图像编码在计算机视觉领域中一直是一个严峻的挑战,至少在深度学习火之前。在众多的视觉任务中,比如识别,检测,跟踪等,都需要提取出辨别的特征表示能更好的运用于后续的模型中。一般来说,最浅层的特征是图像的像素灰度。这种原始的灰度具有很少的语义信息,这严重限制了图像表示的描述能力。因此,大量的纹理特征,结构模式和边缘信息,如SIFT,HOG,LBP等得到了发展。这些特征灵活且相对容易构造,以方便的局部形式捕获了真实图像的大部分复杂统计量。此外,它们具有良好的抵抗遮挡,几何变形和光照变化的能力,并表现出良好的匹配性。然而,它们通常无法检测出图像局部块中最有意义的信息的,并且与图像的高层语义几乎没有关系。因此,许多研究基于这些低层的特征描述考虑了图像的较高级特征提取,如基于BoVW的模型和基于稀疏编码的方法。例如,李飞飞等应用潜在Dirichlet分配(LDA)模型来学习图像的高级语义信息。在这里,图像被视为文档;图像中学习的语义上下文对应于文档中的主题,而低层描述对应于文档中的单词。显然,学习的主题在文档分类中更有用。那么,对于更具复杂结构的图像应如何更好的表示呢? 2006年出现的深度学习对于自动表征这些复杂的图象非常有用。深度学习通常包含许多隐藏的层次,其表示能力从像素级(pixel-level)能增长到“人类”级(human-level)。显然,这些最终获得的“人类”级表示对后续的视觉任务非常有用。目前,基于深度学习的方法在各种视觉任务中能获得最佳性能。下面主要对相关方法进行一个简单汇总与总结,给自己的后续研究提供思路。
1. Super-vector
该文Image classi fication using super-vector coding of local image descriptors 发表在ECCV2010上。在Vector Quantization (VQ) Coding 的基础上运用泰勒函数展开定理进行了扩展,得到的编码向量被称为Super-Vector。本文假设我们旨在学习被定义在高维空间的一个平滑非线性函数
本文模型基于VQ,假设
由于
其中
以上都是基于VQ,很自然我们会联想到Soft-VQ,那么
在实验中,128-dimensional SIFT特征被提取并通过PCA被降维到80-dimensional。
2. Locally Linear KNN Model
该文A novel locally linear knn model for visual recognition 发表在CVPR2015上。在Locally-constraint 稀疏表示模型的基础上做了进一步的改进,模型表示为
其中
测试过程中采用传统的最小化重构误差,但在之前需将测试样本的稀疏表示进行cut-off,即每一个类别中的系数
值得注意的是,这个训练过程是在
3.Weighted Sparse Coding for Saliency Detection
该文A weighted sparse coding framwork for saliency detection 发表在CVPR2015上。提出了利用稀疏表示模型用于图像的显著性区域检测。构造显著性字典/非显著性字典进行稀疏编码,利用稀疏系数定义显著性值。作者在标准的稀疏表示模型下,引入了权重因子
注意到优化上述目标函数时,当
- 对图像
I 使用简单的SLIC(simple linear iterative clustering)进行分割得到一系列小的非重叠的区域(region/superpixel),即R={r1,⋯,rN} 。文中一般取N=300 。 - 在每一个区域里提取了两种特征(A good feature should exhibit high contrast between saliency and background):Gabor filter responses 作为纹理描述子,颜色直方图(1024bins)。将这些区域里的局部描述子相加得到该区域特征描述。那么整个图像的特征为这些区域特征的合集,
FA∈RC×N (纹理)与FH∈RC′×N (颜色直方图)。 - 构造初始的显著性字典
S0 。文中提出首先构造初始化的非显著性字典,即选取紧邻图像的边界区域r ,和focusness response 低于平均值的区域r 一起构造非显著性字典。对图像I 中的N 个区域在非显著性字典下进行稀疏编码,在得到对应区域的重构误差(显著性值)。当区域r 的显著性值高于平均值时,则定义该区域为显著性区域。有了这些显著性区域,就可以构造初始的显著性字典S0 ,作为潜在的显著性区域。 - 不断迭代,不断精细化该显著性字典。最终得到的显著性字典即为图像
I 中的显著性区域。
4.Localize objects with minimal supervision
经典的目标检测方法是将图像中的目标(bounding box)与背景带入分类器中学习出一个辨别模型(
- 使用selective search大规模减少图像训练集中探测窗口的个数
- 利用discriminative submodular cover algorithm进一步得到近似的目标窗口,并作为LSVM的初始值
- 利用LSVM进行模型的训练
LSVM是一个鸡与蛋的问题:有了模型参数才能推出隐变量,而有了隐变量才能估计模型参数。该模型可表示为
其中
(1) Relabel positive example:
(2) Optimizing Omega: Optimizing
LSVM对初始化非常敏感,所以本文在使用LSVM之前使用了提出的discriminative submodular cover algorithm得到近似的目标窗口。该算法思想很简单,基于一个先验知识:正确的目标boxes在合适的特征空间很相似,且目标窗口只有在正图像集中出现而不会出现在负图像集中。因此作者定义了一个函数
本文设计了两组实验证明了初始目标窗口的有效性,以及最终目标检测的准确性。
5.Multi-Task Multi-View Sparse Tracking}
该文Multi-attributed dictionary learning for sparse coding 发表在ICCV2013上。在传统的稀疏表示跟踪框架下提出了Multi-View的跟踪模型,即用多个特征去描述目标。作者在文中用到了4种特征,颜色直方图,灰度,HOG,LBP。假设一帧图像中所有候选窗口(400 个)的特征表示为
其中
上述模型同样可通过The Accelerated Proximal Gradient (APG) 算法计算稀疏系数矩阵
当然作者也提到了排除outlier的初始阈值设置为1,而在后续跟踪中阈值随着一帧中检测到的outlier的个数成类似正比增长。
6.Structural Sparse Tracking
稀疏表示模型运用在目标跟踪中的成果大量涌现,可分为全局稀疏表示跟踪和局部稀疏表示跟踪。该文Structural Sparse Tracking 出现在CVPR2015上,属于两者的结合体,提出的模型综合考虑了全局与局部稀疏约束,候选目标和局部块之间的内在联系,以及局部块的空间结构。
该文基于一个先验:即在目标周围采样的候选目标具有潜在的相关性,且这些目标窗口内采样的同位置处的局部块之间也具有潜在的联系(intrinsic relationship)。因此该文作者提出了新的稀疏编码框架。假设在一帧图像中,在目标位置处采样了
其中上文提到的相关性用
当对一帧图像进行目标跟踪时,首先在上一帧目标附近位置处采样候选目标窗口(400个),对每一个目标窗口内采样局部块(14 个),对所有的局部块数据进行稀疏编码,得到稀疏系数矩阵;再在对应字典上求出重构误差;针对每一个候选目标窗口,将属于此的局部块的重构误差累加;比较各个候选目标窗口的重构误差,达到对目标的检测。
本文采用中心位置误差与重叠率作为评价指标,并与14种最近方法进行比较,能取得不错的效果。但是作者没在文中说明局部块的特征提取方法。注意:当
7.Tracking via Discriminative Similarity Map
本文Visual tracking via discriminative sparse similarity map 在传统的稀疏表示跟踪框架下提出了反稀疏表示跟踪,即将候选目标窗口作为稀疏表示模型的字典而将目标模板和背景模板作为待分解的信号。另外为了使相似的候选目标具有相似的稀疏表示,本文引入了拉普拉斯正则项。模型可表示为
其中
该模型可通过APG method求解,得出的
注意
该文也提出了模板集的更新策略达到更加鲁棒的跟踪。当在一帧图像中检测到目标时,将该目标与正模板集做相似性运算,当与某一个模板的相似度小于设定的阈值时,则用此目标替换该对应模板;否则不更新正模板集。而负模板集的更新则采用实时更新的策略。
8.Tracking via Sparse Collaborative Appearance Model
本文Robust object tracking via sparsity-based collaborative model 提出了sparse discriminative classifier(SDC) 和sparse generative model(SGM)的集成模型用于目标的跟踪。其中SDC主要用于前景与背景的分离,而SGM主要考虑目标的空间特性。SDC为常规的稀疏表示跟踪模型,在构造目标字典(50) 与背景字典(200),人工框定窗口后归一化到
当为真正的目标时,
当候选目标与目标很相似时,
最后,作者定义了候选目标窗口的综合目标值
上述定义可以理解为候选目标与目标进行特征加权匹配,其中
9.Learning Spatial Regions for Classification
中层表示(mid-level representation)近来被用于增强图像分类的辨别能力,即寻找图像中辨别的部分(parts)并通过卷积得到该部分的响应,将这些部分的响应连接起来作为整幅图像的表示。即使图像中辨别的部分被发现并学习出滤波器,但是对新图像测试时那些不相关的但是结构相似的部分能产生高的响应,从而导致辨别能力的下降。而本文Learning important spatial pooling regions for scene classi fication 解决的问题是去除某些部分的错误响应得到图像更加辨别的中层表示。
本文思想基于一个先验:对某一类图像中的显著性物体(bounding box) 的中心做空间位置分布统计时,发现这一类图像中的物体空间位置基本紧紧相邻为几个簇;换句话,离簇中心较远的位置的部分对应错误的响应。因此本文提出的模型可以看成是在DPM根滤波器和子滤波器的基础上加入了空间位置信息,表示为
where
其中

那么,该模型的参数怎么得到呢?使用大量训练数据学习出参数,其中训练数据中显著性物体被bounding box大致的标定出,但不一定标定的准确。训练参数分为3步:
- 初始化
β 和ω 。 -
P 的推导。此过程相当于DPM中的Relabel Positive and Mine Hard Negative Samples。 -
β 的学习。假设P 已知,则正负样本已知。模型可以改写为Fβ(I,P)=β⋅ψ(I,P) ,那么损失函数写为SVM的形式LD(β)=12∥β∥2+C∑mMmax(0,1−ym⋅Fβ(Im,Pm)) ,其中D={(y1,I1,P1),⋯,(yM,IM,PM)} 。 -
ω 的学习。ω=argmaxω∑Mm∑Ni∑Kjdjϕ(pmi,pcij,σij)
图像的特征表示得到后,同时为了得到更高的正确率,该文特征结合FV,带入SVM分类器进行训练与测试。
10.Low-Rank Sparse Coding for Tracking & Image Classification
Low-rank sparse learning for robust visual tracking 和Low-rank sparse coding for image classi cation 都是基于低秩的稀疏编码用于目标的跟踪或图像的分类。基于低秩的稀疏编码都是基于这样的先验:目标周围区域内采样的目标候选框之间是相似的,则在过完备冗余字典下的稀疏表示是稀疏的且稀疏表示矩阵是低秩的;对于图像分类,作者对大量自然场景图像做了统计,发现所有图像采样块的SIFT描述子组成的矩阵是低秩的,且一副图像中的superpixel内的SIFT描述子组成的矩阵是更低秩的。那么模型可表示为
模型的求解是通过Inexact Augmented Lagrange Multiplier算法。对于目标跟踪来说
对于图像分类来说不考虑噪声
11.Encoding High Dimensional Local Features by Sparse Coding Based Fisher Vectors
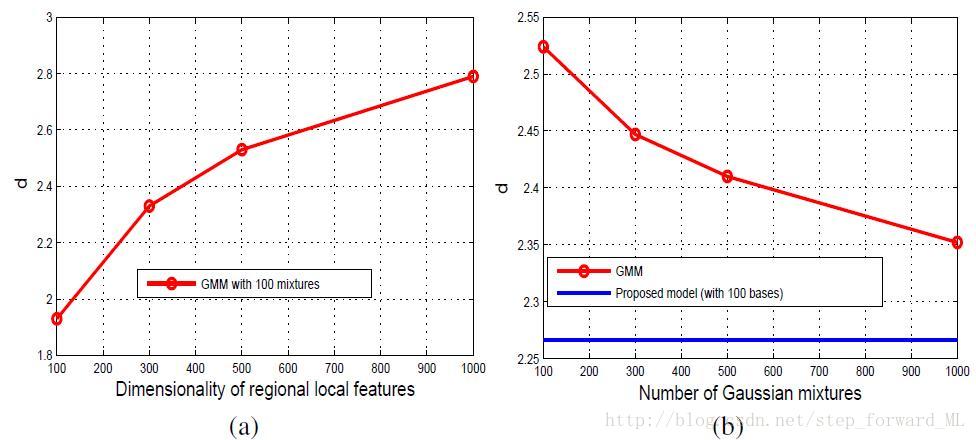
该论文发表于NIPS2014,主要针对的问题是传统的基于GMM的Fisher vector不能很好的处理高维的局部描述子。我们知道在计算机视觉建模中,GMM模型对于传统的128维的SIFT描述子往往需要不过100个高斯分布便能很好的拟合这些局部描述子。但是,针对更加高维的局部描述子,比如通过CNN提取的特征向量,则需要海量的高斯分布来拟合数据;而最终的Fisfer vector会造成维数灾难,不利于后续的处理。下图(a)很好的印证了该问题,
下面简单回顾一下Fisher kernel。假设
由上式可出,fisher vector的计算分为两步:对每一个局部描述子的分布的对数求梯度;再使用sum-pooling。
该文中局部描述子的生成过程如下:首先从一个零均值的Laplacian distribution中抽样一个编码向量,即
由于积分的存在,最大似然方法对参数
其中
可以看出模型参数