前言
好像我的每次标题都有点不一样啊....好吧先别管这个了,这一篇文章我们要讲解的是特征点的匹配部分!!!
正文
理论
特征点匹配算法还是蛮多的,老师应该主要是讲了两个算法,一个是最小二乘法,一个是RANSAC算法,前面的那个就不多说了,主要来说一下RANSAC算法吧:
先简单介绍一下:
RANSAC(Random Sample Consensus)是一种鲁棒估计模型参数的算法,广泛用于计算机视觉和图像处理领域,尤其在特征点匹配、图像拼接、目标识别等任务中。RANSAC的主要特点是能够在存在大量噪声和异常值的数据集中,鲁棒地估计出最优模型参数。
RANSAC算法的基本步骤如下:
1. **随机采样:** 从数据集中随机选择最小样本集,用这些样本估计模型参数。
2. **模型拟合:** 使用选定的模型(例如线、平面、多项式等)拟合所选样本,得到一个模型。
3. **内点检验:** 计算所有数据点到拟合模型的距离,并将距离小于阈值的点标记为内点(符合模型的点),其他点标记为外点(异常点)。
4. **模型评估:** 计算内点的个数(拟合程度),内点越多,模型越好。
5. **迭代:** 重复步骤1到步骤4固定次数,每次都选择到的内点最多的模型。
6. **最优模型:** 选择具有最多内点的模型作为最终估计的模型。
RANSAC的优势在于它能够处理包含噪声和异常值的数据集。由于随机采样,它具有一定的概率能够选择到不包含异常值的样本集,从而得到一个较好的模型。然后通过迭代的方式,不断优化模型,最终得到鲁棒性较强的结果。
当应用RANSAC算法时,通常是在解决拟合数据点到一个数学模型的问题。这个模型可以是线性的、多项式的、平面的,或者其他更复杂的形式,具体的选择取决于问题的性质。我将以拟合直线为例,详细解释RANSAC的每一步数学原理。
**1. 随机采样:** 在拟合直线的问题中,我们随机选择两个不同的数据点,然后使用这两个点确定一条直线的方程。假设我们选择的两个点分别为$(x_1, y_1)$和$(x_2, y_2)$,那么直线的方程可以表示为$y = mx + b$,其中$m$是斜率,$b$是截距。根据两点式公式,我们可以得到斜率$m$和截距$b$的表达式:

**2. 模型拟合:** 使用选定的两个点,我们得到了一条直线的方程。
**3. 内点检验:** 计算所有数据点到拟合直线的距离,并将距离小于阈值的点标记为内点,其他点标记为外点。拟合直线的方程是$y = mx + b$,我们可以将数据点$(x_i, y_i)$到直线的距离表示为:
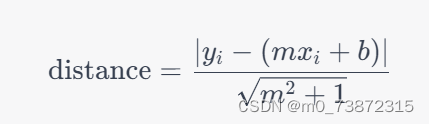
这里的分母是因为直线的斜率为$m$,所以法向量为$(m, -1)$。距离的计算公式实际上是点到直线的距离公式。
**4. 模型评估:** 计算内点的个数。内点越多,拟合程度越好。
**5. 迭代:** 重复步骤1到步骤4固定次数。每次迭代都会选择不同的两个随机点拟合直线,并计算内点个数。
**6. 最优模型:** 选择具有最多内点的直线作为最终估计的模型。
在RANSAC的每一步中,数学原理都基于基本的几何和代数知识,但RANSAC的威力在于其随机采样和迭代的策略,使得算法能够在包含噪声和异常值的数据集中找到最优的拟合模型。
代码
一份简单的代码示例:
import numpy as np
import matplotlib.pyplot as plt
# 生成带有噪声的数据
np.random.seed(0)
num_points = 100
noise = np.random.normal(loc=0, scale=10, size=num_points)
x = np.linspace(0, 100, num_points)
y = 3 * x + 2 + noise
# 添加一些异常值
num_outliers = 20
outliers_x = np.random.randint(0, num_points, num_outliers)
outliers_y = np.random.randint(0, 200, num_outliers)
y[outliers_x] = outliers_y
# 使用RANSAC算法拟合直线
def ransac_line_fit(x, y, threshold=10, max_iterations=100):
best_line = None
best_inliers = np.array([])
for _ in range(max_iterations):
random_indices = np.random.choice(len(x), 2, replace=False)
sample_x = x[random_indices]
sample_y = y[random_indices]
# 计算直线参数
A = np.vstack([sample_x, np.ones(len(sample_x))]).T
m, b = np.linalg.lstsq(A, sample_y, rcond=None)[0]
# 计算所有点到拟合直线的距离
distances = np.abs(y - (m * x + b))
# 判断内点
inliers = (distances < threshold)
# 更新最佳模型
if np.sum(inliers) > np.sum(best_inliers):
best_inliers = inliers
best_line = (m, b)
return best_line
best_line_m, best_line_b = ransac_line_fit(x, y, threshold=15, max_iterations=100)
# 绘制原始数据和拟合直线
plt.scatter(x, y, label='Data points', color='blue', alpha=0.6)
plt.scatter(x[best_inliers], y[best_inliers], label='Inliers', color='green', alpha=0.8)
plt.plot(x, best_line_m * x + best_line_b, color='red', linewidth=3, label='RANSAC line')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
结语
摸鱼了.....