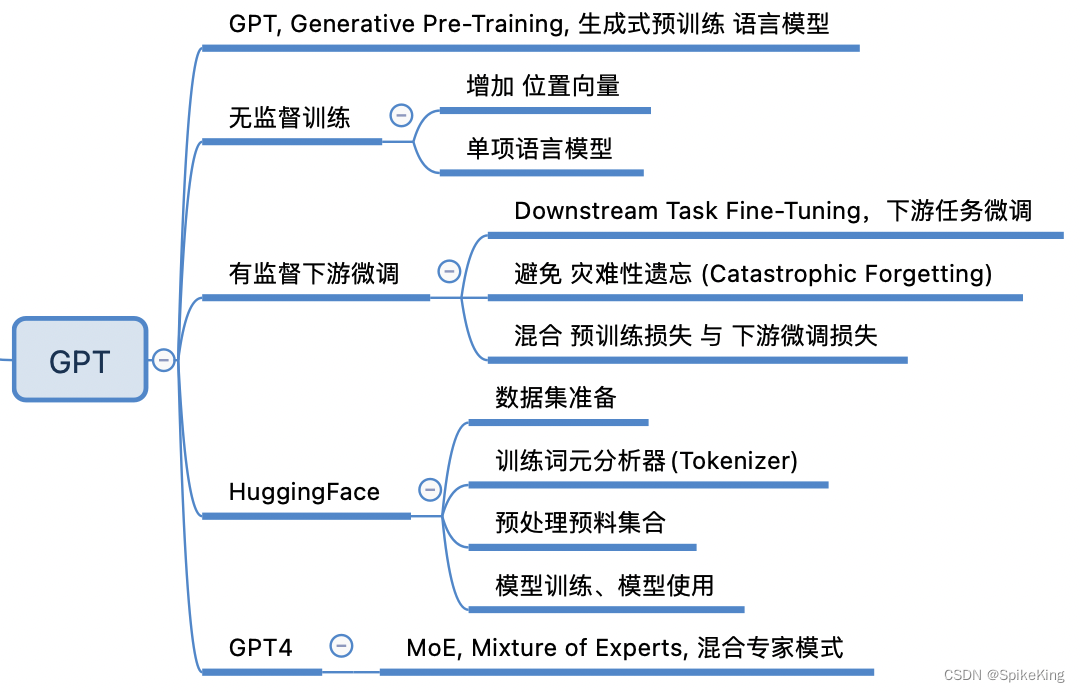
在GPT模型中,位置编码是一个关键部分,为输入序列的每个位置添加额外的信息。位置编码的目的是向模型提供每个词在句子中的相对位置信息,因为Transformer的自注意力机制并不关心词的顺序。在GPT模型中,位置编码通过将正弦和余弦函数应用于输入序列的每个位置来实现。
具体来说,GPT中的位置编码采用了三角式位置编码,这种编码方式在计算注意力分数时直接考虑两个Token之间的相对位置。这种编码方式利用了三角恒等变换公式,将位置T对应的位置向量 P E t + k PE_{t+k} PEt+k 分解为一个与相对距离k有关的矩阵 R k R_k Rk 和 P E t PE_t PEt 的乘积:
这样的性质使得三角式位置编码在处理相对位置信息时非常有效。请注意,这里的位置编码是相对位置编码,与绝对位置编码不同,不需要学习可学习的位置向量,而是直接利用了位置之间的相对关系。GPT中的位置编码通过三角函数的方式将相对位置信息融入到模型中,帮助模型更好地理解输入序列的顺序和结构。
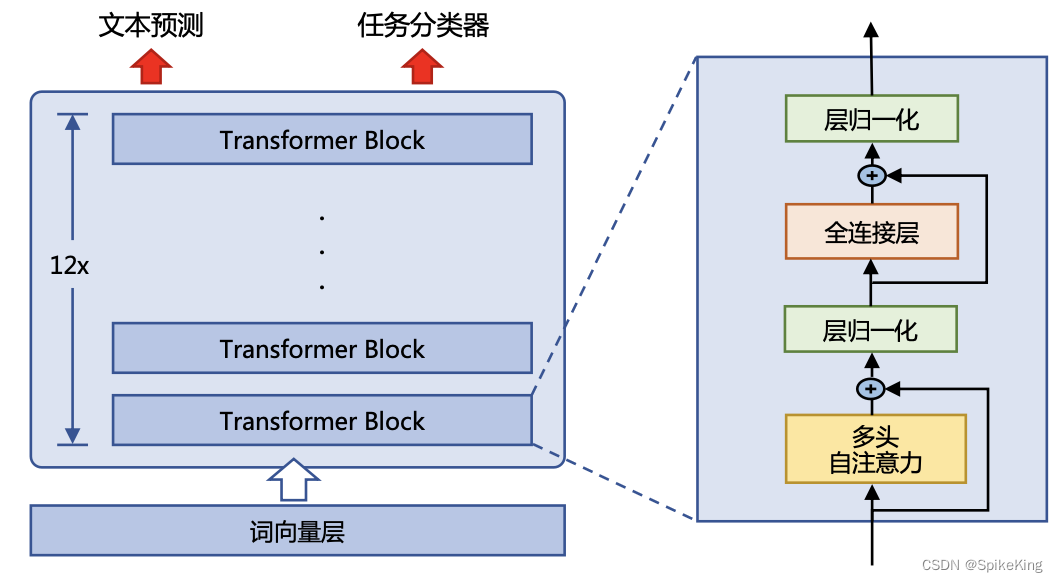
3. LLaMA
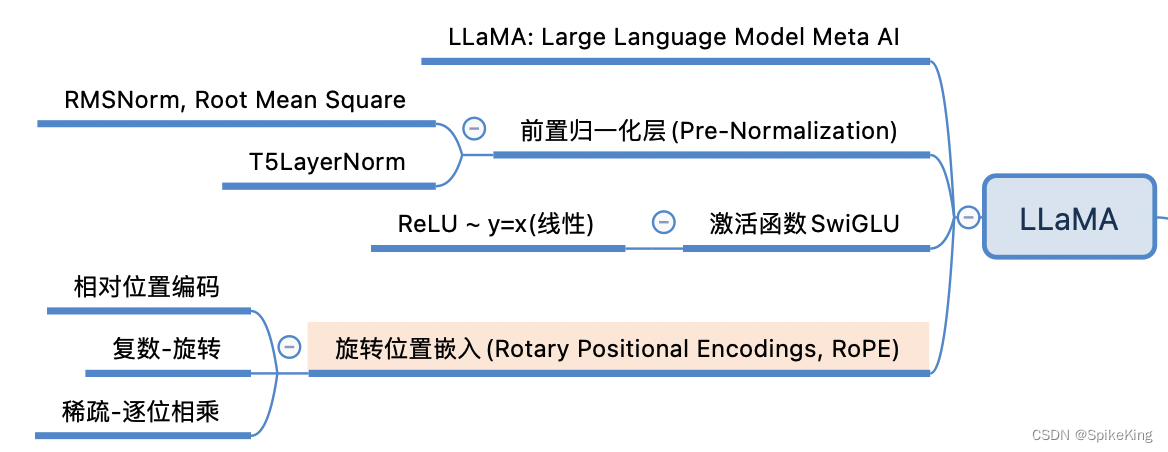
LLaMA 中的 旋转式位置编码(RoPE) 是专门为 Transformer 架构设计的嵌入方法,将相对位置信息集成到 self-attention 中并提升模型性能,比较一下 RoPE 和 Transformer 中的 绝对位置编码(Positional Encodings):
-
基本概念:
- RoPE 是能够将相对位置信息,依赖集成到 self-attention 中的位置编码方式。
- Transformer 中的位置编码,主要是为了捕捉输入序列中元素的绝对位置信息。
-
计算方式:
- RoPE 通过定义一个函数 g 来表示 query 向量 qm 和 key 向量 kn 之间的内积操作,该函数的输入是词嵌入向量 xm 和 xn ,以及之间的相对位置 m - n。
- Transformer 中的绝对位置编码则是在计算 query、key 和 value 向量之前,将一个位置编码向量 pi 加到词嵌入向量 xi 上,然后再乘以对应的变换矩阵 W。
-
位置编码向量:
- RoPE 中的位置编码向量的计算方式与复数相关,利用欧拉公式来表示实部和虚部。
- Transformer 中的位置编码向量通常采用经典的方式,如 sin 和 cos 函数。
-
外推性:
- RoPE 具有更好的外推性,即在训练和预测时输入长度不一致时,模型的泛化能力更强。
总之,RoPE 在处理相对位置信息方面具有优势,而 Transformer 的绝对位置编码则更关注捕捉绝对位置信息。
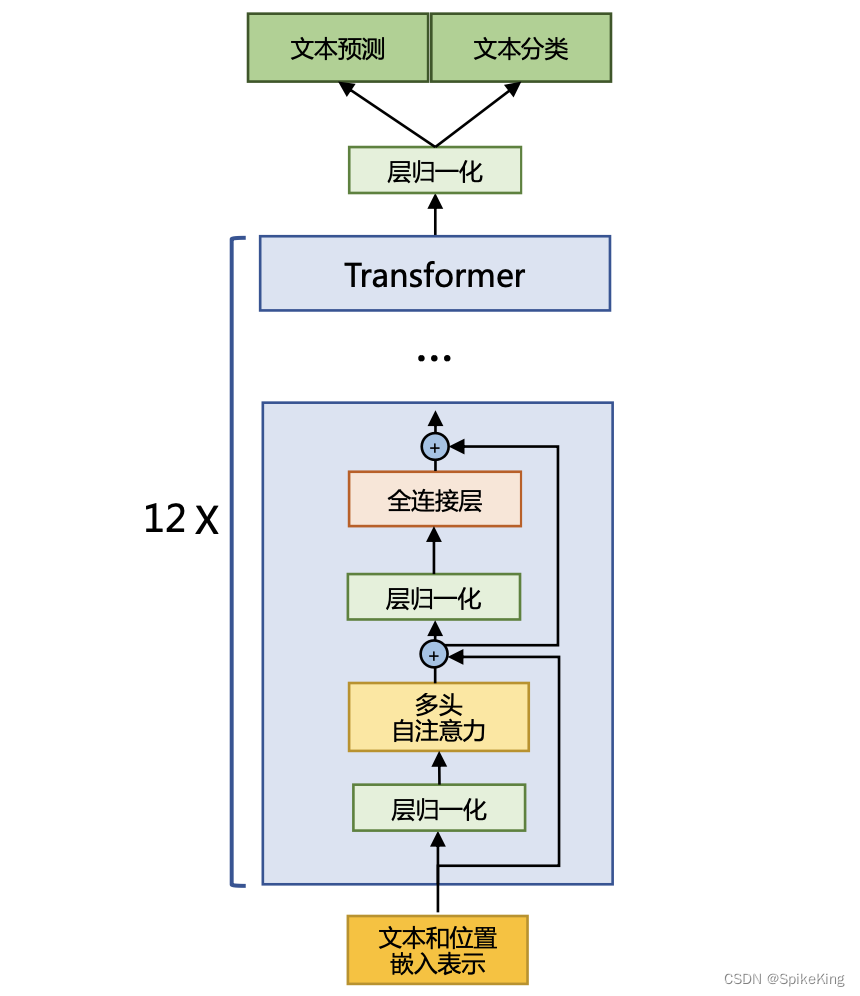
4. Attention优化
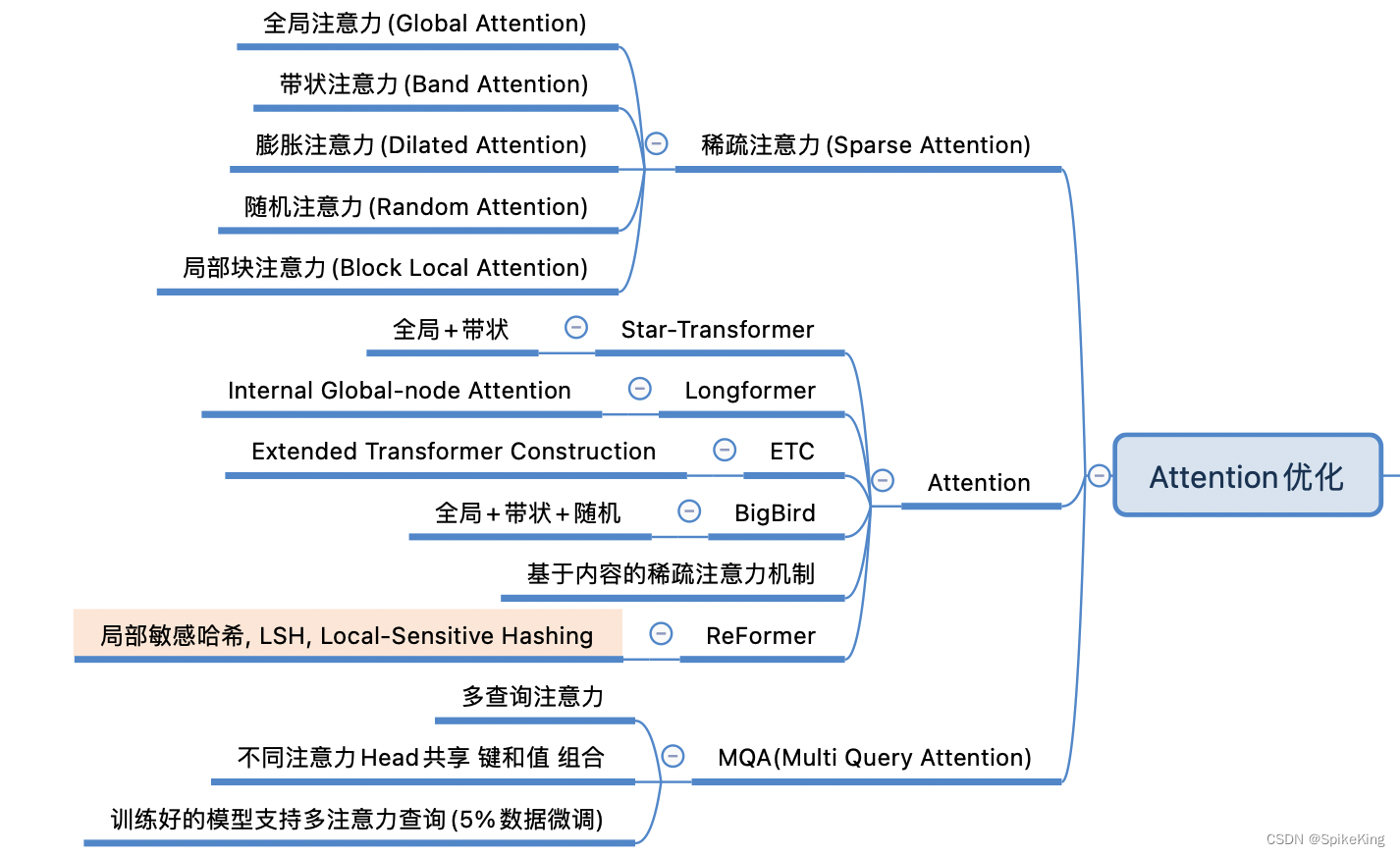
ReFormer 是一种高效的 Transformer 架构,专为处理长序列建模而设计。结合了两个关键技术,以解决 Transformer 在长上下文窗口应用中的注意力和内存分配问题。其中之一就是 局部敏感哈希(LSH),用于降低对长序列的注意力计算复杂度。ReFormer 中的 局部敏感哈希 加速原理:
-
ReFormer 自注意层:
- ReFormer 使用两种特殊的自注意层:局部自注意层和局部敏感哈希自注意层。
- 局部自注意层:这一层允许模型只关注输入序列中的局部区域,而不是整个序列。这有助于减少计算复杂度。
- 局部敏感哈希自注意层:这是 ReFormer 的创新之处。使用局部敏感哈希技术,将输入序列划分为不同的桶,每个桶包含一组相似的位置。然后,模型只需关注同一桶内的位置,从而减少了计算量。
-
可逆残差层:
- ReFormer 还使用了可逆残差层,以更高效地利用可用内存。
- 可逆残差层允许在训练过程中显著减少内存消耗。通过巧妙的残差架构实现。
总之,ReFormer 利用局部敏感哈希技术和可逆残差层,使得模型能够处理长达数十万标记的序列,而不会过度消耗内存,成为长序列建模的一种强大工具。
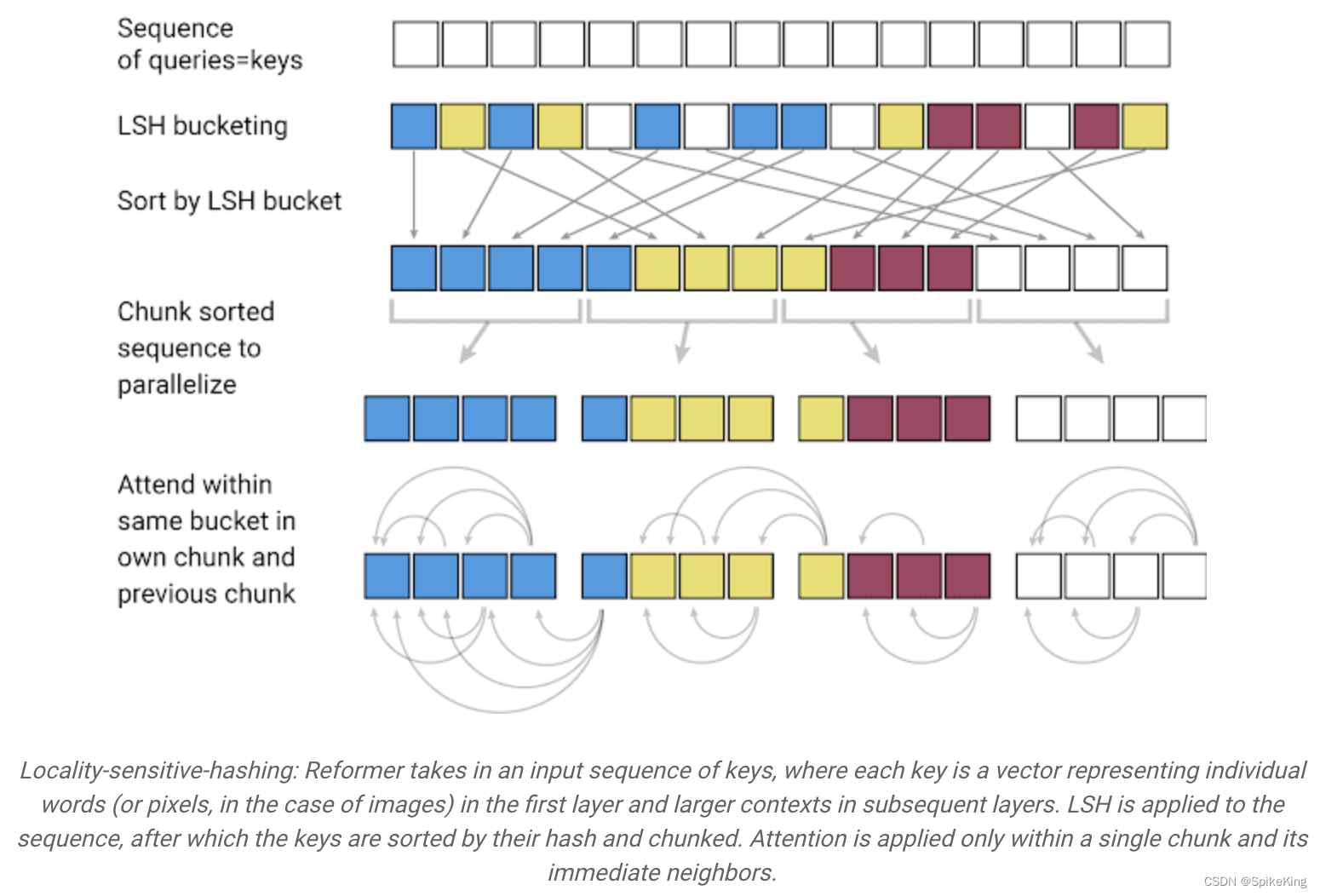
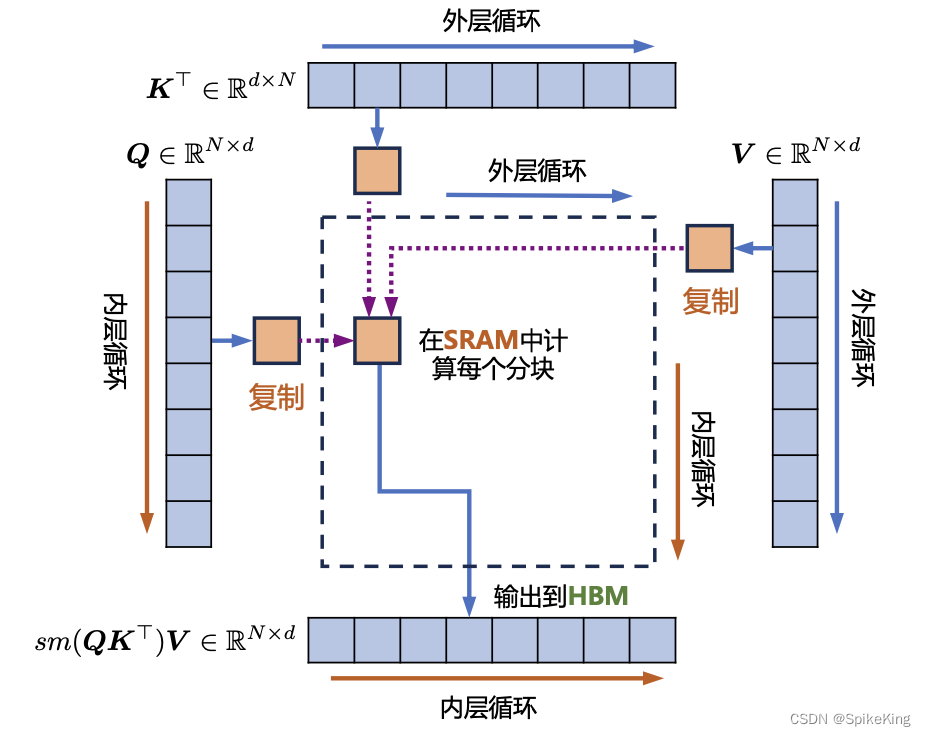
5. FlashAttention
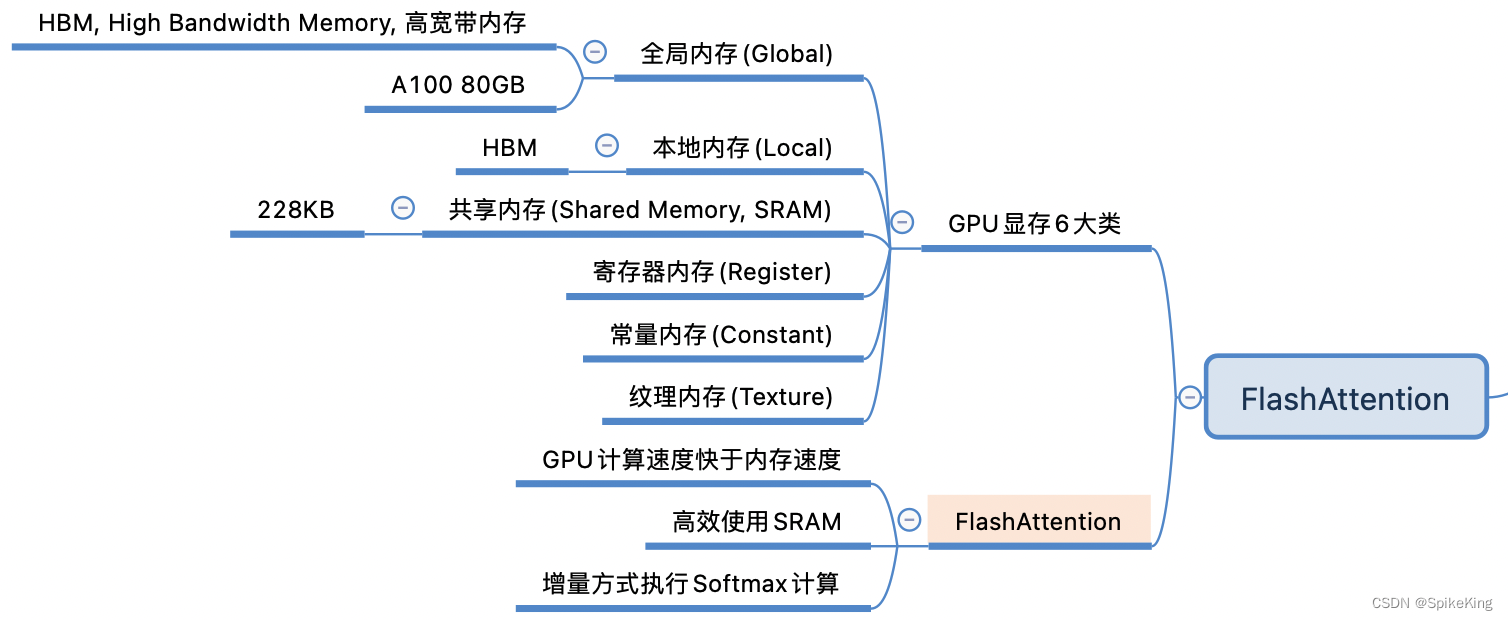
FlashAttention是用于Transformer模型的加速算法,降低注意力机制的计算复杂度和显存占用,通过优化 Softmax 计算和减少显存访问次数,来实现快速且节省内存的精确注意力计算。传统的 Softmax 计算,需要减去 Score 矩阵中的最大值,然后,进行指数运算和归一化,这会增加计算量。在FlashAttention中的增量Softmax计算避免了减去最大值这一步骤,而是在局部块中进行弥补计算,这样可以减少计算量。其中,FlashAttention算法有两个循环:外部循环j和内部循环i。在外部循环中,对K和V矩阵进行分块计算。在内部循环中,对于Q矩阵进行分块计算。