贝叶斯分类的先导知识
条件概率
所谓条件概率,它是指某事件B发生的条件下,求另一事件A的概率,记为
P(A|B)
,它与
P(A)
是不同的两类概率。
举例: 考察有两个小孩的家庭, 其样本空间为
Ω=[bb,bg,gb,gg]
, 其中b 代表男孩,g代表女孩,bg表示大的是男孩、小的是女孩,其它点可类似说明
在
Ω
中4个样本点等可能的情况下,我们来讨论一些事件的概率。
- 事件 A = “家中至少有一个女孩”发生的概率为
P(A)=34
- 若已知事件 B = “家中至少有一个男孩” 发生, 再求事件 A 发生的概率为
P(A|B)=23
这是因为事件B的发生,排除了gg发生的可能。这是样本空间
Ω
也随之改为
ΩB=[bb,bg,gb]
, 而在
ΩB
中事件A中只含2个样本点,故
P(A|B)=23
。这就是条件概率,它与无条件概率
P(A)
是不同的两个概念。
- 若对上述条件概率的分子分母各除以4, 则可得
P(A|B)=P(AB)P(B)=2/43/4
其中交事件AB = “家中既有男孩又有女孩”。这个关系具有一般性,也就是说,条件概率是两个无条件概率之商。
全概率公式
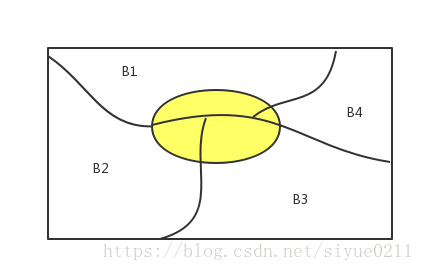
全概率是概率论中一个重要的公式, 它提供了计算复杂事件概率的一条有效途径,使一个复杂事件的概率计算问题化简就繁。
性质:设
B1,B2,...,Bn
为样本空间
Ω
的一个分割,即
B1,B2,..,Bn
互补相容,且
⋃ni=1Bi=Ω
,如果
P(Bi)>0
, i = 1, 2, ..n, 对任一事件A有
P(A)=∑i=1nP(Bi)P(A|Bi)
 证明:
证明:因为
A=AΩ=A(⋃i=1nBi)=⋃i=1n(ABi)
且
AB1,AB2...,ABn
互不相容,所以由可加得
P(A)=P((⋃i=1n(ABi))=∑i=1nP(ABi)
,再将
P(ABi)=P(Bi)P(A|Bi),i=1,2,...n
带入上式即可
贝叶斯公式
在乘法公式和全概率公式的基础上立即可推一个很著名的公式。
性质:设
B1,B2,...Bn
是样本空间
Ω
的一个分割,即
B1,B2,...Bn
互补相容,且
⋃ni=1=Ω
,如果
P(A)>0,P(Bi)>0
, i = 1, 2, 3, .., n,则
P(Bi|A)=P(Bi)P(A|Bi)∑nj=1P(Bj)P(A|Bj)
证明:由条件概率的定义
P(Bi|A)=P(ABi)P(A)
对上面的式子的分子用乘法公式,分母用全概率公式。
P(ABi)=P(Bi)P(A|Bi)
P(A)=∑j=1nP(Bj)P(A|Bj)
举例:某地区的肝癌发病率为0.0004,现在用甲胎蛋白法进行普查,医学研究表明,化验结果是存在错误的,已知患有肝癌的人其检验结果99%呈阳性(有病),而没患肝癌的人其化验结果99%呈阴性(无病)。现某人的检查结果为呈阳性,问他真的患肝癌的概率有多少?
解:记B为事件被检查者患有肝癌, A为事件检查结果呈阳性。
P(B)=0.0004
P(B′)=0.9996
P(A|B)=0.99
P(A|B′)=0.001
扫描二维码关注公众号,回复:
1506913 查看本文章

我们现在要求:
P(B|A)=P(B)P(A|B)∑2j=1P(Bj)P(ABj)
P(B|A)=P(B)P(A|B)P(B)P(A|B)+P(B′)P(A|B′)
P(B|A)=0.0004×0.990.0004×0.99+0.996×0.001=0.284
在上面的例子中,如果我们将事件B“被检测患有肝癌”作为原因,将事件A“检查结果呈阳性”作为最后的结果。则我们在用贝叶斯公式在已知“结果”的条件下,求出了原因的概率P(B|A).
在贝叶斯公式中,如果称
P(Bi)
为
Bi
的先验概率,称
P(Bi|A)
为
Bi
的后验概率,则贝叶斯公式是专门用来计算后验概率的,也就是通过A的发生这个新信息对
Bi
的概率作出修正。
最大似然估计
最大似然估计是求估计常用的一种方法。 为了叙述最大似然估计的直观想法, 先看两个例子。
例子:设有外形完全相同的两个箱子,甲箱中有99个白球和一个黑球,乙箱有99黑球和一个白球。今随机抽取一箱,并从中随机抽取一球,结果取得白球,问这球是从哪个箱子中取出的?
解:不管是哪个箱子,从箱子中任取一个球都有两个可能的结果:A表示取出白球,B表示取出黑球。如果我们取出的是甲箱子,则A发生的概率0.99,如果我们取出的是乙箱,则A发生的概率0.01。现在一次实验中结果A发生了,人们的第一印象是:这个求最像从甲箱中取出的。或者说,应该认为试验条件对结果A出现有利。从而可以推断这球是从甲箱子中取出的。这个推断很符合人们的经验事实,这里“最像”就是最大似然的意思。
例子:
设一个试验有三种可能的结果,其概率分别为:
p1=θ2
,
p2=2θ(1−θ)
,
p3=(1−θ)2
。现做了n次试验,观察到三种结果发生的次数分别是
n1,n2,n3(n1+n2+n3=n)
,则似然函数是
L(θ)=(θ2)n1[2θ(1−θ)]n2[(1−θ)2]n3
L(θ)=2n2θ2n1+n2(1−θ)2n3+n2
我们现在希望
L(θ)
尽可能的大,它现在表示的就是从当前的结果看,最拟合真实概率分布的函数式。
L(θ)
称为样本的最大似然函数。则我们当前的目标是求得一个
θ
使得
L(θ)
最大。
则对数似然函数为
lnL(θ))=(2n1+n2)lnθ+(2n3+n2)ln1−θ+n2ln2
将之关于
θ
求导,并令其为0得到似然方程。
2n1+n2θ−2n3+n21−θ=0
结果
θ=2n1+n22n
再对
L(θ)
求二阶导数,小于0,所以是极大值点。
下一集:贝叶斯分类器2
参考
- 概率论与数理统计教程
- 机器学习实战
- 机器学习(西瓜书)