1. 研究背景
1.GoogLeNet-V1 采用了多尺度卷积核,1*1卷积操作,辅助损失函数,实现了更深的22层卷积神经网络。那么v2就在v1的基础上加入了BN层,同时借鉴了VGG小卷积核的思想,将5*5卷积替换成2个3*3卷积。
2.深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。Google 将这一现象总结为 Internal Covariate Shift,简称 ICS
3.白化:去除输入数据的冗余信息,使得数据特征之间的相关度较低,所有特征具有相同方差。本篇论文将数据变为0均值,1标准差的形式,实现白化.
依概率论:N(x)=(x-mean)/std 使X变为0均值,1标准差。mean-mean=0,std*(1/std)=1
白化相当于是数据的预处理,在数据输入模型之前就会对数据进行操作.
bn是在模型当中对网络层的输出神经元的值,在输入到激活函数之前,把数据进行一些操作处理
2.研究的成果和意义
(1)成果
1.提出BN层,加快模型收敛,比googlenet-v1快数10倍,获得更优的结果
2.googLeNet-v2 获得ILSVRC分类任务SOTA
(2)研究意义
1.加快了深度学习的发展
2.开启神经元网络设计新时代,标准化层已经成为深度神经网络标配
3.BN层
BN层也就是 Batch Normalization的缩写,其中的Normalization被称为标准化,通过将数据进行平和缩放拉到一个特定的分布。
BN就是在batch维度上进行数据的标准化。BN的引入是用来解决 internal covariate shift
问题,即训练迭代中网络激活的分布的变化对网络训练带来的破坏。
BN通过在每次训练迭代的时候,利用minibatch计算出的当前batch的均值和方差,进行标准化来缓解这个问题。
Batch Normalization—批标准化
-
批—>mini-batch
批量数据,即每一次优化的样本数数量
把数据分成若干组,按组来更新参数,一组中的数据共同决定了本次梯度的方向,下降时减少了随机性.另一方面,因为批的样本数与整个数据集相比少了很多,计算量也下降了很多. -
标准化—>分布mean=0,std=1 0均值 1标准差
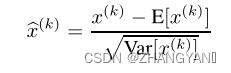
如1,2;mean=1.5 std=0.5 变换到-1,1 一定有正有负,并且拉到0附近.
BN的理解
BN就是为了解决偏移的,解决的方式也很简单,针对每个神经元,使数据在进入激活函数之前,沿着通道计算每个batch的均值、方差,‘强迫’数据保持均值为0,方差为1的正态分布,避免发生梯度消失。(BN是根据划分数据的集合去做Normalization,不同的划分方式也就出现了不同的Normalization,如GN,LN,IN)
[N, H, W, C],其中N是batch_size,H、W是行、列,C是通道数,BN是对NHW进行归一化;对batch中对应的channel归一化

如果把特征图 比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行有W 个字符。
BN 求均值时,相当于把这些书中的字符按页码加起来(例如第1本书第36页,第2本书第36页…),再除以N个书中每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
举个例子:该批次内有10张图片,每张图片有三个通道RBG,每张图片的高、宽是H、W,那么均值就是计算10张图片R通道的像素数值总和除以10*H*W ,再计算B通道全部像素值总和除以10*H*W.
最后计算G通道的像素值总和除以10*H*W,方差的计算类似。
BN的使用位置:全连接层或卷积操作之后,激活函数之前。
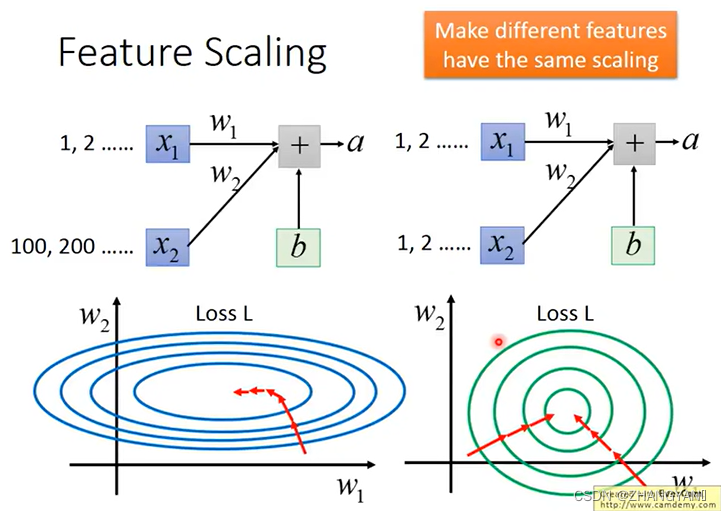
为什么要做特征归一化呢
如下图所示,如果输入两组数据x1,x2,如果x1的数特别大,x2的数特别小,那么当x1与w1相乘时,随之w1的增大,对loss影响小,体现在图像上就是斜率变化不大.同样由于x2的数特别大,随着w2的增大,对loss影响大,体现在图像上就是斜率变化大.
那么在进行梯度下降的时候,向左右的偏移和向前后的偏移不同,不方便梯度下降,效果不好.
但是如果x1和x2输入的数大小都差不多的时候,整体图像接近于园形,上下左右偏移相同,可以更快的进行收敛.
BN算法过程:

- 沿着通道计算每个batch的均值
- 沿着通道计算每个batch的方差
- 做归一化
- 加入缩放和平移变量 γ和β
其中∈是一个很小的正值,比如
10^(-8)。加入缩放和平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。
这两个参数是用来学习的参数。
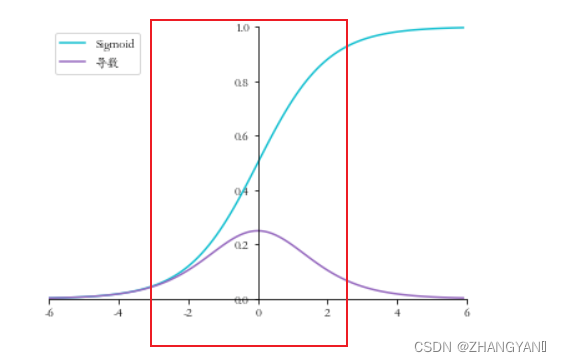
这样把数据都拉到0的附近 因此这会使神经元输出值在sigmoid线性区
消弱了网络的表达能力
加入缩放和平移变量γ和β的作用
(1)提升网络的表达能力
因为BN在归一化时会破坏参数分布,这样的normalization可能会改变这一层网络的表达能力,比如对于一个sigmoid激活函数,可能就把限制在了它的线性区域,失去了非线性激活的能力。因此我们要赋予normalization能够进行单位变换(identity transform)的能力。这可以通过在后面再加一层缩放和平移实现。
如果数据都落在了方块图的区域,那么就来到了sigmoid的线性区域,那么激活函数就为线性的激活函数,那么会使模型退化,也就会造成无论有多少个网络层等价于一个网络层.
(2)保证了模型的capacity
γ和β作为调整参数可以调整被BN刻意改变过后的输入,即能够保证能够还原成原始的输入分布。BN对每一层输入分布的调整有可能改变某层原来的输入,当然有了这两个参数,经过调整也可以不发生改变,既可以改变同时也可以保持原输入,那么模型的容纳能力(capacity)就提升了。
当
将他们带入下面的这个公式 那么输入和输出相等
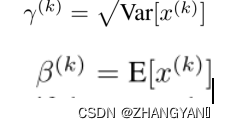
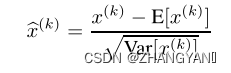
(3)适应激活函数
如果是sigmoid函数,那么BN后的分布在0-1之间,由于sigmoid在接近0的地方趋于线性,非线性表达能力可能会降低,因此通过γ和β可以自动调整输入分布,使得非线性表达能力增强。
如果激活函数为ReLU,0均值1方差意味着将有一半的数值在负半轴失活无法使用,那么通过β可以进行调整参与激活的数据的比例,防止dead-Relu问题
BN的作用:
(1)允许较大的学习率;
(2)减弱对初始化的强依赖性
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础;
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
BN存在的问题:
(1)每次是在一个batch上计算均值、方差,如果batch size太小,则计算的均值、方差不足以代表整个数据分布。
(2)batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;会直接固定梯度下降的方向,导致很难更新。
训练和测试阶段的不同
在训练阶段,BN层是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。(每一批数据的方差和标准差不同)
而在测试阶段,我们一般只输入一个测试样本,并没有batch的概念。因此这个时候用的均值和方差是整个数据集训练后的均值和方差,可以通过滑动平均法求得:
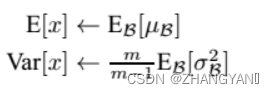
上面式子简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。
在测试时,BN使用的公式是:
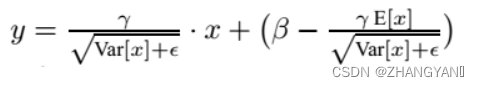
4.v2模型特点
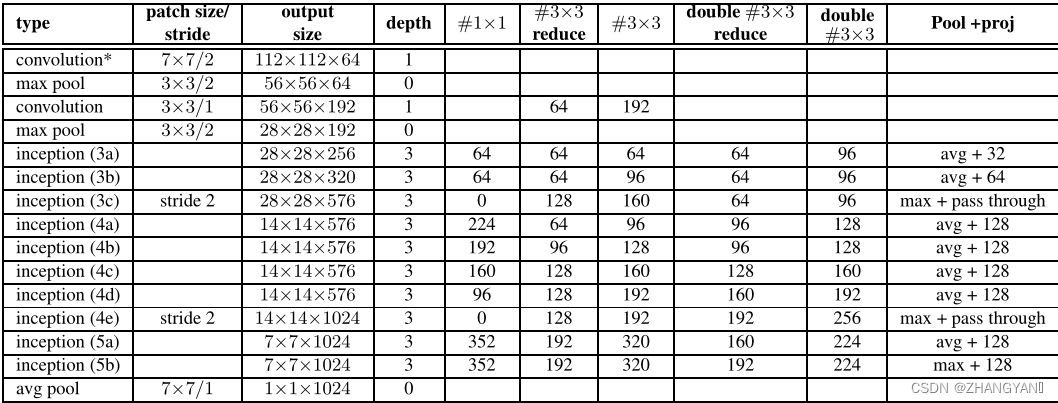
对v1的改进:
- 激活函数前加入BN
- 5*5卷积替换为2个3*3卷积
- 第一个Inception模块增加一个Inception结构
- 增多5*5卷积核
- 尺寸变化采用stride=2的卷积,而不采用池化
- 增加9层(10-1层)到31层
5.实验结果及分析
(1)MINIST 更快更稳定
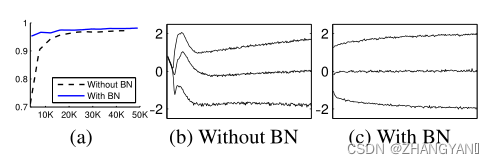
从(a)可以看出达到相同的准确率时,有BN训练的次数要远远小于没有BN的训练次数.
(b) 和(c )代表了数据分布 没有BN的时候数据分布不稳定,加入BN后数据分布稳定.
(2)ILSVRC:更快精度更高
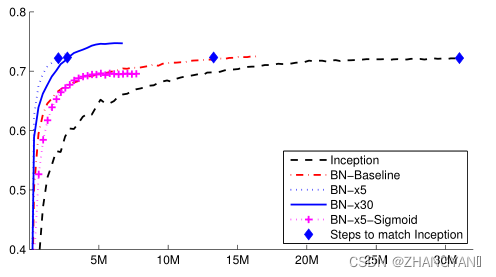

参数设置:初始学习率=0.0015
x5:代表学习率=0.0015*5=0.0075
1.加入BN更快:BN-Baseline 比Inception快一倍
2.可用大学习率:BN-X5比Inception快14倍
3.加BN精度更高:BN-X30比x5慢,但精度高
4.sigmoid时,加入BN精度更高,BN-X5-sigmoid的虽然精度低,但是也比Inceptipn-Sigmoind高很多
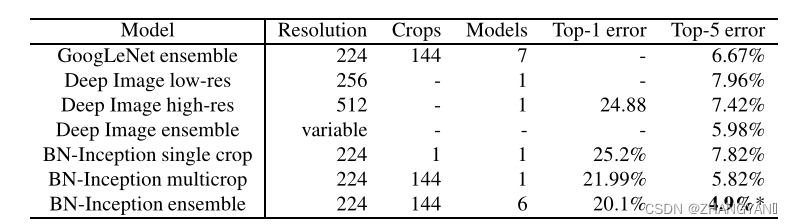
(3)模型集成:(超越人类精度)
由六个BN-X30集成.
六个模型的不同之处:
增大权重初始化的值,即分布的标准差变大;dropout设为5%或者10%.
6.总结
1.提出了BN层,缓解ICS带来的训练困难,
- 可以用更大的学习率,加快模型收敛
- 可以不用精心设计权值初始化
- 可以不用dropout或较小的dropout
2.借鉴了VGG,全面将5*5替换为两个3*3的卷积堆叠