文章目录
1 原理简述
Self-Attention Layer 一次检查同一句子中的所有单词的注意力,这使得它成为一个简单的矩阵计算,并且能够在计算单元上并行计算。 此外,Self-Attention Layer 可以使用下面提到的 Multi-Head 架构来拓宽视野,也就是多头注意力机制。Self-Attention Layer 基本结构如下:
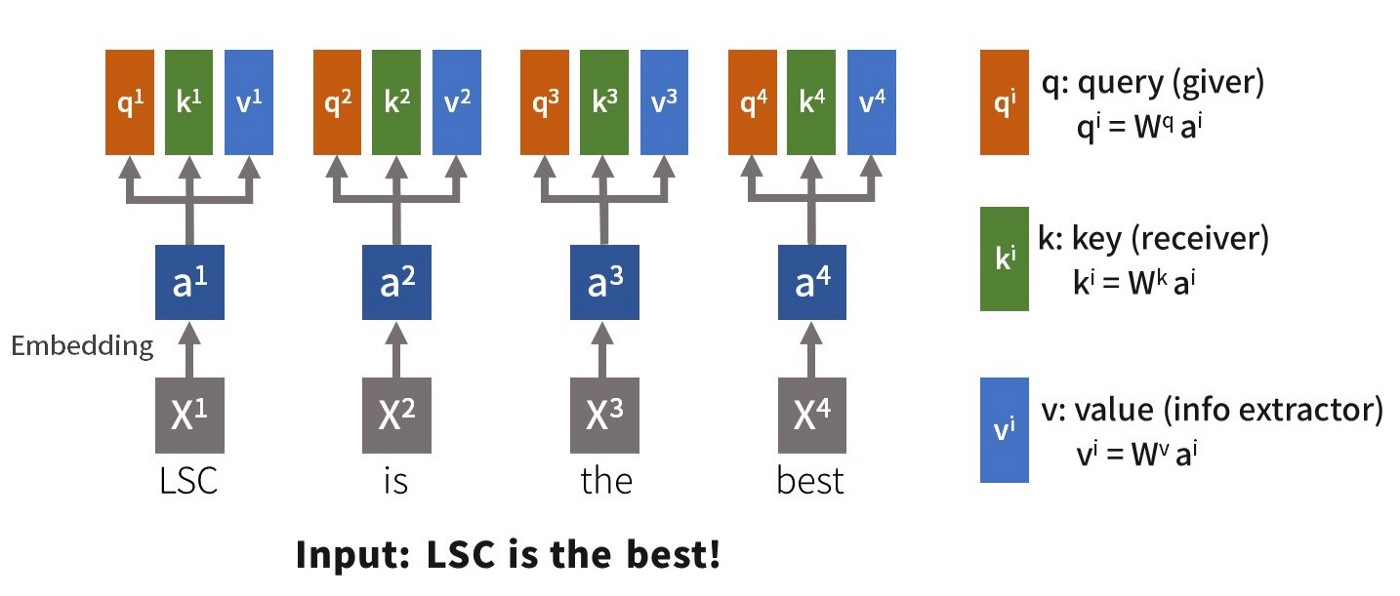
对于每个输入 x \boldsymbol{x} x,首先经过 Embedding 层对每个输入进行编码得到 a 1 , a 2 , a 3 , a 4 \boldsymbol{a_1,a_2,a_3,a_4} a1,a2,a3,a4,后将输入特征经过三个全连接层分别得到 Query,Key,Value:
- q i ( Q u e r y ) = W q a i \boldsymbol{q^i(Query) = W^q a^i} qi(Query)=Wqai;
- k i ( K e y ) = W k a i \boldsymbol{k^i(Key) = W^k a^i} ki(Key)=Wkai;
- v i ( V a l u e ) = W v a i \boldsymbol{v^i(Value) = W^v a^i} vi(Value)=Wvai。
W q , W k , W v \boldsymbol{W^q, W^k,W^v} Wq,Wk,Wv 由网络训练而来。注意力矩阵是由 Query 和 Key 计算得到,方式由许多种,如点积、缩放点积等。Value 可以看作是信息提取器,将根据单词的注意力提取一个唯一的值,也即某个特征有多少成分被提取出来。下面计算一种注意力矩阵的方式:缩放点积。

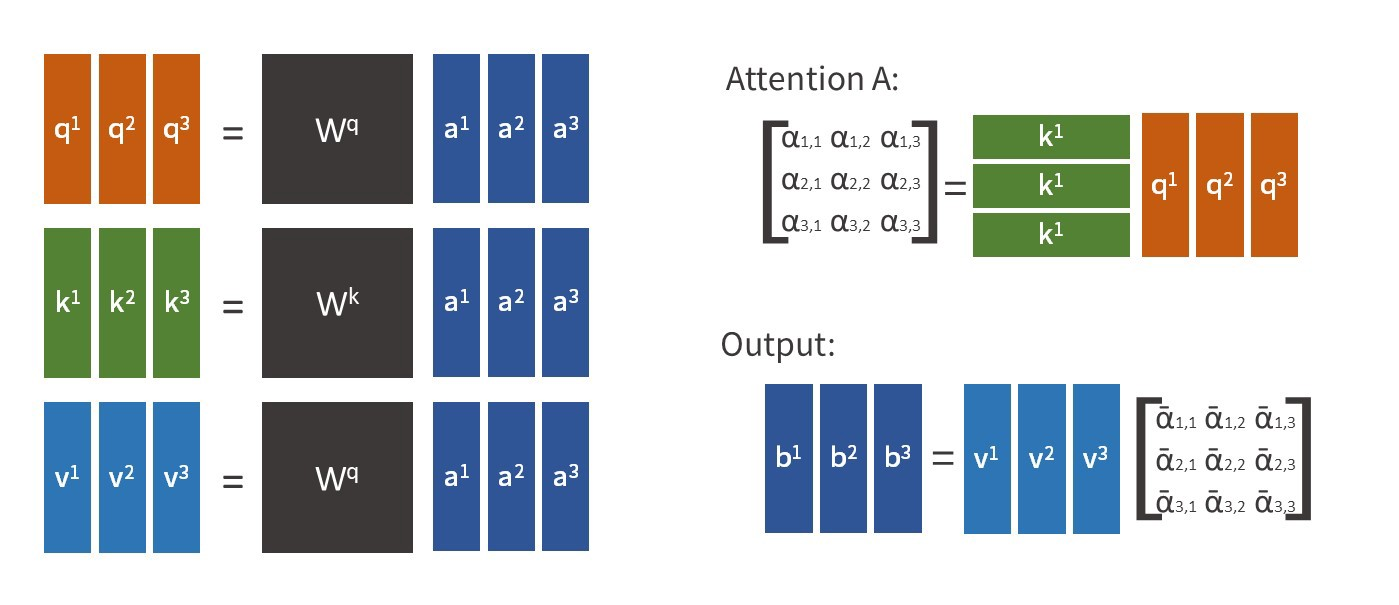
注意力矩阵 A \boldsymbol{A} A 定义为 Query (giver) 和 Key (receiver) 的内积除以其维度的平方根。 每个单词通过提供 Query 来匹配作为注意力的目标单词的 Key,从而对所有单词产生注意力。为防止注意力分数随维度增大而增大,让注意力矩阵除以向量的维度的开方。 然后对得到的注意力矩阵 A \boldsymbol{A} A 进行 Softmax 归一化得到 A ^ \boldsymbol{\hat{A}} A^,最后将 A ^ \boldsymbol{\hat{A}} A^ 乘以 Value 矩阵并相加得到最终的特征 b \boldsymbol{b} b。

矩阵化如下:
在上述的 self-attention 中,我们最终只得到一个注意力矩阵,也就是说这个注意力矩阵所关注的信息只偏句子之间的一种关系,但是在时序序列中,往往特征之间不止一种关系,所以我们要提取多个注意力矩阵,这样可以捕获更多的信息,这种注意力机制也就是 多头注意力机制(Multi-Heads)。在实现过程中,我们只需要将原始的 q i , k i , v i \boldsymbol{q^i,k^i,v^i} qi,ki,vi 分裂为 n \boldsymbol{n} n 个就得到 n \boldsymbol{n} n 头自注意力机制了。

2 PyTorch 实现
定义 num_attention_heads 为注意力机制的头数,input_size 为输入特征维度,hidden_size 为 q i , k i , v i \boldsymbol{q^i,k^i,v^i} qi,ki,vi 的总维度,这样每个头的维度也可以求出,定义为 attention_head_size:
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = hidden_size
定义 W q , W k , W v \boldsymbol{W^q, W^k,W^v} Wq,Wk,Wv,通过全连接网络生成:
self.key_layer = nn.Linear(input_size, hidden_size)
self.query_layer = nn.Linear(input_size, hidden_size)
self.value_layer = nn.Linear(input_size, hidden_size)
使用输入特征乘 W q , W k , W v \boldsymbol{W^q, W^k,W^v} Wq,Wk,Wv 得到 Query,Key,Value 矩阵,维度为 ( b a t c h _ s i z e , s e q _ l e n , h i d d e n _ s i z e ) (batch\_size,seq\_len, hidden\_size) (batch_size,seq_len,hidden_size):
key = self.key_layer(x)
query = self.query_layer(x)
value = self.value_layer(x)
求多头注意力机制的 W q , W k , W v \boldsymbol{W^q, W^k,W^v} Wq,Wk,Wv,头数为 num_attention_heads,并要调换维度,即将 s e q _ l e n seq\_len seq_len 维度与 n u m _ a t t e n t i o n _ h e a d s num\_attention\_heads num_attention_heads 维度对换,最终 W q , W k , W v \boldsymbol{W^q, W^k,W^v} Wq,Wk,Wv 维度为 ( b a t c h _ s i z e , n u m _ a t t e n t i o n _ h e a d s , s e q _ l e n , a t t e n t i o n _ h e a d _ s i z e ) (batch\_size,num\_attention\_heads,seq\_len,attention\_head\_size) (batch_size,num_attention_heads,seq_len,attention_head_size):
def trans_to_multiple_heads(self, x):
new_size = x.size()[ : -1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_size)
return x.permute(0, 2, 1, 3)
key_heads = self.trans_to_multiple_heads(key)
query_heads = self.trans_to_multiple_heads(query)
value_heads = self.trans_to_multiple_heads(value)
将 Q \boldsymbol{Q} Q 和 K \boldsymbol{K} K 矩阵做点积运算,并进行缩放,得到注意力矩阵的维度为 ( b a t c h _ s i z e , n u m _ a t t e n t i o n _ h e a d s , s e q _ l e n , s e q _ l e n ) (batch\_size,num\_attention\_heads,seq\_len,seq\_len) (batch_size,num_attention_heads,seq_len,seq_len):
attention_scores = torch.matmul(query_heads, key_heads.permute(0, 1, 3, 2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
对注意力矩阵进行归一化,归一化的维度为 3,矩阵的维度不发生变化:
attention_probs = F.softmax(attention_scores, dim = -1)
将注意力矩阵乘以矩阵 V \boldsymbol{V} V,得到输出特征,维度为 ( b a t c h _ s i z e , n u m _ a t t e n t i o n _ h e a d s , s e q _ l e n , a t t e n t i o n _ h e a d _ s i z e ) (batch\_size,num\_attention\_heads,seq\_len,attention\_head\_size) (batch_size,num_attention_heads,seq_len,attention_head_size):
context = torch.matmul(attention_probs, value_heads)
将各头的注意力矩阵进行拼接,contiguous() 是将 tensor 的内存变成连续的,否则进行 view 操作时会报错,至于原因可参考:https://blog.csdn.net/kdongyi/article/details/108180250:
context = context.permute(0, 2, 1, 3).contiguous()
new_size = context.size()[ : -2] + (self.all_head_size , )
context = context.view(*new_size)
全部代码:
import torch
import numpy as np
import torch.nn as nn
import math
import torch.nn.functional as F
class selfAttention(nn.Module) :
def __init__(self, num_attention_heads, input_size, hidden_size):
super(selfAttention, self).__init__()
if hidden_size % num_attention_heads != 0 :
raise ValueError(
"the hidden size %d is not a multiple of the number of attention heads"
"%d" % (hidden_size, num_attention_heads)
)
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = hidden_size
self.key_layer = nn.Linear(input_size, hidden_size)
self.query_layer = nn.Linear(input_size, hidden_size)
self.value_layer = nn.Linear(input_size, hidden_size)
def trans_to_multiple_heads(self, x):
new_size = x.size()[ : -1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_size)
return x.permute(0, 2, 1, 3)
def forward(self, x):
key = self.key_layer(x)
query = self.query_layer(x)
value = self.value_layer(x)
key_heads = self.trans_to_multiple_heads(key)
query_heads = self.trans_to_multiple_heads(query)
value_heads = self.trans_to_multiple_heads(value)
attention_scores = torch.matmul(query_heads, key_heads.permute(0, 1, 3, 2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = F.softmax(attention_scores, dim = -1)
context = torch.matmul(attention_probs, value_heads)
context = context.permute(0, 2, 1, 3).contiguous()
new_size = context.size()[ : -2] + (self.all_head_size , )
context = context.view(*new_size)
return context
测试:
features = torch.rand((32, 20, 10))
attention = selfAttention(2, 10, 20)
result = attention.forward(features)
print(result.shape)
结果:
torch.Size([32, 20, 20])
参考:
https://blog.csdn.net/beilizhang/article/details/115282604