LLM下半场之Agent基础能力概述:Profile、Memory、Plan、Action、Eval学习笔记
人工智能与算法学习 2023-11-13 06:38
以下文章来源于凡人机器学习 ,作者傲海

了解机器学习在业务中的应用,让更多的初级数据开发者可以享受到人工智能的福利。

一.Agent发展将会是LLM的下半场
目前大家都在讨论LLM,LLM解决的问题是帮助机器像人类一样理解彼此的意图,本质上来讲,LLM更像是一个技术或者工具。但是人类社会发生变革的引线,往往是一个产品或者解决方案,比如电池技术的发展带来了长续航,但是真正改变大家生活的是电动车这样一个产品。Agent的概念是创造一个个场景的智能体,可以在某些领域,比如在社会分析、电商导购、工业制造方面提供解决方案。LLM的发展将会让Agent的诞生成为可能,也会推动各个领域的Agent发展,所以我说Agent将会是LLM的下半场。
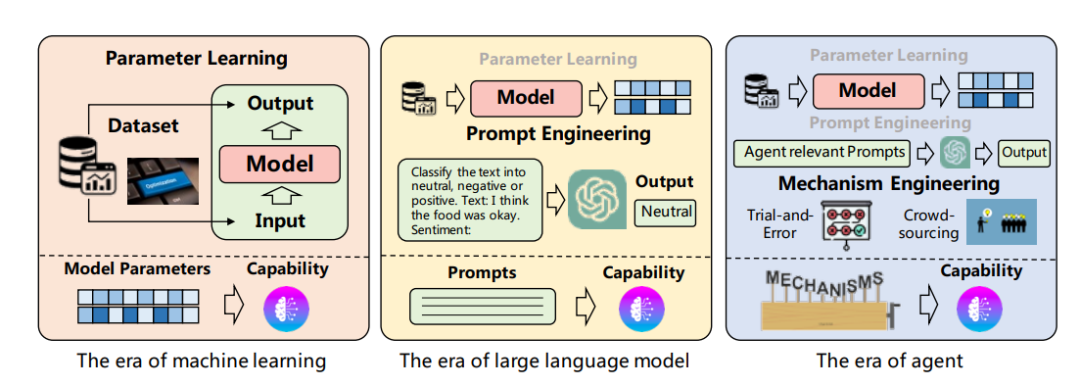
最近也是学习了一篇高瓴机构发布的论文《A Survvey on Large Language Model based Autonomous Agents》,将里面的内容和最近的思考做个整理。
二.Agent的整体结构
如果要实现以LLM为Base的Agent,主要需要从两个角度思考问题,(1)如何设计一种架构可以更高效的应用LLM(2)如何让Agent具备解决不同任务的范化能力,当然这个也依赖于LLM。目前行业里通常通用的一种架构是由Profile、Memory、Planning、Action所构建的四级架构。
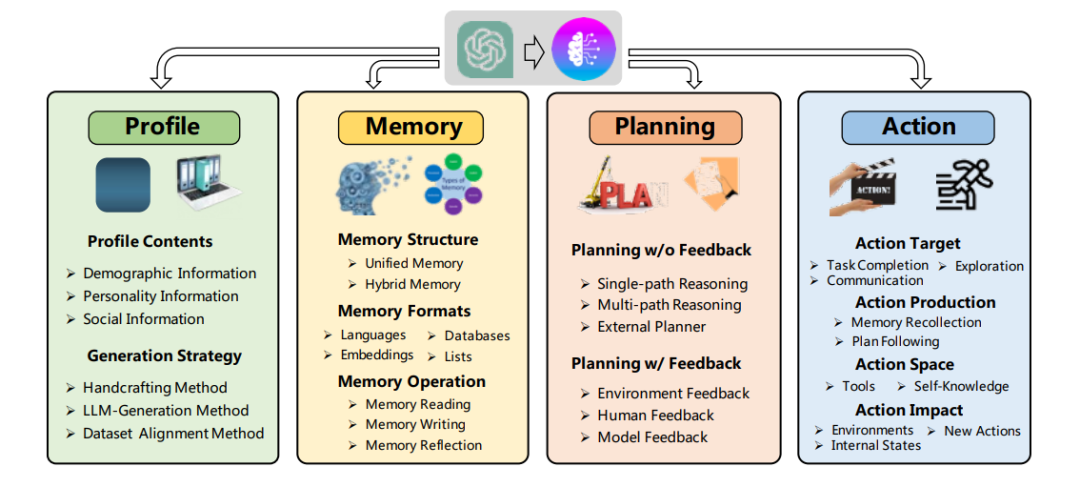
1.Profile模块
Profile模块解决的问题是告诉Agent他的角色,或者换一种说法,是告诉Agent需要解决的问题的背景信息。Profile有三种实现模式。第一种是人工设定模式,比如告诉Agent你是个外向的厨师,你需要解决点餐环节客人的问题。第二种是LLM延申模式,先把一些背景告诉LLM,让LLM给出一些候选集,比方说告诉LLM生成几种人物,解决点餐的问题,然后基于LLM的输出选择合适的Profile方向。第三种是基于database,比方说已经在数据库中存储了某些厨师的数据,包含他的各种身体特征,然后完成设定。
2.Memory模块
Memory模块是Agent解决方案中的重要一环。Memory主要解决的是行业知识的传递问题,可以让Agent拥有长期和短期记忆,让他表现得更智能。
Shot-Memory一般用来传递上下文的的对话信息,常常通过Prompt作为传递介质。而Long-Memory更多的是领域知识,需要有独立的存储模块。Long-Memory的存储结构可能是自然语言、Embedding、结构化的表等。比如做一个餐厅服务点餐Agent,那么完全可以把菜单内容以自然语言的形式存储为Long-Memory,每次点餐要求Agent从约定内容里面选择。随着LLM的发展,目前向量数据库也成为了投资的重点领域,因为以Embedding存储,可以更有利于在大规模数据的前提下压缩信息和高效检索。
3.Planning模块
这一模块是最体现智能能力的模块,这个模块需要根据任务设定具体的执行方案。

Planning模块可以是两种结构,一种是Single-Path,这里引入CoT的概念(Chain of thought),可以要求LLM基于任务一步步推理,形成一个解决方案。每一步推理后产出的内容可以再次输入给LLM去判断下一步如何走。
另一种是Muti-Path,这个方案更符合人类的思维方式,因为要解决问题,很难完全设定好端到端的流程,需要给出几种候选的模式,另外需要考虑环境反馈,可以每走一步再次推理和选择最优模式,这里可以参考最近非常火的ReAct的模式,另外LLM也可以代替人类去做多种方案的选择,我们可以把需要考虑的边界给到LLM,由LLM去思考每一步如何选择。
4.Action模块
这一步是执行模块,需要按照Planning的设计,完成目标。在这一步需要建设的能力是与外部的服务关联,比如我们的Agent是解决帮用户买飞机票的问题,那么在执行阶段就需要与飞机票务系统的订票接口关联,也需要与用户的信用卡付款接口关联。
三、Agent的评估模式
相比于LLM,Agent是一种更广泛的解决方案,于是如何评估Agent的能力是一个很有挑战性的问题。
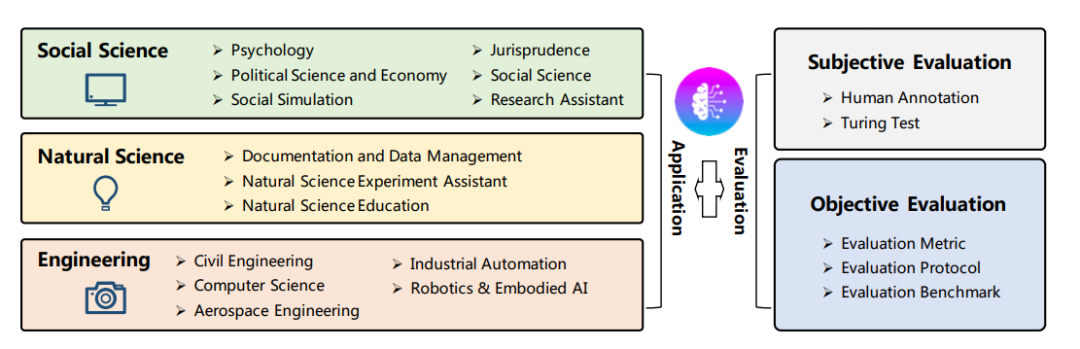
通常,评估有两种,,一种是主观评估,需要将Agent的执行结果给到人类去打分,所以最近许多类似于标注的众包平台也吸引到了资本的关注,但是这种评估模式的成本较高,很难规模化复制,这也是为什么Agent的迭代优化目前都只能在特定领域展开。
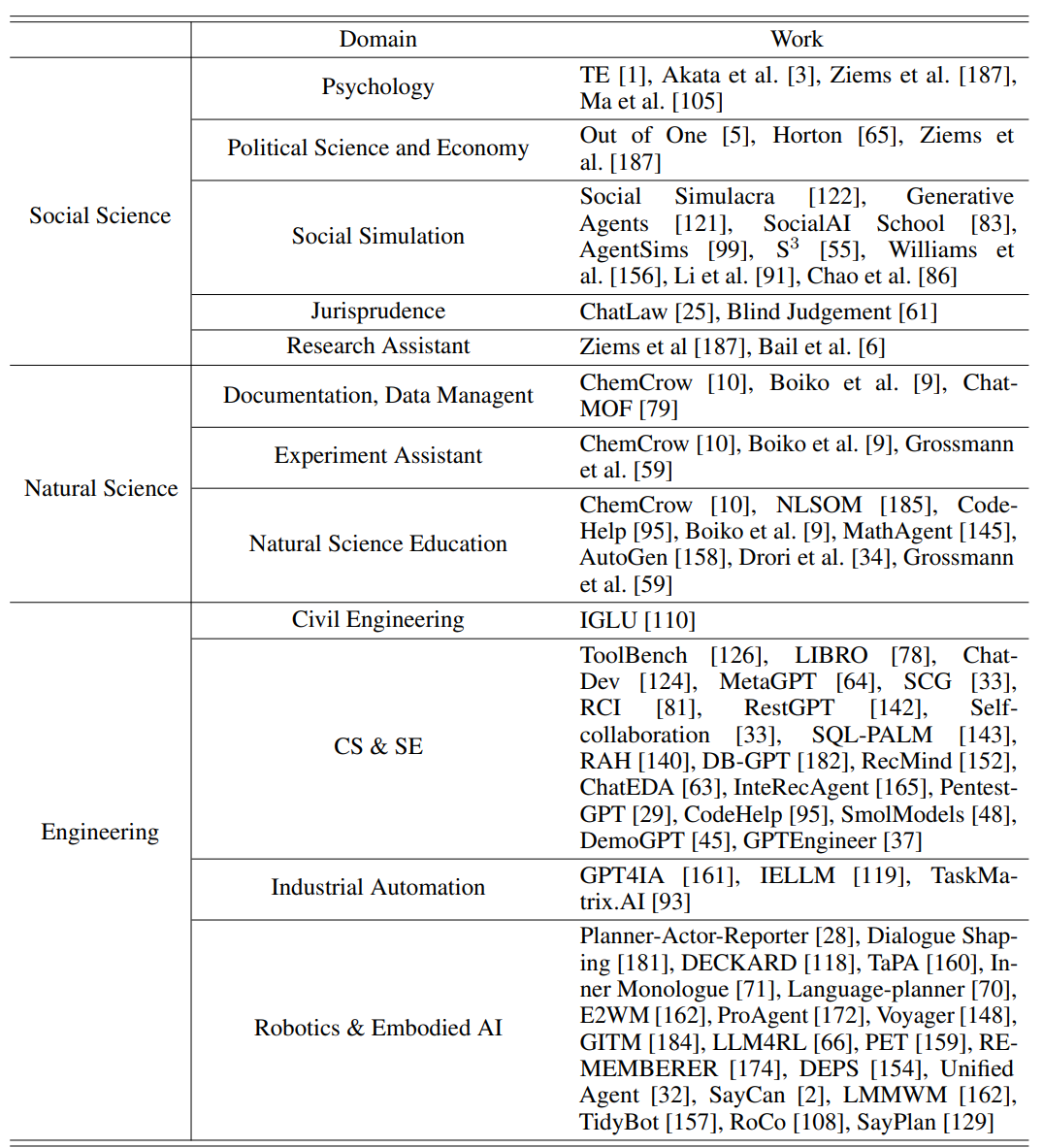
客观评估工作看上去更可能以程序化的模式低成本实现,但这也严重依赖与评价的Metrics设定和Benchmark集合,目前在社会学、自然科学、工程科学范畴已经沉淀了一些相关工作,这也使得相关领域的Agent看上去更有可能率先实现。
四、总结
目前行业中还没有特别出色或者优秀的Agent范本的出现,但是我个人对这个方向是深信不疑的,因为已经有许多工具可以应用,除了上面提到的评估相关的工作,如何串联四个流程,Langchain给了很好的参考。另外在Prompt设计方面,CoT、ReACT都提供了不错的思路,接下来行业内的各个玩家一定会在各个领域去探索Agent的落地可能,相信会在近期有一些成功案例诞生。
参考材料:
https://arxiv.org/pdf/2308.11432.pdf