Google的Inception是比较特别的网络结构,利用多个size不同的卷积核对input进行处理,最后在channel上进行拼接。可以有效减少参数量,从而防止过拟合且节省计算资源。
关于Inception v1和v3,这篇文章写的非常好:GoogLeNet Inception v1及v3
本文主要很浅很浅地介绍下v4以及与ResNet相结合的网络。(因为Inception的motivation主要体现在前面的paper中)
一、简单回顾
v1中,利用1x1、3x3、5x5的卷积核减少参数量。
虽然5x5的感受野更大,意味着其看到的信息也更多,能够获得更好的特征。
但是,5x5也意味着参数量会更多。
因此,在v3中,用两个3x3的卷积核代替5x5。既保证了感受野,也减少了参数量,且实验证明,这样的替代不会造成表达能力缺失。
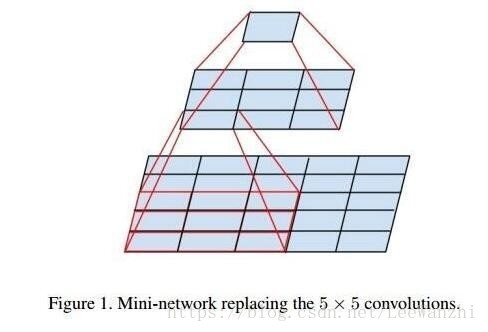
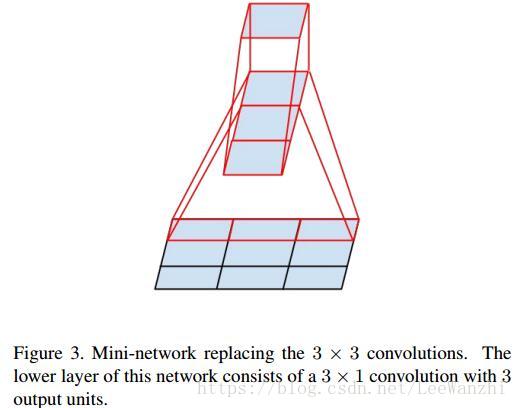
其次,v3还利用1xn与nx1的卷积核替代nxn的卷积核,挺6的。
二、Inception v4
每个部分都是原有的GoogLeNet特色,其实也没什么好说的。这个网络结构分类效果很好,与Inception-ResNet-v2相当,证明了要想把网络做深,不一定非要用残差结构。
三、Inception-ResNet-v2
由于ResNet确实很棒,所以Inception与其结合。在原有的inception块中引入残差结构。
通过这个图,一目了然。
在实验中,我们发现。
与残差网络相结合的inception 收敛速度更快。Inception v4虽然最终也能降到和inception-resnet一样的错误率,但是收敛过程比inception-resnet慢的多。