目录
一、环境
本文使用环境为:
- Windows10
- Python 3.9.17
- torch 1.13.1+cu117
- torchvision 0.14.1+cu117
二、self-attention原理
自注意力(Self-Attention)操作是基于 Transformer 的机器翻译模型的基本操作,在源语言的编
码和目标语言的生成中频繁地被使用以建模源语言、目标语言任意两个单词之间的依赖关系。给
定由单词语义嵌入及其位置编码叠加得到的输入表示 {xi ∈ Rd},为了实现对上下文语义依赖的建模,进一步引入在自注意力机制中涉及到的三个元素:查询 qi(Query),键 ki(Key),值 vi (Value)。在编码输入序列中每一个单词的表示的过程中,这三个元素用于计算上下文单词所对应的权重得分。直观地说,这些权重反映了在编码当前单词的表示时,对于上下文不同部分所需要的关注程度。具体来说,如图所示,通过三个线性变换 WQ,WK ,WV 将输入序列中的每一个单词表示 xi 转换为其对应的 qi,ki ,vi 向量。
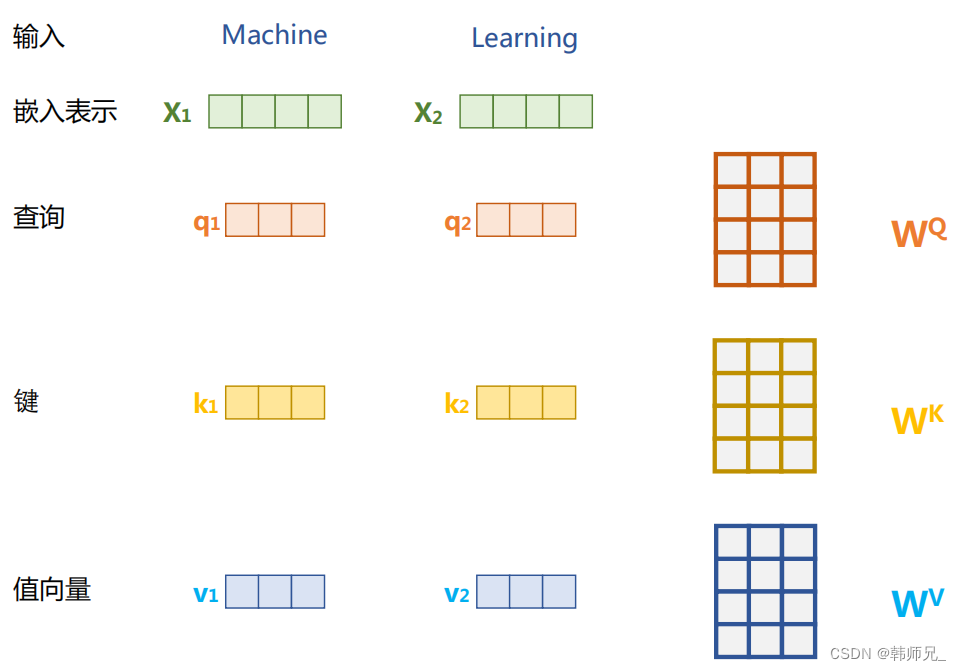
为了得到编码单词 xi 时所需要关注的上下文信息,通过位置 i 查询向量与其他位置的键向量做点积得到匹配分数 qi · k1, qi · k2, ..., qi · kt。为了防止过大的匹配分数在后续 Softmax 计算过程中导致的梯度爆炸以及收敛效率差的问题,这些得分会除放缩因子 √d 以稳定优化。放缩后的得分经过 Softmax 归一化为概率之后,与其他位置的值向量相乘来聚合希望关注的上下文信息,并最小化不相关信息的干扰。上述计算过程可以被形式化地表述如下:
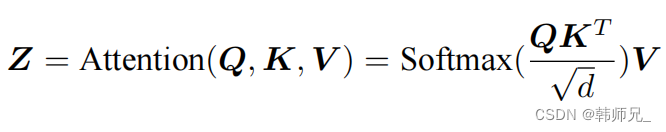
其中 Q , K ,V 分别表示输入序列中的不同单词的 q, k, v 向量拼接组成的矩阵,L 表示序列长度,Z 表示自注意力操作的输出。为了进一步增强自注意力机制聚合上下文信息的能力,提出了多头自注意力(Multi-head Attention)的机制,以关注上下文的不同侧面。具体来说,上下文中每一个单词的表示 xi 经过多组线性 {WQ*WK*WV } 映射到不同的表示子空间中。公式会在不同的子空间中分别计算并得到不同的上下文相关的单词序列表示{Zj}。最终,线性变换 WO 用于综合不同子空间中的上下文表示并形成自注意力层最终的输出 xi 。
三、完整代码
import torch.nn as nn
import torch
import math
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads # 512 / 8
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def attention(self, q, k, v, d_k, mask=None, dropout=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k) # self-attention公式
# 掩盖掉那些为了填补长度增加的单元,使其通过 softmax 计算后为 0
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1) # self-attention公式
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v) # self-attention公式
return output
def forward(self, q, k, v, mask=None):
bs = q.size(0) # 进行线性操作划分为成 h 个头
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# 矩阵转置
k = k.transpose(1,2)
q = q.transpose(1,2)
v = v.transpose(1,2) # 计算 attention
scores = self.attention(q, k, v, self.d_k, mask, self.dropout)
# 连接多个头并输入到最后的线性层
concat = scores.transpose(1,2).contiguous().view(bs, -1, self.d_model)
output = self.out(concat)
return output
# 准备q、k、v张量
d_model = 512
num_heads = 8
batch_size = 32
seq_len = 64
q = torch.randn(batch_size, seq_len, d_model) # 64 x 512
k = torch.randn(batch_size, seq_len, d_model) # 64 x 512
v = torch.randn(batch_size, seq_len, d_model) # 64 x 512
sa = MultiHeadAttention(heads = num_heads, d_model=d_model)
print(sa(q, k, v).shape) # torch.Size([32, 64, 512])
print('')