《A review of convolutional neural network architectures and their optimizations》论文指出AlexNet的优异性能证明了可以通过增加网络深度提高网络性能。随着网络层数的不断增加,不断增加的计算负担和不显著的性能提升使得更先进的网络架构成为另一个主要的研究方向。卷积分裂的思想作为扩大网络深度的一个至关重要的解决方案应运而生。因此,本文将介绍上述论文中综述的几款卷积分离网络架构:VGGNet、GoogLeNet、GoogleNet v2、GoogleNet v3、GoogleNet v4、Inception-ResNet。
目录
1.VGGNet
2014 - ILSVRC竞赛中获得第二名。VGG可以看作是AlexNet的一个深化版本,它使用多个连续的3 × 3卷积核来代替网络中较大的核(11×11,7×7,5×5)。VGGNet将网络分为5段,每段连接多个3 × 3卷积核。每段卷积后面有一个最大池化层,最后增加3个FC层和一个softmax层。
1.1 网络架构
如下图所示为VGGNet的网络架构,根据卷积层不同的子层数量,设计了A、A-LRN、B、C、D、E这6种网络结构,其中D和E即为VGG-16和VGG-19:
这6种网络结构相似,都是由5层卷积层、3层全连接层组成,区别在于每个卷积层的子层数量不同,从A至E依次增加,总的网络深度从11层到19层。表格中的卷积层参数表示为“conv(感受野大小)-通道数”,例如con3-64,表示使用3x3的卷积核,通道数为64;最大池化表示为maxpool,层与层之间使用maxpool分开;全连接层表示为“FC-神经元个数”,例如FC-4096表示包含4096个神经元的全连接层;最后是softmax层。
1.2 网络特点
1.结构简单
虽然VGG层数较多,总的网络深度从11层到19层,但是它的整体结构还是相对简单。概括来说,VGG由5层卷积层(每个卷积层的子层数量不同)、3层全连接层、softmax输出层构成,层与层之间使用maxpooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
2.小卷积核
VGG中的所有卷积操作都是使用小卷积核(3x3)。VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27),省下的参数可以用于堆叠更多的卷积层,可以增加网络的拟合,表达,特征提取能力。
3.小池化核
相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
4.通道数多
VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道。相比较于AlexNet和ZFNet最多得到的通道数是256,VGG 的通道数的进行了翻倍,使得更多的信息可以被卷积操作提取出来。
5.层数更深、特征图更多
网络中,卷积层专注于扩大feature maps的通道数、池化层专注于缩小feature maps的宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
6.全卷积网络
VGG16在训练的时候使用的是全连接网络。然而在测试验证阶段,作者将全连接全部替换为卷积网络。全连接层首先转换为卷积层(第一个FC层改为7×7conv层,最后两个FC层改为1×1conv 层)。
第一层FC:输入为7*7*512的frature map,使用4096个7*7*512的卷积核进行卷积,输出1*1*4096个feature map,相当于4096个神经单元。
第二层FC:输入为1*1*4096的feature map,使用4096个1*1*4096的卷积核进行卷积,输出1*1*4096个feature map。
第三层FC:输入为1*1*4096个feature map,使用1000个1x1x4096的卷积核进行卷积,输出为1x1x1000。相当于1000个神经元,属于卷积层。
采用卷积替代全连接,可以让网络模型可以接受任意大小的尺寸。
1.3 论文
论文:《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
https://arxiv.org/pdf/1409.1556.pdf
贡献:使用小卷积核替换大卷积核;
缺陷:全连接层计算量过大;
1.4 参考博文
1.经典网络VGGNet介绍_fengbingchun的博客-CSDN博客
3.手撕 CNN 经典网络之 VGGNet(理论篇) - 知乎
2.GoogLeNet(Inception-v1)
获得2014 - ILSVRC锦标赛冠军。由于原始模块显著增加了计算负担,更新后的Inceptionv1模块在3 × 3、5 × 5卷积之前和池化层之后增加了1 × 1卷积层,分别用于压缩输入和输出图像通道数。在CNN中引入了Inception块的新概念,通过拆分、变化和合并将多尺度卷积和变换融合在一起,使得CNNs能够在降低计算成本的同时获得较高的准确率。
2.1 网络架构
1.Inception结构:
作者在文中提出Inception结构,将四个不同卷积核尺寸的卷积操作聚合在一起,四个分支卷积计算后的feature maps在channel维度上合并,得到一组feature map送入后续操作。采用不同大小的卷积核意味着不同大小的计算感受野,最后拼接操作意味着不同尺度特征的融合。
但是,使用5x5的卷积核仍然会带来相对较大的计算量。 因此,作者在改进结构中采用1x1卷积核来进行降维。更新前【a】后【b】的Inception-v1结构图:

2.网络架构图:
GoogLeNet采用模块化结构,通过不断地叠加Inception块进行实现。网络的最后采用了average pooling代替全连接层,这样可以允许网络接收不同大小的图片输入。网络中也使用了droupout,为了避免梯度消失,海尔外增加了2个softmax辅助分类器,用于前向导梯度。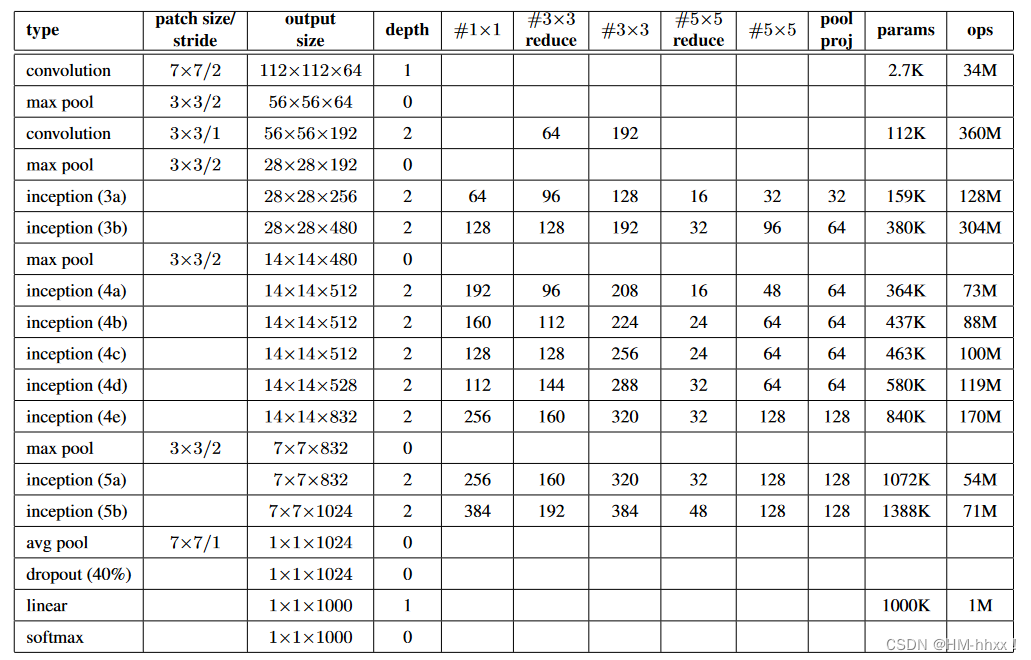
下图也是GoogLeNet的结构图,途中蓝色代表卷积层,红色代表池化层,黄色为softmax层:
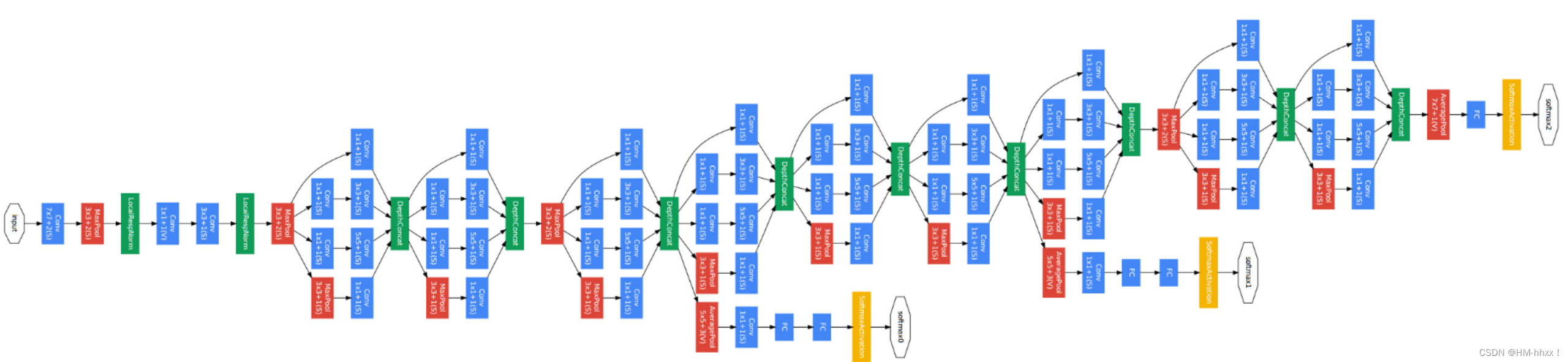
2.2 论文
论文:《Going Deeper with Convolutions》
https://arxiv.org/pdf/1409.4842v1.pdf
贡献:inception块增加网络宽度,在卷积操作时可以提取不同尺度的特征;
缺陷:存在无效的块结构;
3.InceptionV2(BN - Inception)
同年,Ioffe等人通过对Inceptionv1进行改进,提出了Inceptionv2,将原Inceptionv1模块中的大卷积核( 5 × 5)拆分为两个小卷积核( 3 × 3)。与Inceptionv1相比,它最大的贡献是引入了批量归一化( BN )的概念。
3.1 网络架构
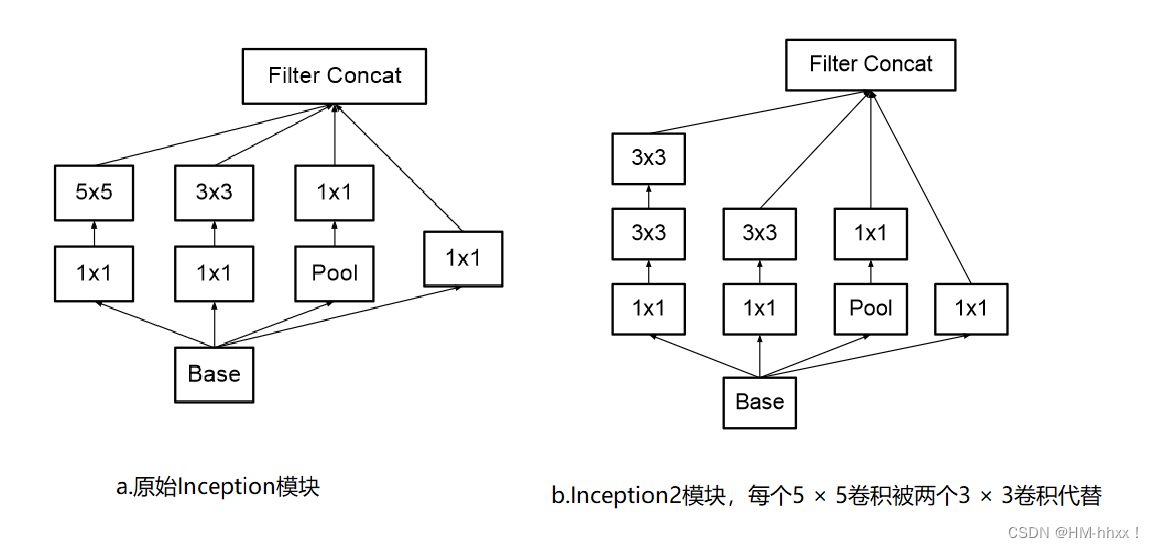
1.Inceptionv2块结构图
Inceptionv2将原Inceptionv1模块中的大卷积核( 5 × 5)拆分为两个小卷积核( 3 × 3),一个 5×5 的卷积在计算成本上是一个 3×3 卷积的 2.78 倍,所以在性能上有所提升。
2.InceptionV2网络架构图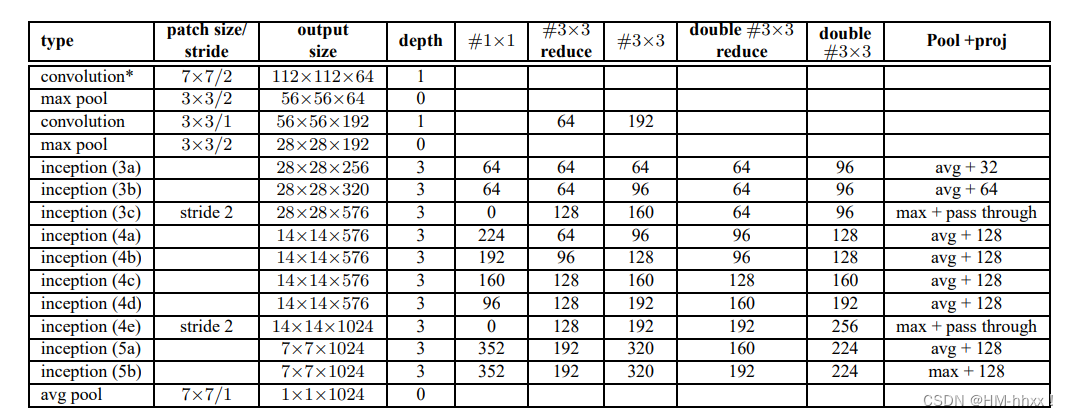
3.2 网络特点
与Inceptionv1相比,它最大的贡献是引入了批量归一化( BN )的概念。利用BN对某一网络节点的输出进行处理,使其近似服从均值为0,方差为11的正态分布,从而缓解反向传播中的梯度消失和梯度爆炸问题。
Batch Normalization(BN)的好处:
1.BN使得模型可以使用较大的学习率而不用特别关心诸如梯度爆炸或消失等优化问题;
2.降低了模型效果对初始权重的依赖;
3.可以加速收敛,一定程度上可以不使用Dropout这种降低收敛速度的方法,但却起到了正则化的作用,提高了模型泛化性;
4.即使不使用ReLU也能环节激活函数饱和问题;
5.能够学习到从当前层到下一层的分布缩放(scaling(方差),shift(期望))系数;
3.3 论文
论文:《Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift》
https://arxiv.org/pdf/1502.03167.pdf
贡献:介绍并引入Batch Normalization(BN);
缺陷:可优化的卷积层;
4.InceptionV3
Ioffe and Szegedy等人在2016年提出了Inceptionv3架构,旨在不影响泛化性的前提下,降低更深层网络的计算开销。
4.1 网络架构
1.Inceptionv3块结构
Inceptionv3引入了非对称卷积核,它将一个n × n的卷积核分解为n × 1和1 × n,n越大节省的运算量越大。但这种分解在前面的层效果不好,使用feature map大小在12-20之间。使用1 × 3、3 × 1非对称堆叠卷积比将3 × 3卷积核分解为2个2 × 2卷积核减少了28 %的参数量。与Inceptionv2相比,Inceptionv3还将7 × 7和5 × 5的大型滤波器替换为1 × 7、7 × 1和1 × 5、5 × 1的滤波器堆栈。此外,Inceptionv3使用辅助分类器来加速CNNs训练的收敛,性能提升了04%的top - 1准确率。
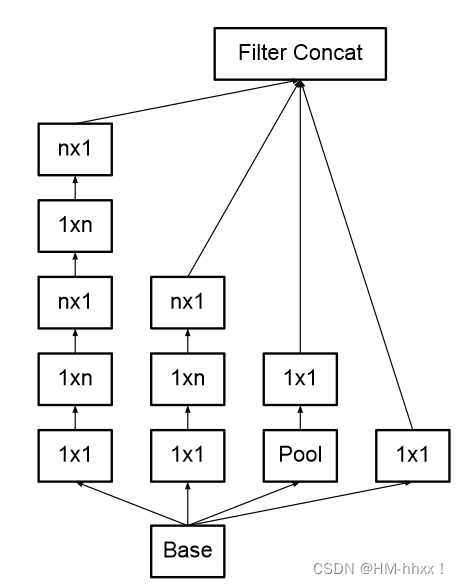
(n × n卷积分解后的Inception模块)
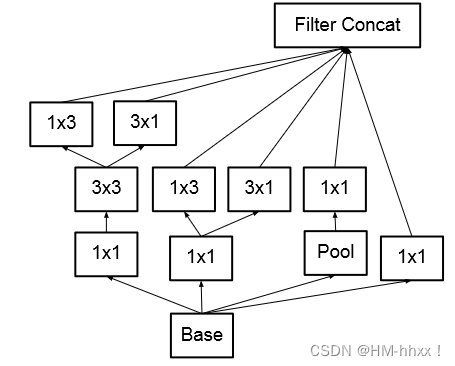
(不对称卷积示意图)
2.Inceptionv3架构图:
4.2 论文
论文:《Rethinking the Inception Architecture for Computer Vision》
https://arxiv.org/pdf/1512.00567v3.pdf
贡献:
提出通用网络结构设计准则;
引入卷积分解(非对称卷积)提高效率;
引入高效的feature map降维;
平滑标注样本;
缺陷:复杂的结构设计导致很难调整超参数;
5.InceptionV4
提出了效果更好的GoogLeNet Inception v4网络结构;与残差网络(ResNet)融合,提出效果不逊于v4但训练速度更快的GoogLeNet Inception ResNet结构(下一小节介绍)。
5.1 网络架构
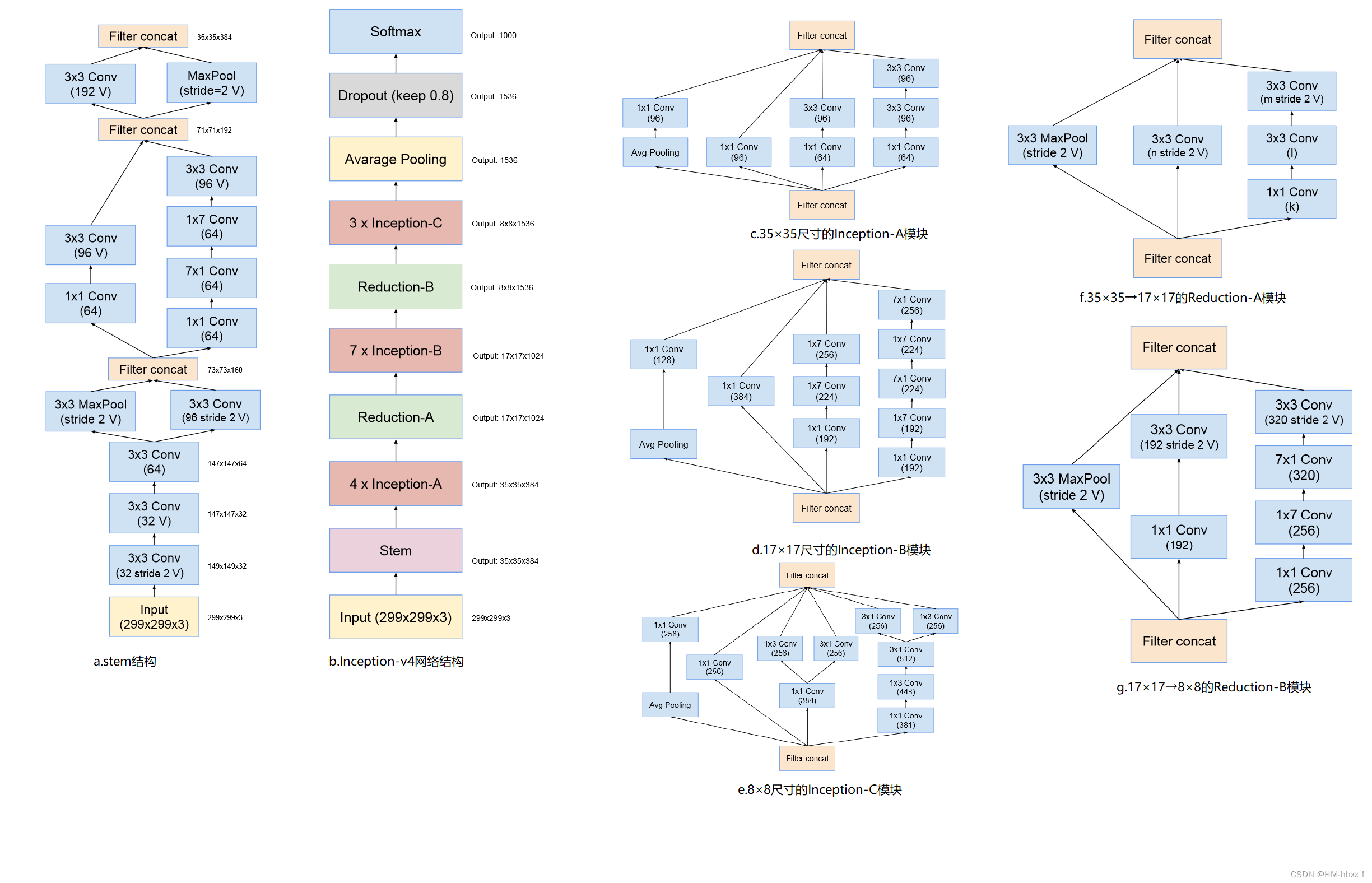
5.2 论文
论文:《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
https://arxiv.org/pdf/1602.07261.pdf
贡献:模块化网络构建;
缺陷:计算花销昂贵;
6.Inception-ResNet
受 ResNet 的优越性能启发,研究者提出了一种混合 inception 模块。尽管深度和宽度增加,但具有残差连接的Inception - ResNet具有与普通Inceptionv4相同的泛化能力。而且Inception - ResNet比Inceptionv4收敛更快,更直接地证明了使用残差连接可以显著加速Inception网络训练。Inceptionv4和Inception - ResNet训练速度更快,性能更好。
Inception ResNet 有两个子版本:v1 和 v2。
Inception-ResNet v1 的计算成本和 Inception v3 的接近。
Inception-ResNetv2 的计算成本和 Inception v4 的接近。
两个子版本都有相同的模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。
6.1 网络架构
Inception-ResNet v1及Inception-ResNet v2网络架构如下图所示(红框区域为V1,绿框区域为V2):
6.2 论文
论文:《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
https://arxiv.org/pdf/1602.07261.pdf
贡献:Inception和残差模块集成;
缺陷:可优化的多尺度特征提取;
7.对比

8.参考博文
1.深度学习之图像分类(五):GoogLeNet - 魔法学院小学弟
2.GoogLeNet网络结构详解与模型的搭建_太阳花的小绿豆的博客-CSDN博客
3. 深度学习入门(三十一)卷积神经网络——GoogLeNet_google 卷积神经网络_澪mio的博客-CSDN博客