贝叶斯分类器是一种概率模型,利用贝叶斯公式来解决分类问题。假设样本的特征向量服从一定的概率分布,我们就可以计算出该特征向量属于各个类的条件概率。分类结果是条件概率最大的分类结果。如果假设特征向量的每个分量彼此独立,则它是朴素贝叶斯分类器。如果假设特征向量服从多维正态分布,则它是正态贝叶斯分类器。
一、原理:
贝叶斯公式(Bayes' theorem)


贝叶斯决策

朴素贝叶斯分类器

朴素贝叶斯分类器特征向量为离散型随机变量

拉普拉斯平滑

朴素贝叶斯分类器特征向量为连续型随机变量

ln函数的性质

朴素贝叶斯分类器特征向量为连续型随机变量,对于二分类问题,正态贝叶斯分类器


协方差朴素贝叶斯

协方差朴素贝叶斯的训练过程

协方差朴素贝叶斯的预测算法

二、示例程序:
Scikit-learn中提供了多种朴素贝叶斯分类器,其中包括高斯朴素贝叶斯(Gaussian Naive Bayes)分类器。然而,对于鸢尾花数据集,由于其特征是连续型的,因此通常使用的是高斯朴素贝叶斯分类器。

以下是在Scikit-learn中使用高斯朴素贝叶斯分类器对鸢尾花数据集进行分类的示例:
# 导入必要的模块
import numpy as np # 导入NumPy库,并将其命名为np,这是一个用于科学计算的库,提供了多维数组和数学函数的支持
import matplotlib.pyplot as plt # 导入Matplotlib库的pyplot模块,并将其命名为plt,用于创建静态、交互式和动画图表的绘图库。
from sklearn import datasets # 从Scikit-learn库中导入datasets模块,该模块包含了一些标准的数据集,包括机器学习领域常用的一些数据集
from sklearn.naive_bayes import GaussianNB # 从Scikit-learn库中导入朴素贝叶斯分类器的高斯朴素贝叶斯模型。
import matplotlib # 导入Matplotlib库,这是一个用于绘制图表的广泛使用的库。
%matplotlib inline # 一个Jupyter Notebook魔术命令,用于在Notebook中嵌入Matplotlib图形,并在代码执行后直接在Notebook中显示图形
# 定义生成测试样本点的函数
def make_meshgrid(x, y, h=.02):
# 计算x、y的最小值和最大值
x_min, x_max = x.min() - 1, x.max() + 1
y_min, y_max = y.min() - 1, y.max() + 1
# 生成均匀网格
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 返回网格坐标
return xx, yy
# 定义预测测试样本并显示的函数
def plot_test_results(ax, clf, xx, yy, **params):
# 对测试样本进行预测 xx.ravel() 和 yy.ravel() 用于将二维的坐标网格
# 矩阵展平为一维数组。这是因为 clf.predict() 方法接受一维数组形式的输入
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# 将预测结果转换为网格图像
Z = Z.reshape(xx.shape)#返回坐标网格 xx 的形状,即一个包含行数和列数的元组。
# 在网格图像上绘制等高线
ax.contourf(xx, yy, Z, **params)
# 载入iris数据集
iris = datasets.load_iris()
# 只使用前面两个特征 即鸢尾花数据集的萼片长度和萼片宽度。
X = iris.data[:, :2]#选择所有行(即所有样本)和前两列的数据
# 样本标签值
y = iris.target
# 创建并训练正态朴素贝叶斯分类器
clf = GaussianNB()
clf.fit(X,y)
# 图形标题
title = ('GaussianBayesClassifier')
# 创建图形 fig 是整个图形对象,而 ax 是包含的子图对象 子图的大小为 (5, 5)
fig, ax = plt.subplots(figsize = (5, 5))
# 调整子图布局 0.4 表示子图之间的宽度/高度间距为整个子图宽度/高度的 0.4 倍
plt.subplots_adjust(wspace=0.4, hspace=0.4)
# 获取第0、1个特征的值
X0, X1 = X[:, 0], X[:, 1]
# 生成测试样本点
xx, yy = make_meshgrid(X0, X1)
# 显示测试样本的分类结果
plot_test_results(ax, clf, xx, yy, cmap=plt.cm.coolwarm, alpha=0.8)
#绘制散点图 显示训练样本
# X0 和 X1 分别是训练样本的前两个特征变量
# c=y 指定了散点的颜色,使用了目标标签 y 中的类别信息。不同的类别用不同的颜色表示。
# cmap=plt.cm.coolwarm 指定了颜色映射,用于将类别映射到具体的颜色。
# s=20 设置了散点的大小为 20。
#edgecolors='k' 设置了散点的边缘颜色为黑色 ('k' 表示黑色)。
ax.scatter(X0, X1, c=y, cmap=plt.cm.coolwarm, s=20, edgecolors='k')
# 设置图形属性
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_xticks(())# 将 x 轴的刻度标签设为空
ax.set_yticks(())
ax.set_title(title)
# 显示图形
plt.show()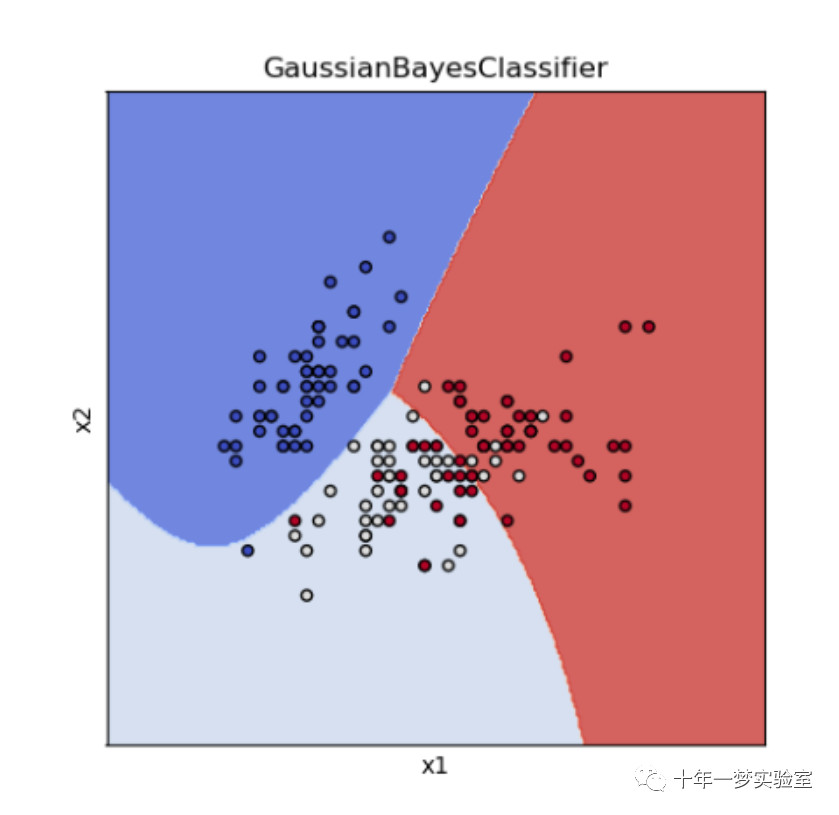
三、贝叶斯分类器的应用

参考网址:
https://programmer.group/principle-of-machine-learning-bayesian-classifier-and-its-sklearn-implementation.html Principle of machine learning Bayesian classifier and its sklearn implementation --- 机器学习贝叶斯分类器原理及其sklearn实现 (programmer.group)
https://zhuanlan.zhihu.com/p/25462307 OpenCV机器学习——朴素贝叶斯NBC - 知乎 (zhihu.com)
https://blog.csdn.net/qinzhongyuan/article/details/106434854 鸢尾花(Iris)数据集_iris数据集-CSDN博客
https://zhuanlan.zhihu.com/p/480326305 数据集 |鸢尾花数据集 - 知乎 (zhihu.com)
The End