一 贝叶斯定理
设X是数据样本,用n个属性集的测量值描述。令H为某种假设,如数据样本属于某个特定类C。给定X的属性描述,找出样本属于类C的概率。贝叶斯定理用公式表示:
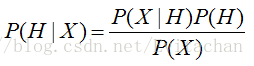
二 朴素贝叶斯分类
设D是数据集,每个样本用一个n维向量X={x1,x2,...,xn}表示,对应n个属性A1,A2,...,An。假设有m个类C1,C2,...,Cm。朴素贝叶斯分类法预测X属于类Ci,当且仅当
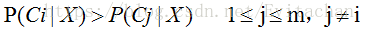
根据贝叶斯定理
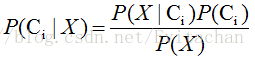
由于P(X)对所有类为常数,只需要P(X|Ci)P(Ci)最大即可。
朴素贝叶斯假设各属性之间独立,则有
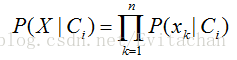
三 贝叶斯分类器算法实现
用贝叶斯分类器预测泰坦尼克号生存情况。
import csv
import math
def loadCsv(filename):
lines = csv.reader(open(filename, "r"))
dataset = list(lines)
for i in range(len(dataset)):
dataset[i] = [float(x) for x in dataset[i]]
return dataset
def separateByClass(dataset):
separated = {}
for i in range(len(dataset)):
vector = dataset[i]
if (vector[-1] not in separated):
separated[vector[-1]] = []
separated[vector[-1]].append(vector)
return separated
def mean(numbers):
return sum(numbers)/float(len(numbers))
def stdev(numbers):
avg = mean(numbers)
variance = sum([pow(x-avg,2) for x in numbers])/float(len(numbers)-1)
return math.sqrt(variance)
def summarize(dataset):
summaries = [(mean(attribute), stdev(attribute)) for attribute in zip(*dataset)]
del summaries[-1]
return summaries
def summarizeByClass(dataset):
separated = separateByClass(dataset)
summaries = {}
for classValue, instances in separated.items():
summaries[classValue] = summarize(instances)
return summaries
def calculateClassProbabilities(summaries, inputVector):
probabilities = {}
for classValue, classSummaries in summaries.items():
probabilities[classValue] = 1
for i in range(len(classSummaries)):
mean, stdev = classSummaries[i]
x = inputVector[i]
exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2))))
probabilities[classValue] *= (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
return probabilities
def classify0(summaries, inputVector):
probabilities = calculateClassProbabilities(summaries, inputVector)
bestLabel, bestProb = None, -1
for classValue, probability in probabilities.items():
if bestLabel is None or probability > bestProb:
bestProb = probability
bestLabel = classValue
return bestLabel
def test():
trainingSet = loadCsv('titanictrain_3.csv')
testSet =loadCsv('test_3.csv')
summaries = summarizeByClass(trainingSet)
correct = 0
for i in range(len(testSet)):
result = classify0(summaries, testSet[i])
print("计算值: %d, 真实值: %d" % (result, testSet[i][-1]))
if testSet[i][-1] == result:
correct += 1
accuracy=(correct/float(len(testSet))) * 100.0
print('正确率:%f' % accuracy)
test()
正确率:85%
注意:使用拉普拉斯校准避免计算零概率值。假设某个属性具有3种取值,在数据集D中出现次数为0,10,990,使用拉普拉斯校准后,得到如下概率1/1003,11/1003,991/1003。校准后的概率与实际值很接近,但是避免了零概率值。
参考资料:
【1】《机器学习实战》 Peter Harrington 著 人民邮电出版社
【2】《机器学习》 周志华 著 清华大学出版社
【3】《数据挖掘概念与技术》 Jiawei Han等 著 机械工业出版社