YOLO1
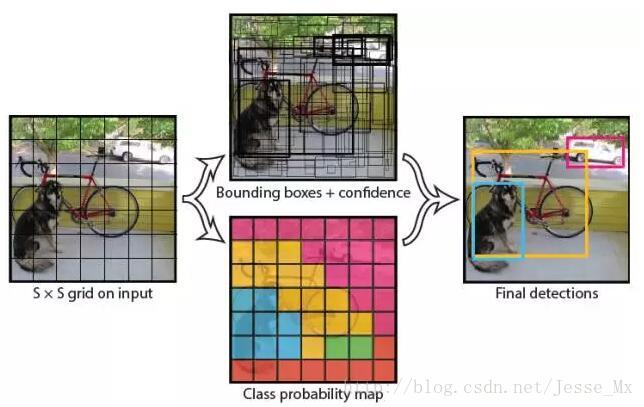
(1) 给一个大小为448X448的输入图像,首先将图像划分成7 * 7的网格。
(2) 对于每个网格,每个网格预测2个bouding box(每个box包含5个预测量)以及20个类别概率,总共输出7×7×(2*5+20)=1470个tensor
(3) 根据上一步可以预测出7 * 7 * 2 = 98个目标窗口,然后根据阈值去除可能性比较低的目标窗口,再由NMS去除冗余窗口即可。
YOLOv1使用了end-to-end的回归方法,没有region proposal步骤,直接回归便完成了位置和类别的判定。种种原因使得YOLOv1在目标定位上不那么精准,直接导致YOLO的检测精度并不是很高。
YOLOv2
1、相比于YOLO引入了anchor box,作者在网络中果断去掉了全连接层。剩下的具体怎么操作呢?首先,作者去掉了后面的一个池化层以确保输出的卷积特征图有更高的分辨率。然后,通过缩减网络,让图片输入分辨率为416 * 416,这一步的目的是为了让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。作者观察到,大物体通常占据了图像的中间位置, 就可以只用中心的一个cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。最后,YOLOv2使用了卷积层降采样(factor为32),使得输入卷积网络的416 * 416图片最终得到13 * 13的卷积特征图(416/32=13)。
加入了anchor boxes后,可以预料到的结果是召回率上升,准确率下降。我们来计算一下,假设每个cell预测9个建议框,那么总共会预测13 * 13 * 9 = 1521个boxes,而之前的网络仅仅预测7 * 7 * 2 = 98个boxes。具体数据为:没有anchor boxes,模型recall为81%,mAP为69.5%;加入anchor boxes,模型recall为88%,mAP为69.2%。这样看来,准确率只有小幅度的下降,而召回率则提升了7%,说明可以通过进一步的工作来加强准确率,的确有改进空间。
2、作者在使用anchor的时候遇到了两个问题,第一个是anchor boxes的宽高维度往往是精选的先验框(hand-picked priors),虽说在训练过程中网络也会学习调整boxes的宽高维度,最终得到准确的bounding boxes。但是,如果一开始就选择了更好的、更有代表性的先验boxes维度,那么网络就更容易学到准确的预测位置。

和以前的精选boxes维度不同,作者使用了K-means聚类方法类训练bounding boxes,可以自动找到更好的boxes宽高维度。传统的K-means聚类方法使用的是欧氏距离函数,也就意味着较大的boxes会比较小的boxes产生更多的error,聚类结果可能会偏离。为此,作者采用的评判标准是IOU(交并集),这样的话,error就和box的尺度无关了,最终的距离函数为:
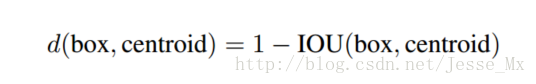
作者通过改进的K-means对训练集中的boxes进行了聚类,判别标准是平均IOU得分,聚类结果如下图:
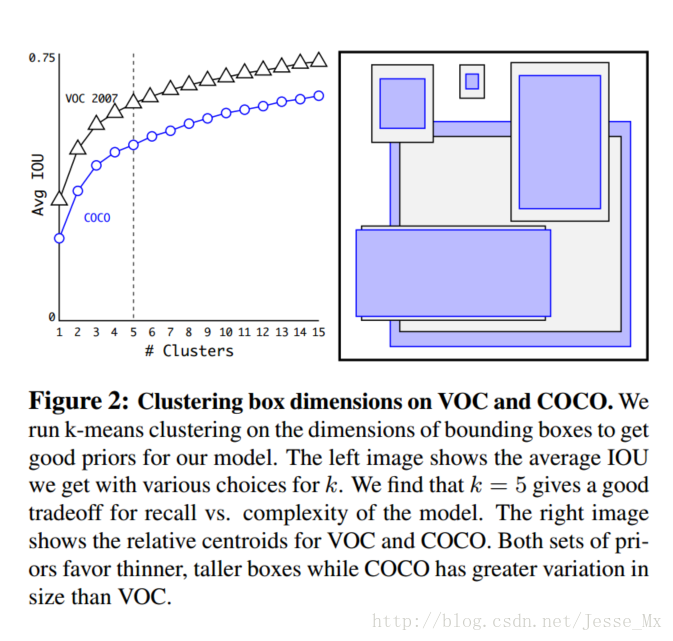
可以看到,平衡复杂度和IOU之后,最终得到k值为5,意味着作者选择了5种大小的box维度来进行定位预测,这与手动精选的box维度不同。结果中扁长的框较少,而瘦高的框更多(这符合行人的特征),这种结论如不通过聚类实验恐怕是发现不了的。
当然,作者也做了实验来对比两种策略的优劣,如下图,使用聚类方法,仅仅5种boxes的召回率就和Faster R-CNN的9种相当。说明K-means方法的引入使得生成的boxes更具有代表性,为后面的检测任务提供了便利。
YOLOv3