版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/u012319493/article/details/86919210
Numpy 数组
# -*- coding: utf-8 -*-
import numpy as np
arr = np.array([1, 2, 3])
print(arr)
list1 = [1, 2, 3]
print(list1)
print(arr.shape)
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
print(arr.shape)
arr = np.array([1, 2, 3], ndmin = 2)
print(arr)
arr = np.array([1, 2, 3], dtype = float)
print(arr)
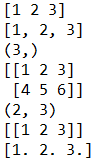
创建数组的几种方式
# -*- coding: utf-8 -*-
import numpy as np
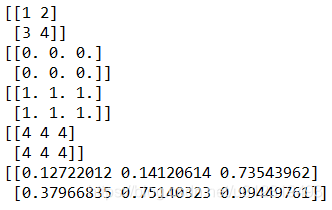
arr = np.array(np.mat('1 2; 3 4'))
print(arr)
arr = np.zeros([2, 3])
print(arr)
arr = np.ones([2, 3])
print(arr)
arr = np.full((2, 3), 4)
print(arr)
arr = np.random.random([2, 3])
print(arr)
Numpy 索引
# -*- coding: utf-8 -*-
import numpy as np
arr = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
print(arr[1, 2])
print(arr[0:, 2:4]) # 从行0开始到结束,从列2开始一直到列4
print(arr[-1:, 0:2]) # 从最后一行开始到结束,从列0开始到列2
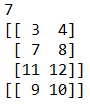
按顺序生成数组
# -*- coding: utf-8 -*-
import numpy as np
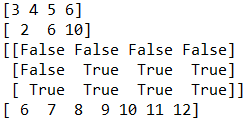
arr = np.arange(3, 7)
print(arr)
arr = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
arr1 = arr[np.arange(3), 1] # 列1
print(arr1)
print(arr > 5)
print(arr[arr>5])
Numpy 的数学运算
# -*- coding: utf-8 -*-
import numpy as np
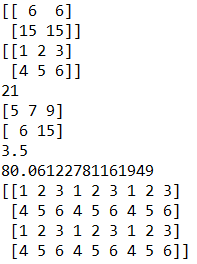
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
print(arr1 + arr2)
print(np.add(arr1, arr2))
print(np.subtract(arr1, arr2))
print(np.multiply(arr1, arr2))
print(np.divide(arr1, arr2))
print(np.sqrt(arr1))

矩阵
# -*- coding: utf-8 -*-
import numpy as np
arr1 = np.array([[1, 2, 3],
[4, 5, 6]])
arr2 = np.array([[1, 1],
[1, 1],
[1, 1]])
print(np.dot(arr1, arr2))
print(arr1)
print(np.sum(arr1))
print(np.sum(arr1, axis = 0)) # 对列求和
print(np.sum(arr1, axis = 1)) # 对行求和
print(np.mean(arr1)) # 平均值
print(np.random.uniform(1, 199)) # 服从正态分布的随机值
print(np.tile(arr1, (2, 3))) # 复制
排序
# -*- coding: utf-8 -*-
import numpy as np
arr1 = np.array([[1, 2, 3],
[5, 4, 6]])
print(arr1.argsort()) # 打印排好序后的下标
print(arr1.T) # 转置
arr2 = np.array([1, 2, 3])
print(arr1 + arr2) # 广播,处理不同形状矩阵的能力
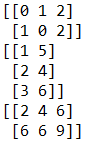
Pandas
# -*- coding: utf-8 -*-
import pandas as pd
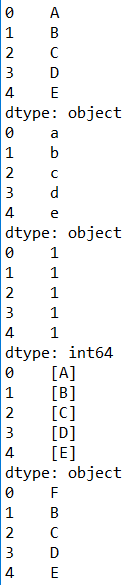
s = pd.Series(list('ABCDE')) # 一维
print(s)
print(s.str.lower())
print(s.str.len()) # 每个元素的长度
print(s.str.split(" ")) # 用空格切割
print(s.str.replace('A', 'F')) # 将 A 替换为 F
s = pd.Series(['a1', 'b2', 'c3', 'd4'])
print(s.str.len())
print(s.str.extract('(\d)'))
print(s.str.extract('[ab](\d)')) # a或b开头,后面是数字,要获取的数据用小括号包裹
print(s.str.extract('([ab])(\d)'))
print(s.str.extract('(?P<str>[ab])(?P<number>\d)')) # ?P<> 给列重命名
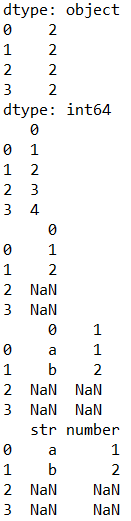
检测 series
# -*- coding: utf-8 -*-
import pandas as pd
s = pd.Series(['a', 'B', 'ca', 'Da'])
print(s)
rule = r'[a-z]'
print(s.str.contains(rule)) # 检测每个元素是否包含小写字母
print(s.str.startswith('a')) # print(s.str.contains('^a'))
print(s.str.endswith('a')) # print(s.str.contains('a$'))

DataFrame
# -*- coding: utf-8 -*-
import pandas as pd
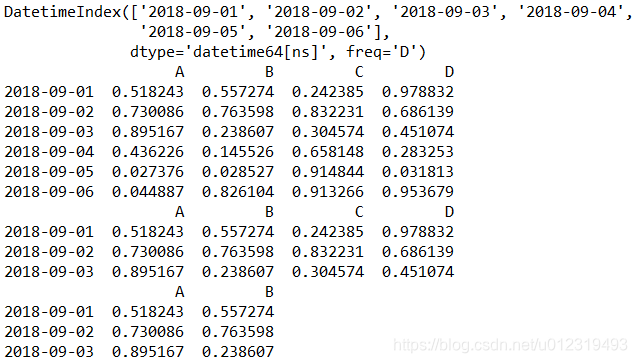
dates = pd.date_range('20180901', periods = 6) # 生成6天的日期
print(dates)
# 随机生成 2 行 3 列的数据
# index 是行名,clumns 是列名
df = pd.DataFrame(np.random.rand(6, 4), index = dates, columns = list('ABCD'))
print(df)
print(df['20180901':'20180903']) # 前3行
print(df.loc['20180901':'20180903', ['A', 'B']]) # 前3行,前2列
Pandas 筛选
# -*- coding: utf-8 -*-
import pandas as pd
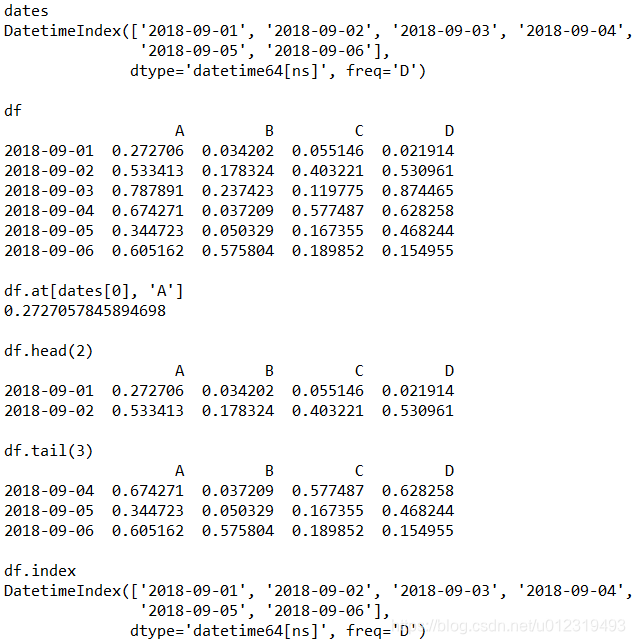
dates = pd.date_range('20180901', periods = 6) # 生成6天的日期
print("dates")
print(dates)
# 随机生成6行4列的数据
# index 是行名,clumns 是列名
df = pd.DataFrame(np.random.rand(6, 4), index = dates, columns = list('ABCD'))
print("\ndf")
print(df)
print("\ndf.at[dates[0], 'A']")
print(df.at[dates[0], 'A']) # 行0,列A
print("\ndf.head(2)")
print(df.head(2)) # 前2行
print("\ndf.tail(3)")
print(df.tail(3)) # 后3行
print("\ndf.index")
print(df.index) # 索引名,即行名
print("\ndf.columns")
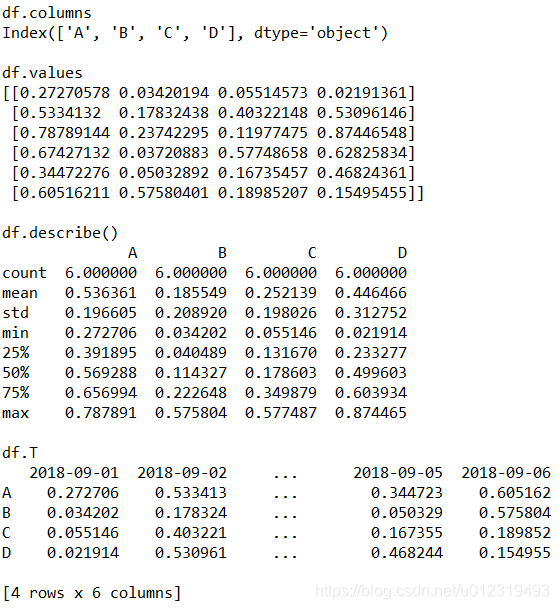
print(df.columns) # 列名
print("\ndf.values")
print(df.values) # 值
print("\ndf.describe()")
print(df.describe()) # 统计信息
print("\ndf.T")
print(df.T) # 转置
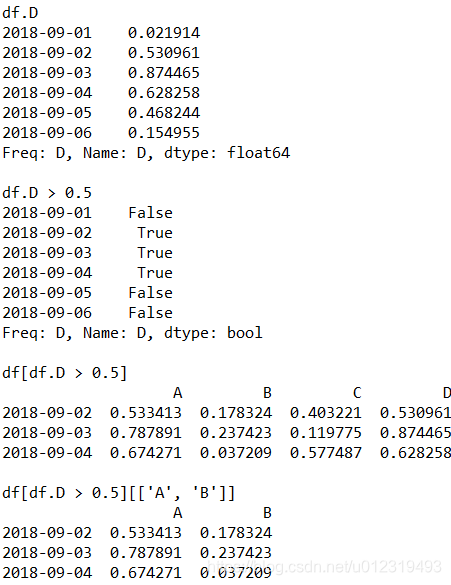
print("\ndf.D")
print(df.D) # 只打印列D
print("\ndf.D > 0.5")
print(df.D > 0.5) # 列D中大于0.5
print("\ndf[df.D > 0.5]")
print(df[df.D > 0.5])
print("\ndf[df.D > 0.5][['A', 'B']]")
print(df[df.D > 0.5][['A', 'B']])
Pandas 读取 Excel 数据
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
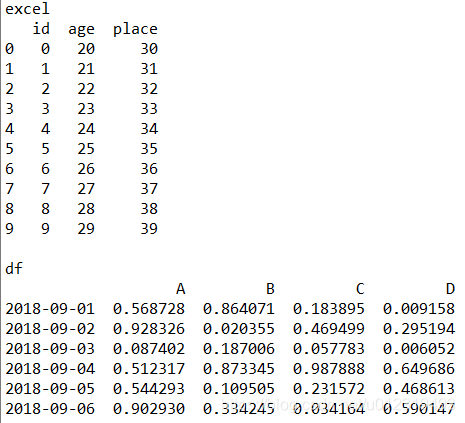
excel = pd.read_excel("c:/result/data.xls", sheet_name = 'Sheet1') # 读取 excel
print("excel")
print(excel)
p1 = excel.plot(kind = 'scatter', x = 'age', y = 'place').get_figure() # 绘制散点图
p1.show()
p1.savefig("c:/result/data.jpg")
dates = pd.date_range('20180901', periods = 6) # 生成6天的日期
df = pd.DataFrame(np.random.rand(6, 4), index = dates, columns = list('ABCD'))
print("\ndf")
print(df)
p1 = df.plot(kind='scatter', x='A', y='B').get_figure()
p1.show()