1 自注意力概述
1.1 定义
自注意力机制(Self-Attention),有时也称为内部注意力机制,是一种在深度学习模型中应用的机制,尤其在处理序列数据时显得非常有效。它允许输入序列的每个元素都与序列中的其他元素进行比较,以计算序列的表示。这种机制使模型能够聚焦于输入序列中不同位置的关系,从而捕捉序列内的复杂依赖关系。
1.2 关键组件
-
查询(Query): 表示当前元素,用于与键进行匹配。
-
键(Key): 表示序列中的其他元素,用于与查询匹配。
-
值(Value): 也是序列中的其他元素,一旦键匹配查询,相关的值将用于构建输出。
-
注意力权重: 通过查询和键之间的相似度计算得出,决定了值对输出的贡献程度。
1.3 优点
-
并行计算: 不像循环神经网络,自注意力机制允许并行处理序列中的所有元素,提高了计算效率。
-
捕捉长距离依赖: 自注意力机制能够有效地捕捉序列中长距离的依赖关系。
-
灵活性: 这种机制可以应用于不同类型的序列数据,并且可以容易地扩展到更长的序列。
1.4 应用
-
自然语言处理(NLP): 在机器翻译、文本摘要、情感分析等任务中,自注意力机制帮助模型理解词语之间的复杂关系。
-
计算机视觉: 在图像识别和图像生成任务中,自注意力机制使模型能够捕捉图像中远距离的依赖关系。
-
序列建模: 在时间序列分析和音频处理中,自注意力机制有助于捕捉长期依赖关系。
扫描二维码关注公众号,回复: 17158422 查看本文章
2 自注意力深度解析
2.1 注意力机制和自注意力机制的区别
注意力机制(Attention)
传统的Attention机制发生在Target的元素和Source中的所有元素之间。
简单讲就是说Attention机制中的权重的计算需要Target来参与。即在Encoder-Decoder 模型中,Attention权值的计算不仅需要Encoder中的隐状态而且还需要Decoder中的隐状态。
自注意力机制(Self-Attention)
不是输入语句和输出语句之间的Attention机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的Attention机制。
例如在Transformer中在计算权重参数时,将文字向量转成对应的KQV,只需要在Source处进行对应的矩阵操作,用不到Target中的信息。
2.2 引入自注意力机制的目的
神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译问题(序列到序列的问题,机器自己决定多少个标签),词性标注问题(一个向量对应一个标签),语义分析问题(多个向量对应一个标签)等文字处理问题。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
2.3 Self-Attention
针对输入是一组向量,输出也是一组向量,输入长度为N(N可变化)的向量,输出同样为长度为N 的向量。
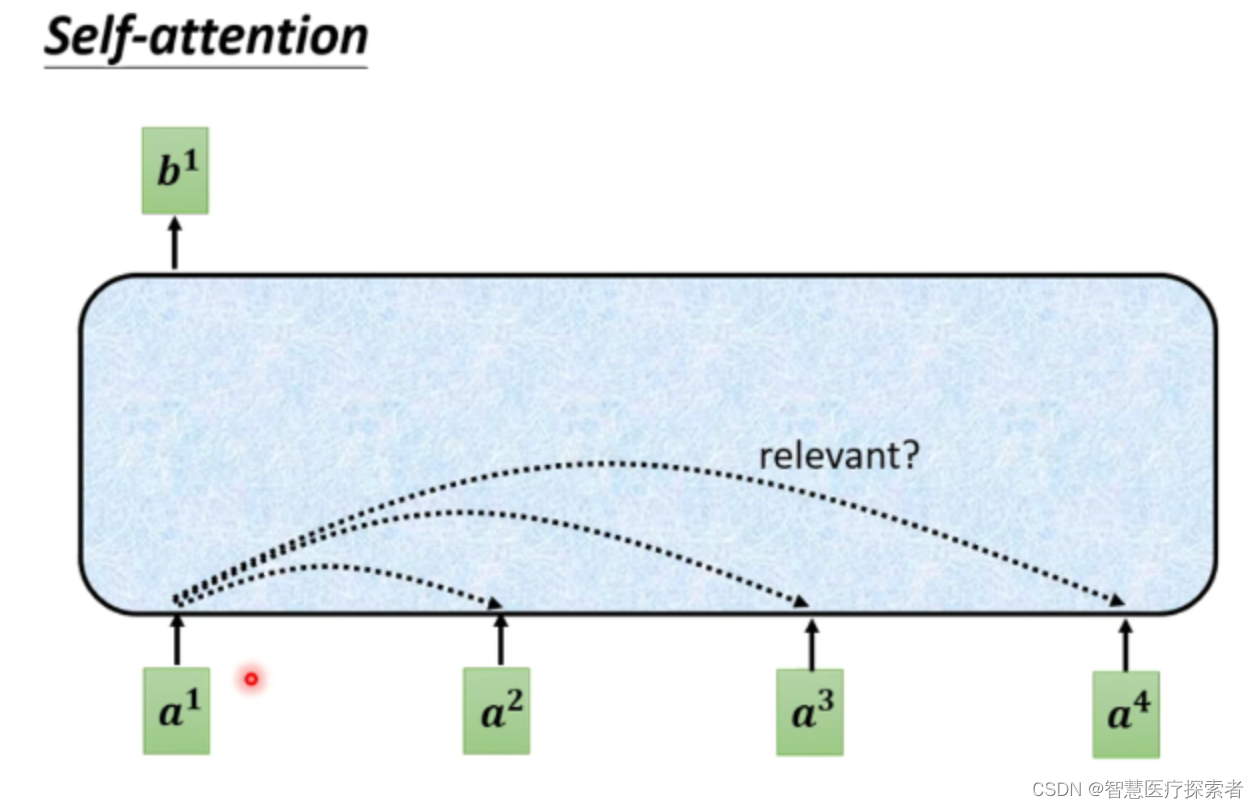
对于每一个输入向量a,经过蓝色部分self-attention之后都输出一个向量b,这个向量b是考虑了所有的输入向量产生的影响才得到的,这里有四个词向量a对应就会输出四个向量b。下面以
的输出为例:
首先,如何计算sequence中各向量与的关联程度,有下面两种方法

Dot-product方法是将两个向量乘上不同的矩阵w,得到q和k,做点积得到α,transformer中就用到了Dot-product。
-
上图中绿色的部分就是输入向量
和
,灰色的
和
为权重矩阵,需要学习来更新,用
-
上图右边加性模型这种机制也是输入向量与权重矩阵相乘,后相加,然后使用tanh投射到一个新的函数空间内,再与权重矩阵相乘,得到最后的结果。
可以计算每一个α(又称为attention score),q称为query,k称为key

另外,也可以计算和自己的关联性,再得到各向量与
的相关程度之后,用softmax计算出一个attention distribution,这样就把相关程度归一化,通过数值就可以看出哪些向量是和a1最有关系。
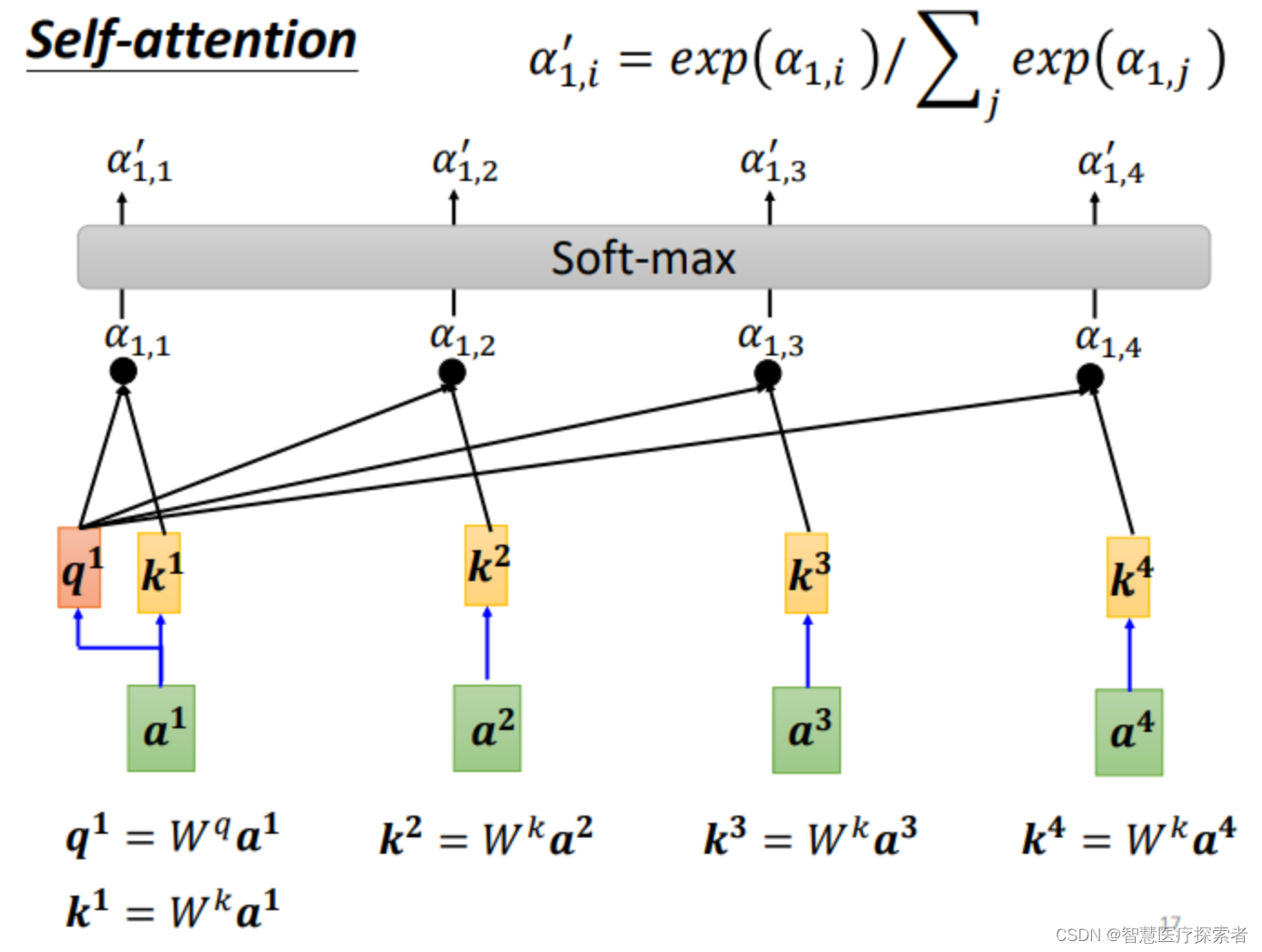
下面需要根据 α′ 抽取sequence里重要的资讯:

先求v,v就是键值value,v和q、k计算方式相同,也是用输入a乘以权重矩阵W,得到v后,与对应的α′ 相乘,每一个v乘与α'后求和,得到输出。
如果和
关联性比较高,
就比较大,那么,得到的输出
就可能比较接近
,即attention score决定了该vector在结果中占的分量;
矩阵形式
用矩阵运算表示的生成:
Step 1:q、k、v的矩阵形式生成
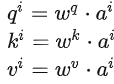
写成矩阵形式:
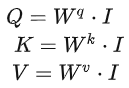
把4个输入a拼成一个矩阵,这个矩阵有4个column,也就是
到
,
乘上相应的权重矩阵W,得到相应的矩阵Q、K、V,分别表示query,key和value。
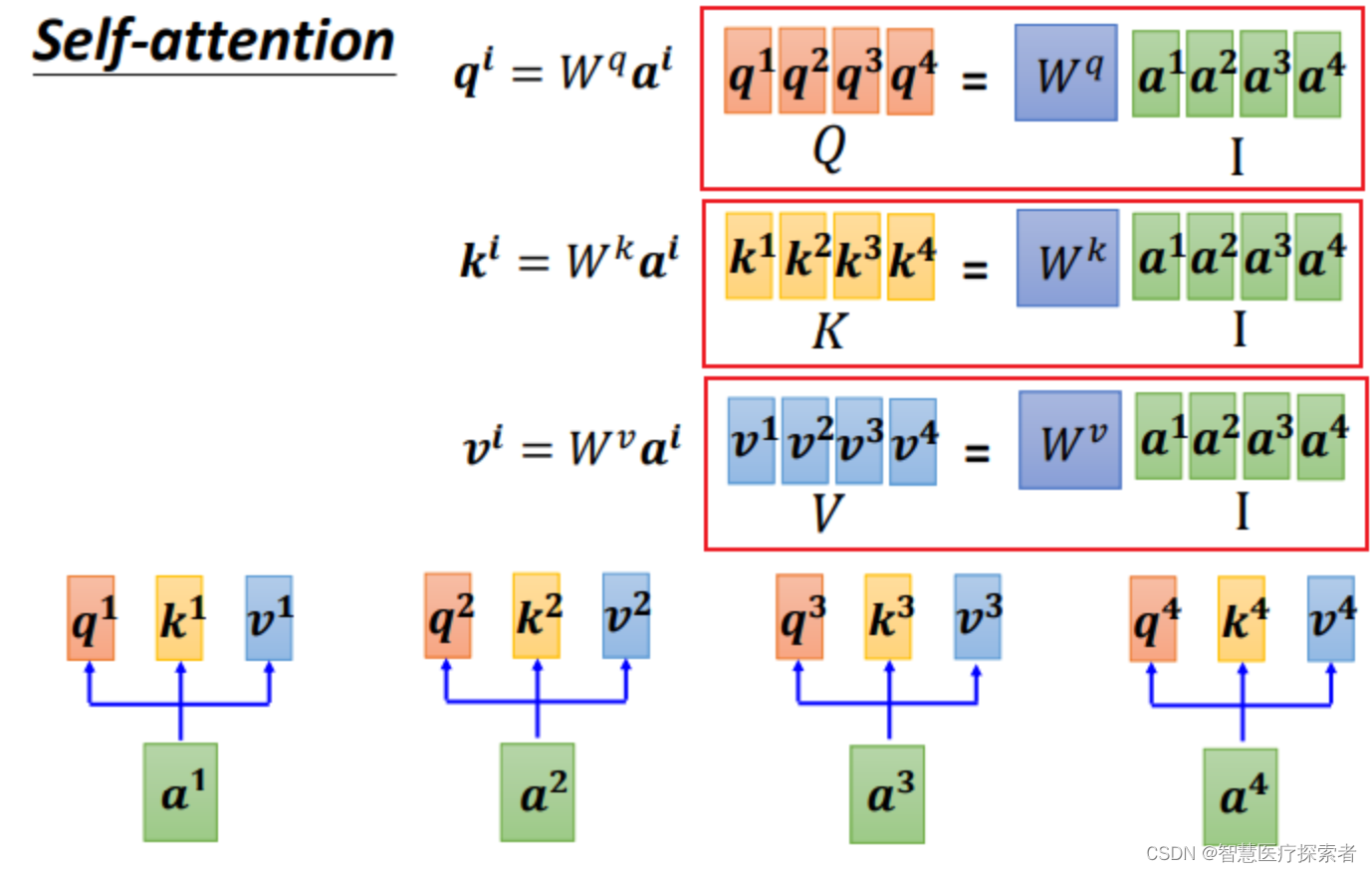
三个W是我们需要学习的参数
Step 2:利用得到的Q和K计算每两个输入向量之间的相关性,也就是计算attention的值α, α的计算方法有多种,通常采用点乘的方式。
先针对,通过与
到
拼接成的矩阵K相乘,得到
拼接成的矩阵。

同样,到
也可以拼接成矩阵Q直接与矩阵K相乘:

公式为:
![]()
矩阵形式:
![]()
矩阵A中的每一个值记录了对应的两个输入向量的Attention的大小α,A'是经过softmax归一化后的矩阵。
Step 3:利用得到的A'和V,计算每个输入向量a对应的self-attention层的输出向量b:

![]()
写成矩阵形式:
![]()
对self-attention操作过程做个总结,输入是I,输出是O:

矩阵、
、
是需要学习的参数。
2.4 Multi-head Self-attention
self-attention的进阶版本Multi-head Self-attention,名称为多头自注意力机制。因为相关性有很多种不同的形式,有很多种不同的定义,所以有时不能只有一个q,要有多个q,不同的q负责不同种类的相关性。
对于1个输入a
首先,和上面一样,用a乘权重矩阵W得到,然后再用
乘两个不同的W,得到两个不同的
,i代表的是位置,1和2代表的是这个位置的第几个q。
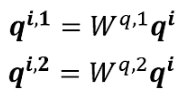
这上面这个图中,有两个head,代表这个问题有两种不同的相关性。
同样,k和v也需要有多个,两个k、v的计算方式和q相同,都是先算出来和
,然后再乘两个不同的权重矩阵。
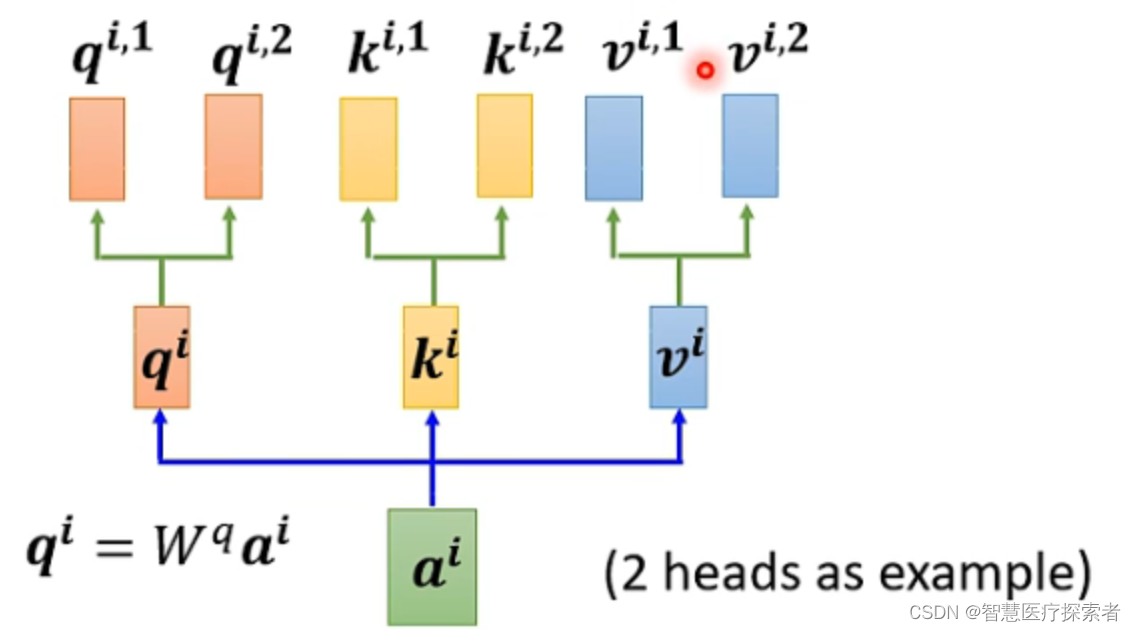
对于多个输入向量也一样,每个向量都有多个head:

算出来q、k、v之后怎么做self-attention呢?
和上面讲的过程一样,只不过是1那类的一起做,2那类的一起做,两个独立的过程,算出来两个b。
对于1:

对于2:
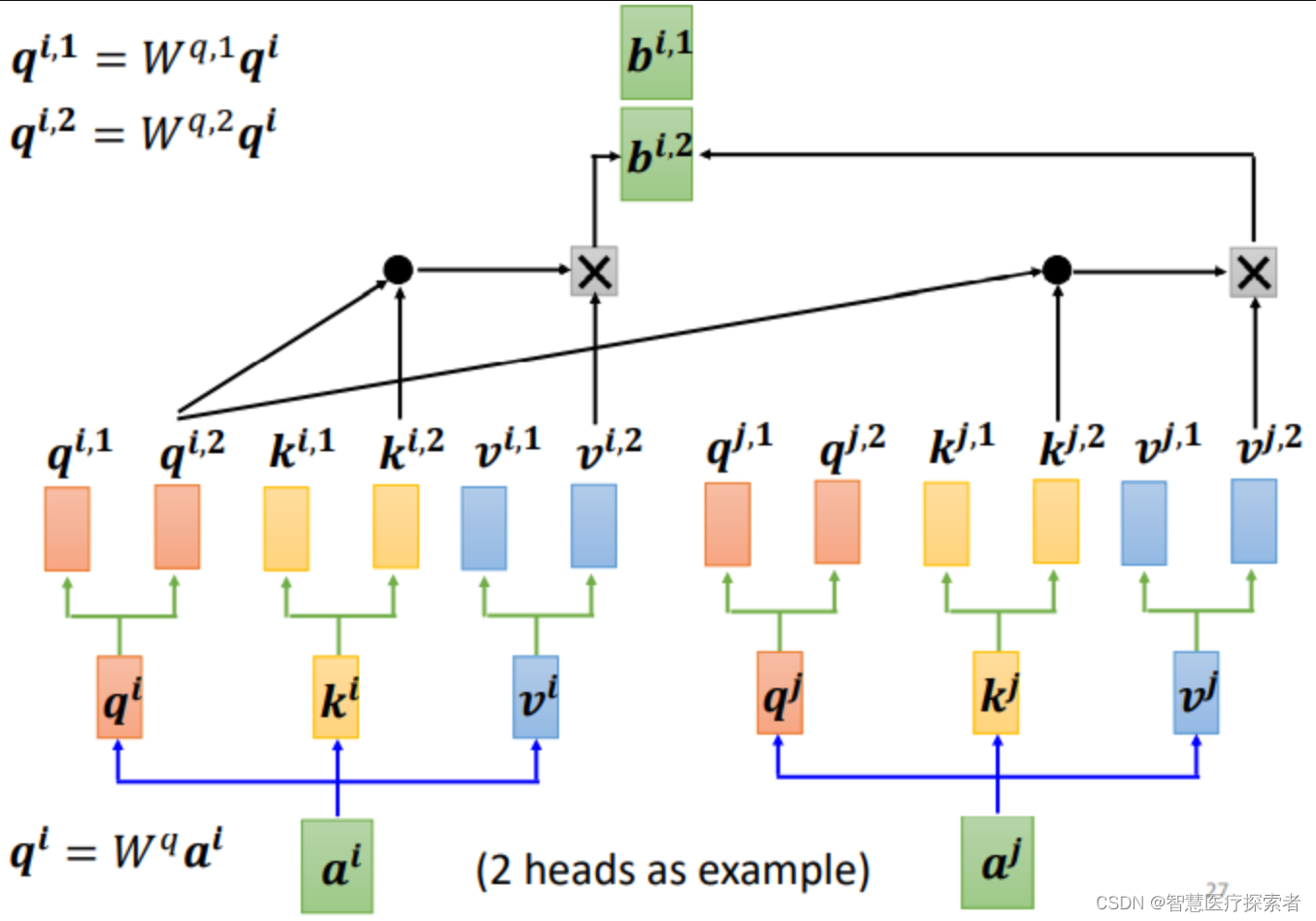
这只是两个head的例子,有多个head过程也一样,都是分开算b。
最后,把,
拼接成矩阵再乘权重矩阵W,得到
,也就是这个self- attention向量
的输出,如下图所示:
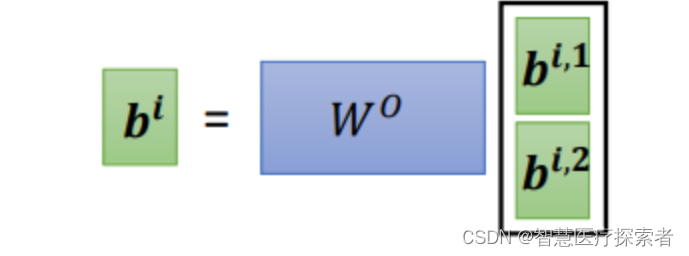
2.5 Positional Encoding
在训练self attention的时候,实际上对于位置的信息是缺失的,没有前后的区别,上面讲的,
,
不代表输入的顺序,只是指输入的向量数量,不像rnn,对于输入有明显的前后顺序,比如在翻译任务里面,对于“机器学习”,机器学习依次输入。而self-attention的输入是同时输入,输出也是同时产生然后输出的。
如何在Self-Attention里面体现位置信息呢?就是使用Positional Encoding
也就是新引入了一个位置向量,非常简单,如下图所示:

每一个位置设置一个vector,叫做positional vector,用表示,不同的位置有一个专属的
。
如果加上了
,就会体现出位置的信息,i是多少,位置就是多少。vector长度是人为设定的,也可以从数据中训练出来。
2.6 Self-Attention和RNN的区别
Self-attention和RNN的主要区别在于:
-
Self-attention可以考虑全部的输入,而RNN似乎只能考虑之前的输入(左边)。但是当使用双向RNN的时候可以避免这一问题。
-
Self-attention可以容易地考虑比较久之前的输入,而RNN的最早输入由于经过了很多层网络的处理变得较难考虑。
-
Self-attention可以并行计算,而RNN不同层之间具有先后顺序。
(1)Self-attention可以考虑全部的输入,而RNN似乎只能考虑之前的输入(左边)。但是当使用双向RNN的时候可以避免这一问题。
比如,对于第一个RNN,只考虑了深蓝色的输入,绿色及绿色后面的输入不会考虑,而Self-Attention对于4个输入全部考虑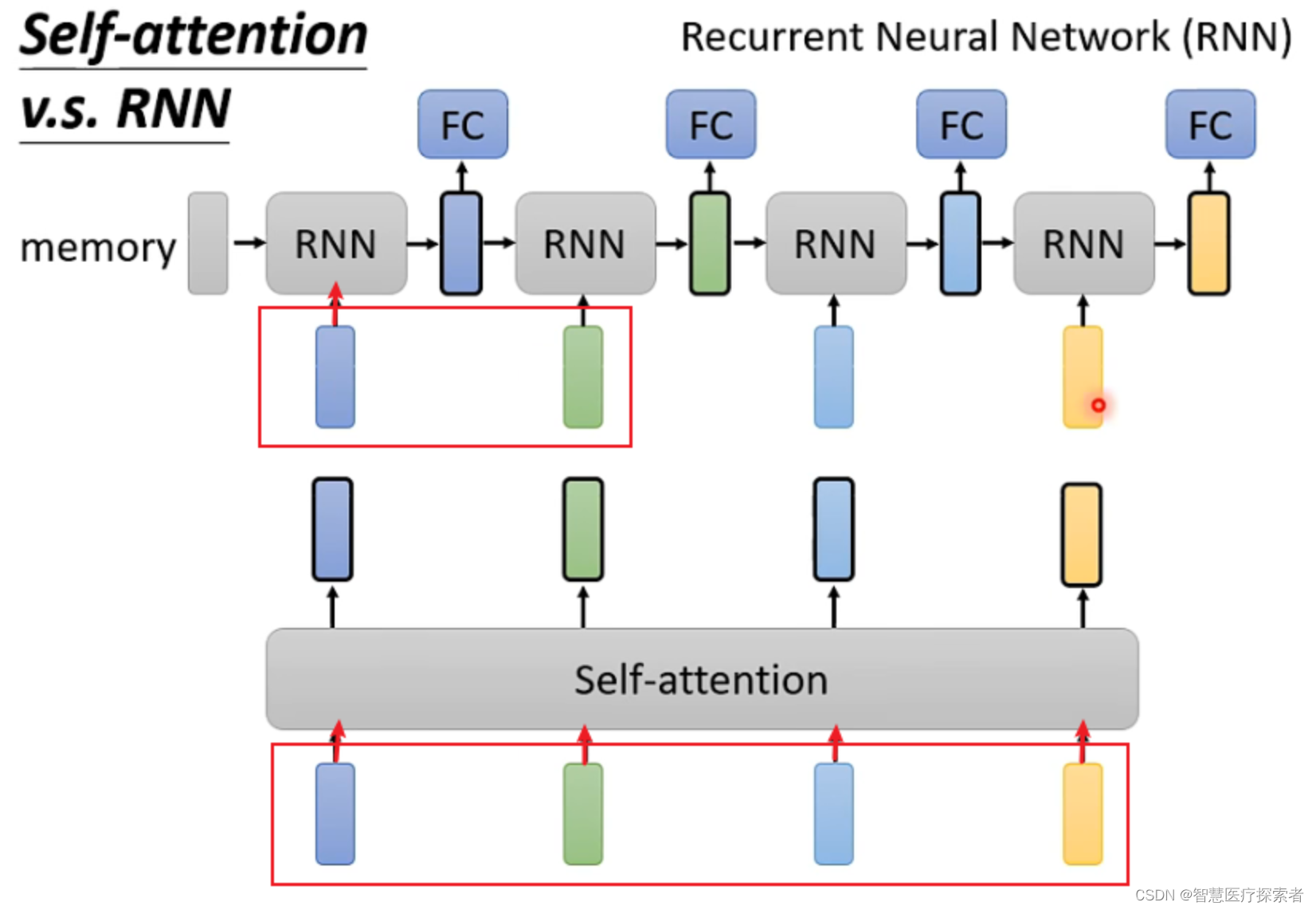
(2)Self-attention可以容易地考虑比较久之前的输入,而RNN的最早输入由于经过了很多层网络的处理变得较难考虑。
比如对于最后一个RNN的黄色输出,想要包含最开始的蓝色输入,必须保证蓝色输入在经过每层时信息都不丢失,但如果一个sequence很长,就很难保证。而Self-attention每个输出都和所有输入直接有关。
(3)Self-attention可以并行计算,而RNN不同层之间具有先后顺序。Self-attention的输入是同时输入,输出也是同时输出。