出现这个报错的时候:
AutoInstall will run now for 'ultralytics.nn.modules.conv' but this feature will be removed in the future.
Recommend fixes are to train a new model using the latest 'ultralytics' package or to run a command with an official YOLOv8 model, i.e. 'yolo predict model=yolov8n.pt'
requirements: YOLOv8 requirement "ultralytics.nn.modules.conv" not found, attempting AutoUpdate...
ERROR: Could not find a version that satisfies the requirement ultralytics.nn.modules.conv (from versions: none)
ERROR: No matching distribution found for ultralytics.nn.modules.conv
requirements: ❌ Command 'pip install "ultralytics.nn.modules.conv" ' returned non-zero exit status 1.File "/usr/local/ev_sdk/src/ultralytics/nn/tasks.py", line 351, in torch_safe_load
return torch.load(file, map_location='cpu'), file # load
File "/opt/conda/lib/python3.7/site-packages/torch/serialization.py", line 712, in load
return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
File "/opt/conda/lib/python3.7/site-packages/torch/serialization.py", line 1046, in _load
result = unpickler.load()
File "/opt/conda/lib/python3.7/site-packages/torch/serialization.py", line 1039, in find_class
return super().find_class(mod_name, name)
ModuleNotFoundError: No module named 'ultralytics.nn.modules.conv'; 'ultralytics.nn.modules' is not a package
检查 ultralytics包的版本,尽量是最新版本的,我因为原来是8.0.11,所以报错了。
查询问题以后发现,变成最新版本就没问题了
!pip install ultralytics==8.0.144如果还是报错,要注意你运行的py文件要在yolo文件目录下面

由于yolov8训练出来的模型默认是保存在指定当前目录的runs/detect/train下面
如果要修改模型保存的路径可以在训练的时候加上project,如下所示:
yolo task=detect mode=train model=yolov8s.pt epochs=100 batch=2 data=datasets/helmet.yaml project=/project/train/models/resume就可以实现训练的时候保存到指定的文件夹下面;
使用resume=True参数,就可以实现训练中断,然后再训练:
yolo task=detect mode=train model=E:/yolov8/ultralytics_ds_converter/ultralytics/please/train2/weights/best.pt epochs=100 batch=2 data=datasets/helmet.yaml project=E:/yolov8/ultralytics_ds_converter/ultralytics/please/ resume=True但是要注意使用resume的模型要修改为你中断的模型里面,而且最好选择best模型,如果选择last.pt可能是损坏的,无法正常读取,会报下面的这个错误:
RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
在使用C++里面的onnxruntime来运行yolov8s.onnxwen文件的时候,出现了报错信息:
Ort::Env(OrtLoggingLevel::ORT_LOGGING_LEVEL_ERROR, "Yolov5-Seg");
报错信息如下:
引发了异常: 读取访问权限冲突。
Ort::GetApi(...) 返回 nullptr。
我找到的解决方案如下:
这个一般会是dll冲突问题导致的,win系统特有的问题,原因在于win10的system32下面自带有一个onnxruntime的dll,优先级比环境变量添加的路径高导致的,你可以修改权限删除,或者你可以将onnx的相关dll拷贝到你项目的exe下面去运行看下。
如果出现了下面这个错误:
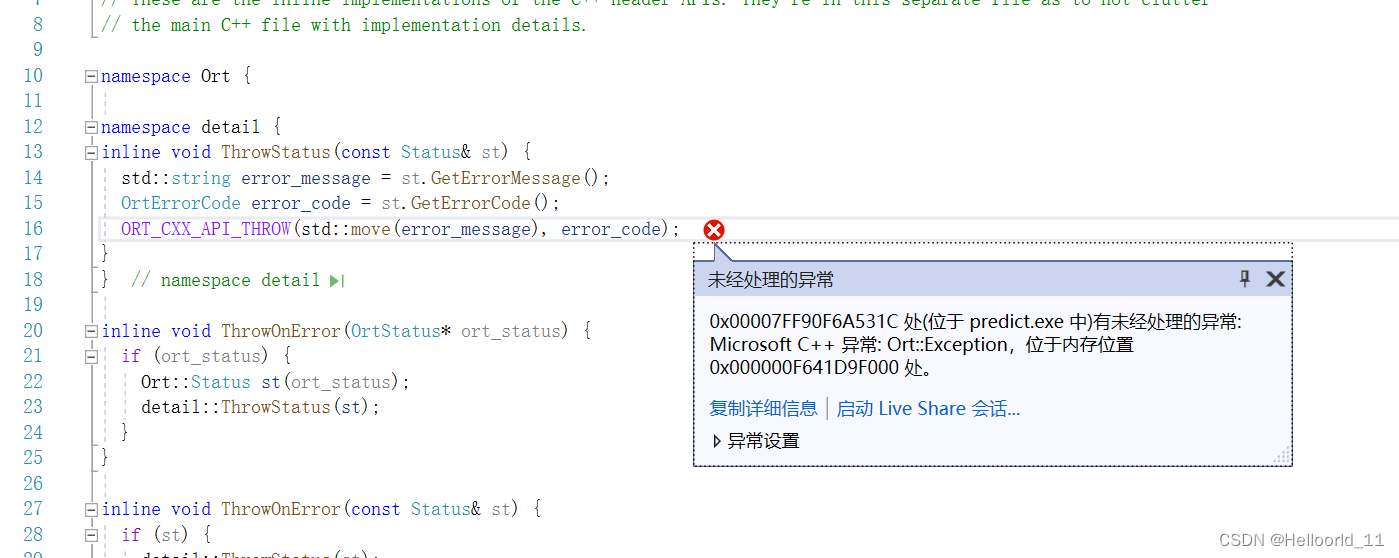
是路径的问题,把\变成/,检测onnx文件的路径。
我使用了opencv4.5.2和onnxruntime1.4.1
完整代码如下:
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
#include <fstream>
using namespace cv;
using namespace std;
std::string labels_txt_file = "classes.txt";
std::vector<std::string> readClassNames();
std::vector<std::string> readClassNames()
{
std::vector<std::string> classNames;
std::ifstream fp(labels_txt_file);
if (!fp.is_open())
{
printf("could not open file...\n");
exit(-1);
}
std::string name;
while (!fp.eof())
{
std::getline(fp, name);
if (name.length())
classNames.push_back(name);
}
fp.close();
return classNames;
}
int main(int argc, char** argv) {
std::vector<std::string> labels = readClassNames();
cv::Mat frame = cv::imread("E:/yolov8/dataset/images/.jpg");
int ih = frame.rows;
int iw = frame.cols;
// 创建InferSession, 查询支持硬件设备
// GPU Mode, 0 - gpu device id
std::string onnxpath = "E:/yolov8/code/predict/predict/yolov8s.onnx";//E:/yolov8/ultralytics_ds_converter/ultralytics/runs/detect/train/weights/best.onnx
std::wstring modelPath = std::wstring(onnxpath.begin(), onnxpath.end());
Ort::SessionOptions session_options;
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "yolov8-onnx");
session_options.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
std::cout << "onnxruntime inference try to use GPU Device" << std::endl;
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
Ort::Session session_(env, modelPath.c_str(), session_options);
std::vector<std::string> input_node_names;
std::vector<std::string> output_node_names;
size_t numInputNodes = session_.GetInputCount();
size_t numOutputNodes = session_.GetOutputCount();
Ort::AllocatorWithDefaultOptions allocator;
input_node_names.reserve(numInputNodes);
// 获取输入信息
int input_w = 0;
int input_h = 0;
for (int i = 0; i < numInputNodes; i++) {
auto input_name = session_.GetInputNameAllocated(i, allocator);
input_node_names.push_back(input_name.get());
Ort::TypeInfo input_type_info = session_.GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_w = input_dims[3];
input_h = input_dims[2];
std::cout << "input format: w = " << input_w << "h:" << input_h << std::endl;
}
// 获取输出信息
int output_h = 0;
int output_w = 0;
Ort::TypeInfo output_type_info = session_.GetOutputTypeInfo(0);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_h = output_dims[1]; // 84
output_w = output_dims[2]; // 8400
std::cout << "output format : HxW = " << output_dims[1] << "x" << output_dims[2] << std::endl;
for (int i = 0; i < numOutputNodes; i++) {
auto out_name = session_.GetOutputNameAllocated(i, allocator);
output_node_names.push_back(out_name.get());
}
std::cout << "input: " << input_node_names[0] << " output: " << output_node_names[0] << std::endl;
// format frame
int64 start = cv::getTickCount();
int w = frame.cols;
int h = frame.rows;
int _max = std::max(h, w);
cv::Mat image = cv::Mat::zeros(cv::Size(_max, _max), CV_8UC3);
cv::Rect roi(0, 0, w, h);
frame.copyTo(image(roi));
// fix bug, boxes consistence!
float x_factor = image.cols / static_cast<float>(input_w);
float y_factor = image.rows / static_cast<float>(input_h);
cv::Mat blob = cv::dnn::blobFromImage(image, 1 / 255.0, cv::Size(input_w, input_h), cv::Scalar(0, 0, 0), true, false);
size_t tpixels = input_h * input_w * 3;
std::array<int64_t, 4> input_shape_info{ 1, 3, input_h, input_w };
// set input data and inference
auto allocator_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(allocator_info, blob.ptr<float>(), tpixels, input_shape_info.data(), input_shape_info.size());
const std::array<const char*, 1> inputNames = { input_node_names[0].c_str() };
const std::array<const char*, 1> outNames = { output_node_names[0].c_str() };
std::vector<Ort::Value> ort_outputs;
try {
ort_outputs = session_.Run(Ort::RunOptions{ nullptr }, inputNames.data(), &input_tensor_, 1, outNames.data(), outNames.size());
}
catch (std::exception e) {
std::cout << e.what() << std::endl;
}
// output data
const float* pdata = ort_outputs[0].GetTensorMutableData<float>();
cv::Mat dout(output_h, output_w, CV_32F, (float*)pdata);
cv::Mat det_output = dout.t(); // 8400x84
// post-process
std::vector<cv::Rect> boxes;
std::vector<int> classIds;
std::vector<float> confidences;
for (int i = 0; i < det_output.rows; i++) {
cv::Mat classes_scores = det_output.row(i).colRange(4, 84);
cv::Point classIdPoint;
double score;
minMaxLoc(classes_scores, 0, &score, 0, &classIdPoint);
// 置信度 0~1之间
if (score > 0.25)
{
float cx = det_output.at<float>(i, 0);
float cy = det_output.at<float>(i, 1);
float ow = det_output.at<float>(i, 2);
float oh = det_output.at<float>(i, 3);
int x = static_cast<int>((cx - 0.5 * ow) * x_factor);
int y = static_cast<int>((cy - 0.5 * oh) * y_factor);
int width = static_cast<int>(ow * x_factor);
int height = static_cast<int>(oh * y_factor);
cv::Rect box;
box.x = x;
box.y = y;
box.width = width;
box.height = height;
boxes.push_back(box);
classIds.push_back(classIdPoint.x);
confidences.push_back(score);
}
}
// NMS
std::vector<int> indexes;
cv::dnn::NMSBoxes(boxes, confidences, 0.25, 0.45, indexes);
for (size_t i = 0; i < indexes.size(); i++) {
int index = indexes[i];
int idx = classIds[index];
cv::rectangle(frame, boxes[index], cv::Scalar(0, 0, 255), 2, 8);
cv::rectangle(frame, cv::Point(boxes[index].tl().x, boxes[index].tl().y - 20),
cv::Point(boxes[index].br().x, boxes[index].tl().y), cv::Scalar(0, 255, 255), -1);
putText(frame, labels[idx], cv::Point(boxes[index].tl().x, boxes[index].tl().y), cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(255, 0, 0), 2, 8);
cv::imshow("YOLOv8+ONNXRUNTIME 对象检测演示", frame);
}
// 计算FPS render it
float t = (cv::getTickCount() - start) / static_cast<float>(cv::getTickFrequency());
putText(frame, cv::format("FPS: %.2f", 1.0 / t), cv::Point(20, 40), cv::FONT_HERSHEY_PLAIN, 2.0, cv::Scalar(255, 0, 0), 2, 8);
cv::imshow("YOLOv8+ONNXRUNTIME 对象检测演示", frame);
cv::waitKey(0);
session_options.release();
session_.release();
return 0;
}