项目地址:https://ilovepose.github.io/coco/
论文总结
本文方法名为DARK,其提出一种编码和解码的方法,使得坐标到heatmap(用于训练)和heatmap到坐标(用于测试)能更加准确的表达。
论文中表达DARK可以减轻网络输入分辨率变小的损失(从 384 ∗ 288 384*288 384∗288到 256 ∗ 192 256*192 256∗192到 128 ∗ 96 128*96 128∗96);
论文内容
坐标解码
如果训练的模型效果好的话,网络预测的heatmap会与label同分布,即heatmap会如下公式所示,其中 x x x是heatmap中的预测元素坐标; μ \mu μ是高斯核中的中心坐标,即估计的keypoint位置;协方差 ∑ \sum ∑是一个对角矩阵, ∑ = [ σ 2 0 0 σ 2 ] \sum = \left[ \begin{matrix} \sigma^2 & 0 \\ 0 & \sigma^2 \end{matrix} \right] ∑=[σ200σ2]
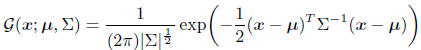
利用对数似然优化原则,可以将上述公式使用对数转换,来推测最大值位置:
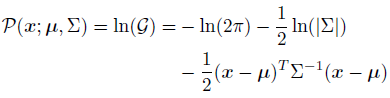
μ \mu μ是我们所需要预测的关键点位置,由于其是极值,则一阶导数为:

在 μ \mu μ上使用二阶泰勒公式,其中 m m m为最大值:
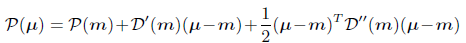
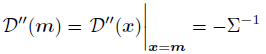
最后就得到了我们所想要预测的关键点位置坐标:
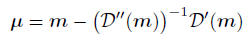
上述推导是基于预测的heatmap是一个理想的高斯分布的情况下的,现实情况下预测的heatmap会在最大值附近出现多个峰值,这对上述的decode方法会产生负面影响,所以因此要进行heatmap的处理。文中使用高斯核对heatmap进行预处理,来平滑多个峰值。高斯核的kernel_size一般与训练时的kernel_size对应。
所以,DARK的decoding分为三步:
- 先平滑heatmap分布【高斯核处理】
- 泰勒展开获得关键点的定位
- 分辨率的恢复(输入图片分辨率恢复到原图分辨率)

坐标编码
在从原图分辨率的坐标 ( u , v ) (u,v) (u,v),映射到网络输入分辨率 ( u ′ , v ′ ) (u',v') (u′,v′)的坐标时,坐标会从整数映射成浮点数。映射函数如下图所示
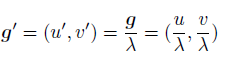
但一般使用 ( u ′ , v ′ ) (u',v') (u′,v′)产生heatmap时,会将坐标整数化,得到一个元素坐标,再使用高斯函数产生heatmap。这个整数的坐标和实际坐标时有一个偏差的,所以DARK在产生heatmap时,直接使用浮点数产生heatmap:
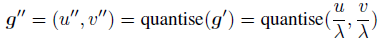
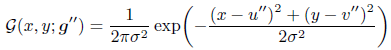
实验结果
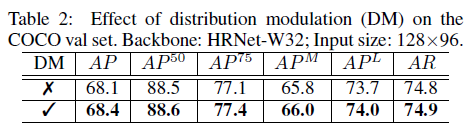
使用高斯核平滑的对比实验结果如下,表2表示高斯核平滑处理可以提高0.3%的AP
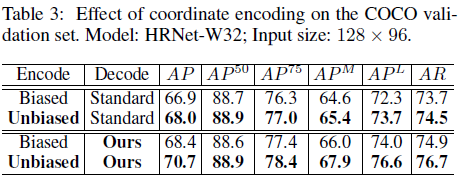
DARK的decoding和encoding的对比实验结果如下,可以看出encoding和decoing都是对结果有提升的。
不同分辨率使用DARK方法的对比实验结果如下,可以看出dark在小分辨率的模型上有更高的受益;
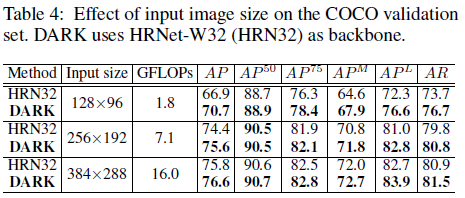
从下表可以看出,当指标体现越严格时,DARK的优势会越明显,表明DARK方法对于keypoint预测的稳定性是有帮助的。

下表是DARK应用于各个网络上的结果,可以看出DARK是模型无关的方法,可以应用于各种模型中;

