先举个有趣的例子理解 Q 、 K 、 V Q、K、V Q、K、V:
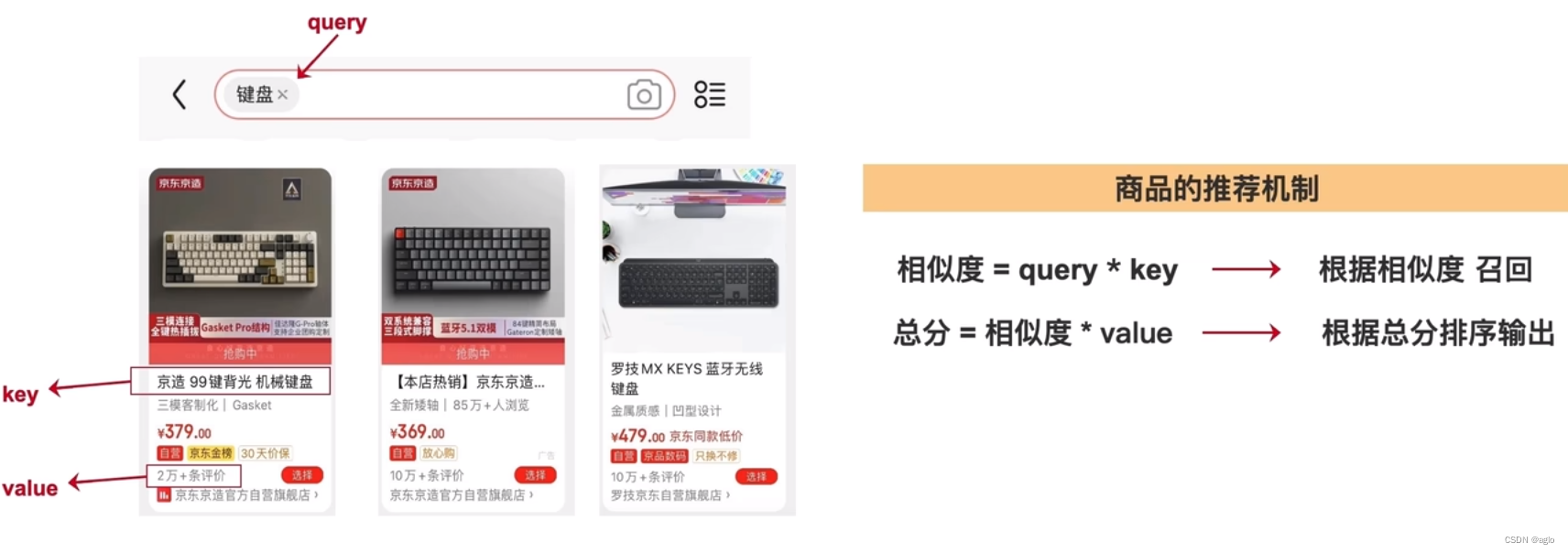
将我们要查询的内容,和商品列表进行相似度匹配,先拿出相似度更高的商品列表。
再根据以往的评价,计算出总分,按照分数进行排序。
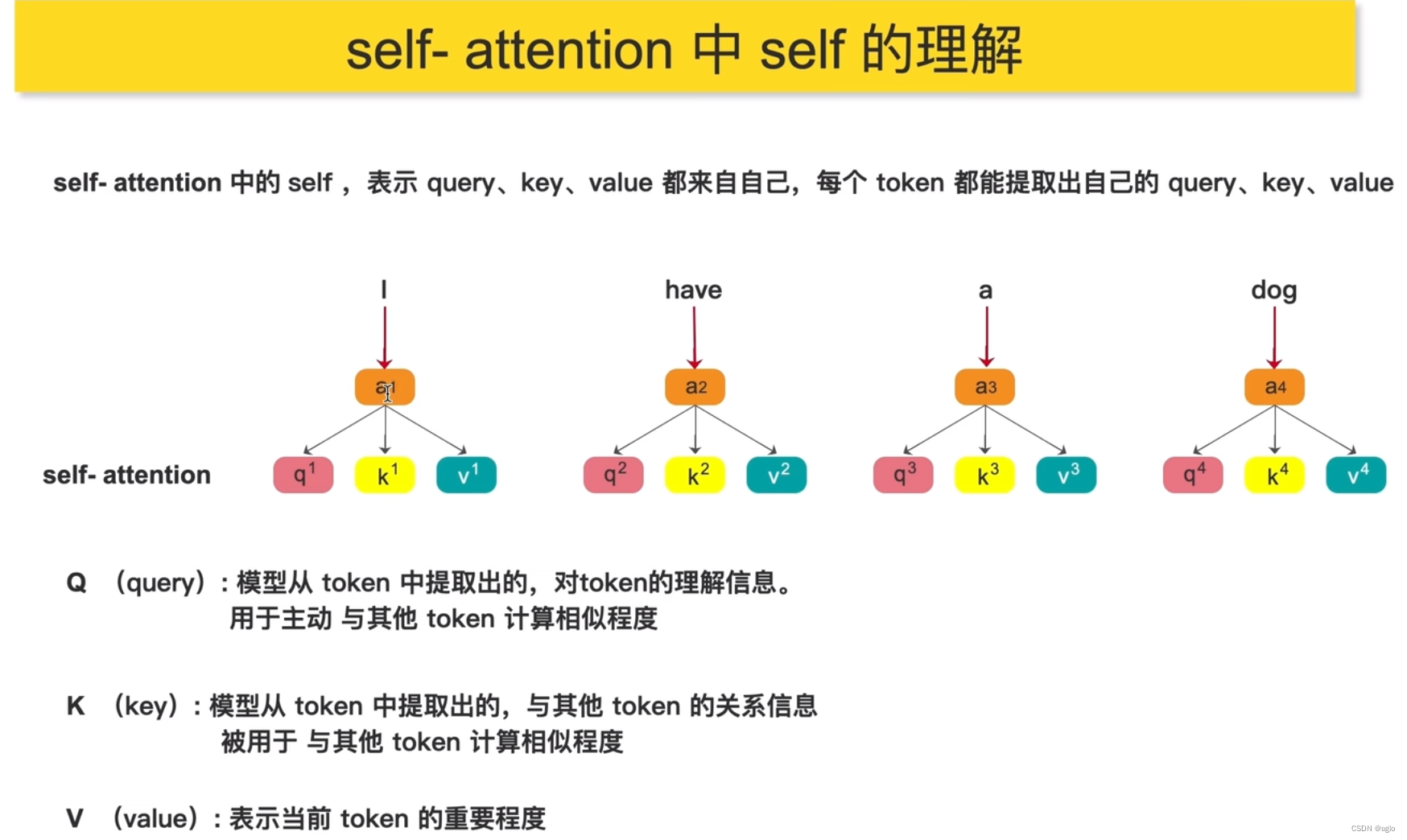
self-attention
d k \sqrt{d_k} dk的意义: d k d_k dk表示k向量的长度,这里除以 d k \sqrt{d_k} dk,是因为如果 Q 、 K Q、K Q、K的维度很长的时候, Q K T QK^T QKT点积后就会变得很大,这样就会将softmax函数推到具有非常小的梯度区域当中去,为了避免这种影响,所以除以 d k \sqrt{d_k} dk
-
“非常小的梯度区域” 指的是在优化算法中,模型参数的梯度值(即损失函数关于参数的变化率)非常接近于零的情况。这可能发生在训练过程中,当模型接近一个局部极小值或平稳区域时,梯度值可能会变得非常小,甚至接近于零。
-
在深度学习中,梯度下降等优化算法用于更新模型的参数,以最小化损失函数。梯度指导着参数的更新方向,因此较大的梯度通常会导致较大的参数更新,从而加速训练。然而,如果梯度变得非常小,参数的更新幅度将会减缓,从而可能影响模型的训练速度和性能。
整个计算过程:
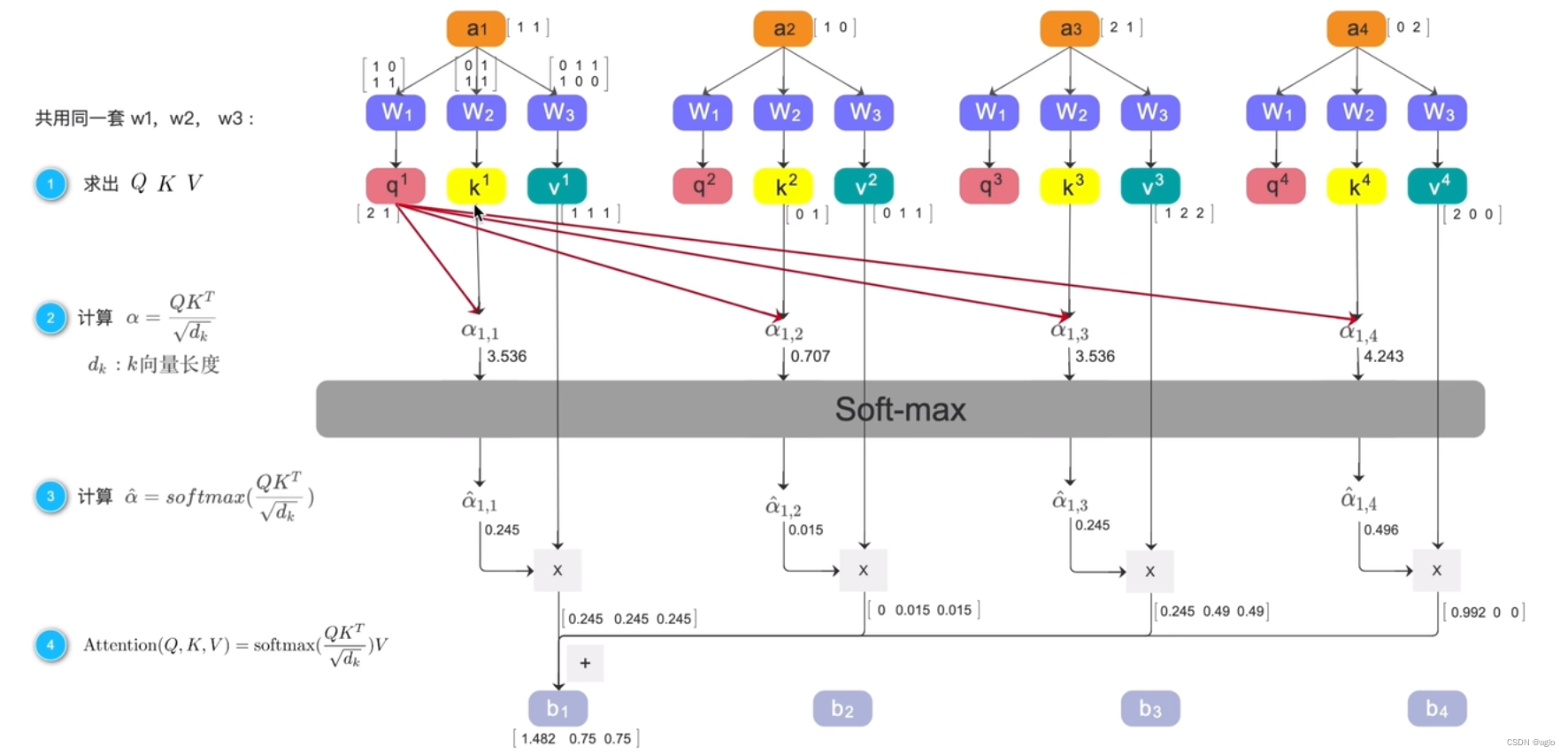
假设 a 1 a_1 a1, a 2 a_2 a2, a 3 a_3 a3, a 4 a_4 a4都是embedding之后的向量
步骤一:求出 Q 、 K 、 V Q、K、V Q、K、V
从这几个向量 a 1 a_1 a1, a 2 a_2 a2, a 3 a_3 a3, a 4 a_4 a4中分别提取 q i q^i qi k i k^i ki v i v^i vi,实用的提取方式就是让他们分别乘以 W 1 W_1 W1, W 2 W_2 W2, W 3 W_3 W3,例如
- q 1 q^1 q1 = a 1 ∗ W 1 a^1 * W_1 a1∗W1
- k 1 k^1 k1 = a 1 ∗ W 2 a^1 * W_2 a1∗W2
- v 1 v^1 v1 = a 1 ∗ W 3 a^1 * W_3 a1∗W3
由于他们都是公用一套 W 1 W_1 W1, W 2 W_2 W2, W 3 W_3 W3,所以可以并行计算:
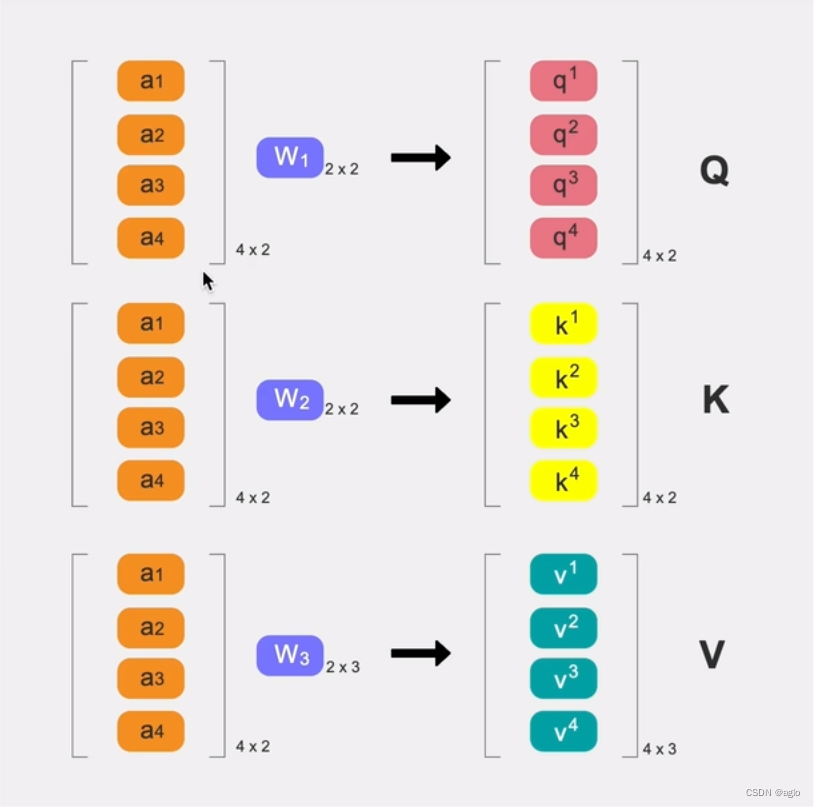
将所有的 a 1 a_1 a1, a 2 a_2 a2, a 3 a_3 a3, a 4 a_4 a4 concat起来,得到一个4x2的矩阵,分别乘以 W 1 W_1 W1, W 2 W_2 W2, W 3 W_3 W3。
- 乘 W 1 W_1 W1,就会得到一个4x2的输出矩阵,输出的每一行就是 q 1 q^1 q1, q 2 q^2 q2, q 3 q^3 q3, q 4 q^4 q4,整个矩阵就是 Q Q Q,也就是公式中的 Q Q Q,
- V V V的维度不一定要和 Q 、 K Q、K Q、K的维度一样,但一般在nlp中他们都是一样的
- W i W_i Wi初始值随机,随着训练更新
步骤二: 计算 α = Q K T d k d k : k 向量长度 \begin{aligned}\text{计算}&\alpha=\frac{QK^T}{\sqrt{d_k}}\\d_k&:k\text{向量长度}\end{aligned} 计算dkα=dkQKT:k向量长度
在得到了 q i q^i qi k i k^i ki v i v^i vi之后,先用 q 1 q_1 q1举例:
q 1 q_1 q1分别和 k 1 k^1 k1, k 2 k^2 k2, k 3 k^3 k3, k 4 k^4 k4相乘,得到了 α 1 , 1 \alpha_{1,1} α1,1, α 1 , 2 \alpha_{1,2} α1,2, α 1 , 3 \alpha_{1,3} α1,3, α 1 , 4 \alpha_{1,4} α1,4,这四个数值 α i {\alpha_i} αi称他为相似度分数
步骤三:softmax处理 α ^ = s o f t m a x ( Q K T d k ) \hat{\alpha}=softmax(\frac{QK^T}{\sqrt{d_k}}) α^=softmax(dkQKT)
把4个相似度分数经过softmax处理,我们就拿了新的4个相似度分数,
步骤四:
把上面得到的4个新数值,分别和 v 1 v^1 v1, v 2 v^2 v2, v 3 v^3 v3, v 4 v^4 v4进行相乘后的结果再相加,得到加权和 b 1 b_1 b1、 b 2 b_2 b2、 b 3 b_3 b3、 b 4 b_4 b4
这里面的 b i b_i bi每一个都包含了全局信息,因为在计算过程中,这每一个b都是他自己的query和其他的key进行计算的得到的。

代码演示

随机出一个输入X,X的维度就是1、4、2,1是batchsize,4是指有4个token,2是指每个token的长度,
将X传入到对象中去,
d k ∗ − 0.05 d_k * -0.05 dk∗−0.05 = 1 d k \frac{1}{\sqrt{d_k}} dk1
分别使用3个全连接层, 从输入中提取qkv,
然后Q乘K的转置再除以 d k \sqrt{d_k} dk,
最后在做一个softmax,在最后一个纬度做(dim=-1)
最后把softmax拿得到结果和V做点乘,拿到最终的输出。