一个初学者小菜鸟的笔记,欢迎纠正!
目录
DataFrame对象
- DataFrame对象是Pandas库中的一种数据结构,类似于二维表,由行和列组成。每列可以是不同的值类型(数值、字符串、布尔值等)
- 与Series一样支持多种数据类型。
- DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
创建DataFrame对象
格式: pd.DataTrame(data,index,columns,dtype)
- columns 为列索引
- index 为行索引
- dtype为每一列数据的数据类型
-
列表方式创建DataFrame对象
- DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
-
import pandas as pd data = [['苹果',5,100],['梨',4,50],['香蕉',2,80]] columns = ['名称','单价','数量'] df = pd.DataFrame(data = data,columns = columns) print(df) '''输出: 名称 单价 数量 0 苹果 5 100 1 梨 4 50 2 香蕉 2 80 ''' -
df = pd.DataFrame([['苹果',5,10],['梨',4,50],['香蕉',2,80]],columns = ['名称','单价','数量'],index = [1,2,3]) print(df) '''输出: 名称 单价 数量 1 苹果 5 10 2 梨 4 50 3 香蕉 2 80 ''' - 字典方式创建DataFrame对象
-
data = { '名称':['苹果','梨','香蕉'], '单价':[5,4,2], '数量':[100,50,80] } df = pd.DataFrame(data=data) print(df) '''输出: 名称 单价 数量 0 苹果 5 100 1 梨 4 50 2 香蕉 2 80 '''
DataFrame的重要性
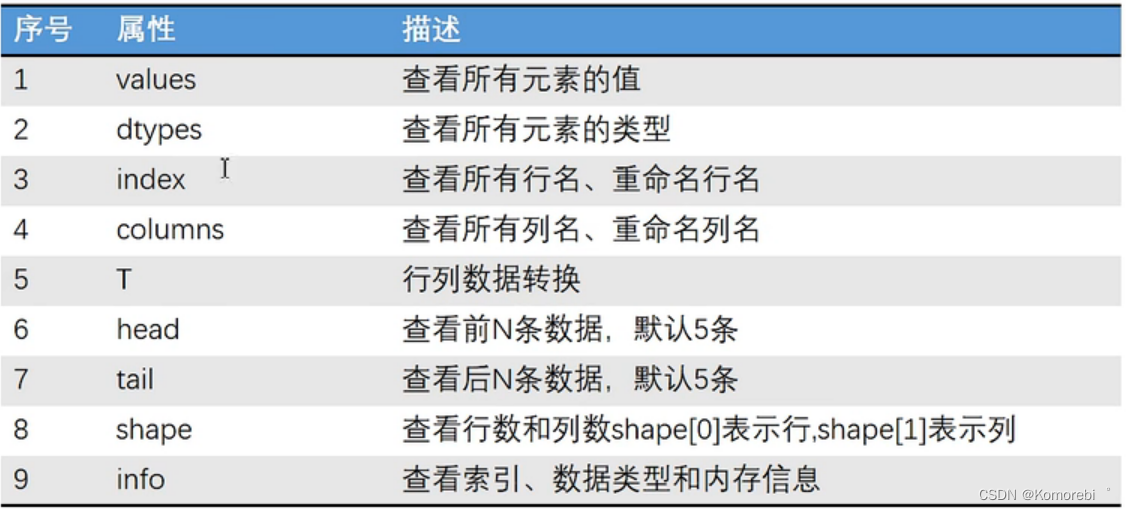
DataFrame的取值
通用方法:loc按索引取值,iloc按下标取值(少用)
格式:df.loc[ 行索引或范围, 列索引或范围 ]
其中,范围用列表来表示,且可以用冒号: 表示全范围
返回结果: 如果行和列都是范围,结果为dataframe
行和列其中一个是范围,结果为Series
行和列都是一个值,结果为单个元素
例子:
data = {'姓名':['张三','李四','王五'],'年龄':[21,22,20],'成绩':[86,80,90]}
df = pd.DataFrame(data)
print(df)
'''输出:
姓名 年龄 成绩
0 张三 21 86
1 李四 22 80
2 王五 20 90
'''- 取所有行的年龄列
print(df.loc[:,'年龄']) #取所有行的年龄列
'''输出:
0 21
1 22
2 20
'''- 取第一行的所有列
print(df.loc[1,:]) #取第一行的所有列
'''输出:
姓名 李四
年龄 22
数量 80
'''- 取1 2 行的姓名、成绩列
print(df.loc[[1,2],['姓名','成绩']]) #取1 2 行的姓名、成绩列
'''输出:
姓名 成绩
1 李四 80
2 王五 90
'''- 取第一行的姓名
print(df.loc[1,'姓名']) #取第一行的姓名
'''输出: 李四
'''提示:
当行的范围为:时,可以直接写成字典取值的形式
df.loc[:,'年龄'] 可以写成 df['年龄']
当列的范围为:时,可将列范围省略(loc不可省略)
df.loc[1,:] 可以写成 df.loc[1]
条件取值:
:条件取值:格式相同,只是把范围写成比较的式子
print(df.loc[df['年龄'] > 20]) #取年龄大于20的行的所有列
'''输出:
姓名 年龄 成绩
0 张三 21 86
1 李四 22 80
'''print(df.loc[df['年龄'] > 20,['姓名','年龄']]) #取年龄大于20的行的姓名、年龄
'''输出:
姓名 年龄
0 张三 21
1 李四 22
'''print(df.loc[:,df.loc[0] == 86]) #取第0行的值为90的列的所有行
'''输出:
成绩
0 86
1 80
2 90
'''DataFrame的常用函数:

- 求和sum、求平均值mean、求最大值max、最小值min,这些函数用法相同,其中参数填0则计算列,填1则计算行,不填则视为0,得到的结果是Series
df = pd.DataFrame([[1,2,3],[4,5,6]],columns = ['a','b','c'])
print(df)
'''输出:
a b c
0 1 2 3
1 4 5 6
'''- 计算各列值的和
print(df.sum(0)) #计算各列值的和
'''输出:
a 5
b 7
c 9
'''- #计算各行值的和
print(df.sum(1)) #计算各行值的和
'''输出:
0 6
1 15
'''DataFrame的常用函数:
-
自定义函数apply
给给df增加一个新的列‘和’,它的值为abc列的值的和
df = pd.DataFrame([[1,2,3],[4,5,6]],columns = ['a','b','c'])
def func(x): #这里的x代指df里的每一行
x['和'] = x['a'] + x['b'] + x['c']
return x
df = df.apply(func,axis=1) #axis=1表示以行为单位放入func
print(df)
'''输出:
a b c 和
0 1 2 3 6
1 4 5 6 15
'''将bc列的值取绝对值
df = pd.DataFrame([[-1,-2,3],[-4,-5,6]],columns = ['a','b','c'])
def func(x): #这里的x代指df里的每一行列
x = abs(x)
return x
df[['a','b']] = df[['a','b']].apply(func,axis=0) #axis=1表示以列为单位放入func
print(df)
'''输出:
a b c
0 1 2 3
1 4 5 6
'''索引对象:
索引对象可以理解为表的主键,DataFrame默认是没有索引对象的,且默认从0开始计数,可以使用set_index函数设置某个字段标签为索引对象
df = pd.DataFrame([[1,2,3],[4,5,6]],columns = ['a','b','c'])
print("默认索引:")
print(df)
df1 = df.set_index('a')
print("a作索引:")
print(df1)
'''输出:
默认索引:
a b c
0 1 2 3
1 4 5 6
a作索引:
b c
a
1 2 3
4 5 6
'''