文章目录
1.前言
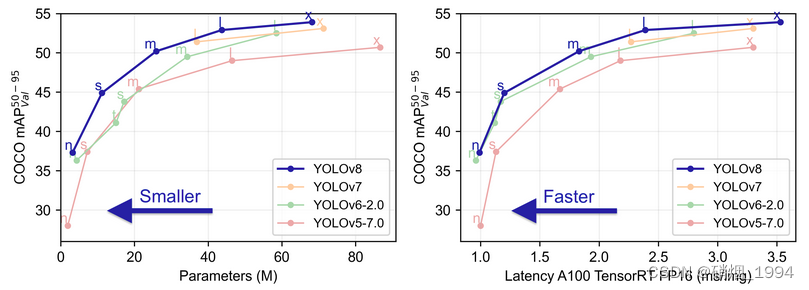
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本。是一款强大、灵活的目标检测和图像分割工具,它提供了最新的 SOTA 技术。
Github: yolov8
2.创新点及工作
- 提供了一个全新的SOTA模型。基于缩放系数也提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求;
- 网络结构上引入C2F和SPPF模块,并对不同尺度的模型进行了精心微调,提升网络特征提取能力及模型性能的同时,平衡模型的推理速度;
- 采用Anchor-Free代替Anchor-Based,对网络输出头进行解耦,分离类别预测和目标框的回归,同时去掉置信度分支;
- 采用TaskAlignedAssigner 动态正样本分配策略,提高样本的生成质量
- 引入了 Distribution Focal Loss用于目标框的回归。
3. 网络结构
3.1 BackBone
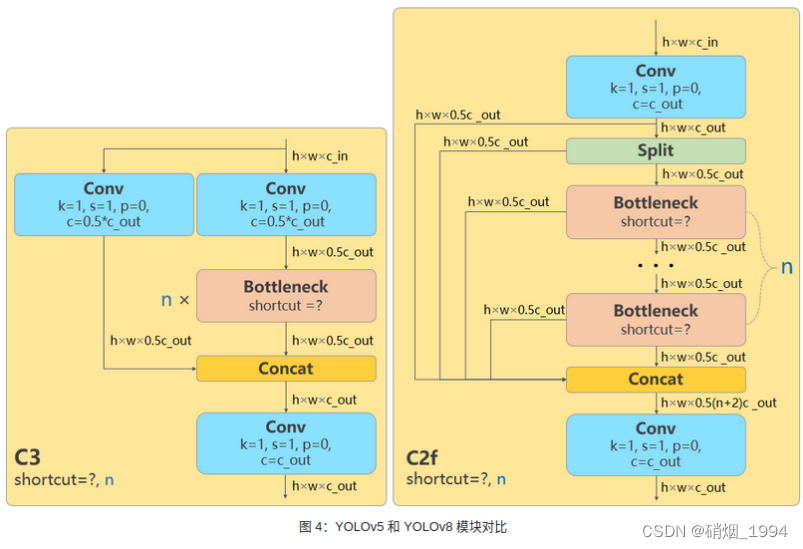
3.1.1 C2F
网络结构优化的一种方法:替换基本组件;
- 参考了YOLOv5的C3模块以及YOLOv7的ELAN的模块进行的设计,让YOLOv8可以在保证轻量化的同时,通过引入更多的分支跨层连接可以获得更加丰富的梯度流信息。
- 相较于YOLOv7的ELAN模块的设计,C2F模块在输入/输出通道上没有做什么额外工作,在一定程度并不太符合ShuffleNet的一些设计准则:要想使卷积推理速度达到最快,输入通道应与输出通道保持一致。
- C2F模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
3.1.2 结构微调
对不同尺度模型调整了通道数和模型的深度,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,综合考虑模型的精度和推理速度

- Yolov5中C3模块的堆叠遵循着3/6/9/3的配置,而在YOLOv8中,C2F的配置则是3/6/6/3的配置,其中的9被减小到了6,以压缩模型的规模
- 对于较轻量的YOLOv8-N和YOLOv8-S,基本通道数遵循128->256->512->1024的变化规律,即乘以各自的width参数即可。 但是,对于较大的M/L/X,最后的1024则分别变成了768,512和512,如上图红框所示,C5尺度的通道数是有变化的。相当于加入一个参数ratio,简记r,基础通道数为512,那么从YOLOv8-N到YOLOv8-X,就一共有width(w)、depth(d)和ratio® 三组可调控的参数:
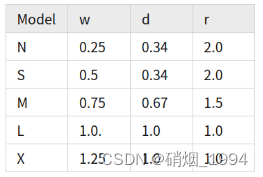
- 这种人为调控参数的目的在于提升模型精度的同时,控制计算量的大小,以实现和其它算法相比,达到SOTA效果;但这种强行调整的方式,人为雕琢的痕迹过重,网络结构的调整没有那么”优雅”。
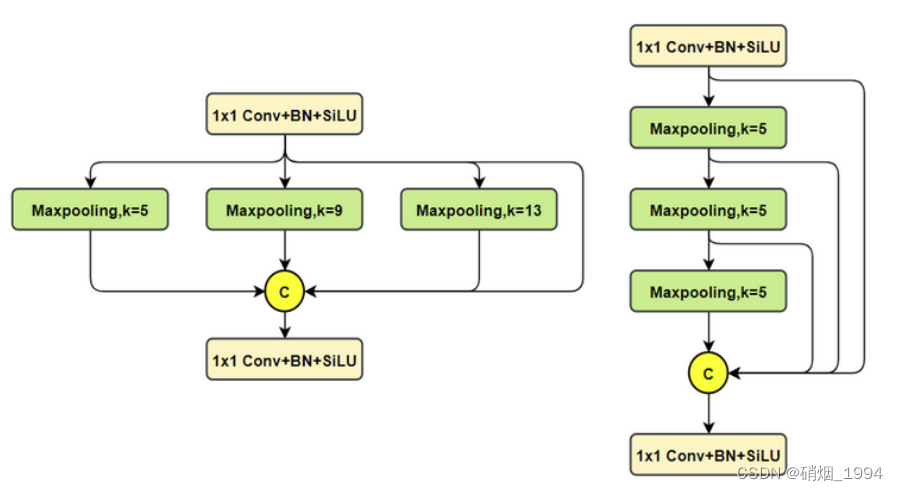
3.1.2 SPPF
对比spp,将简单的并行max pooling 改为串行+并行的方式。对比如下(左边是SPP,右边是SPPF)
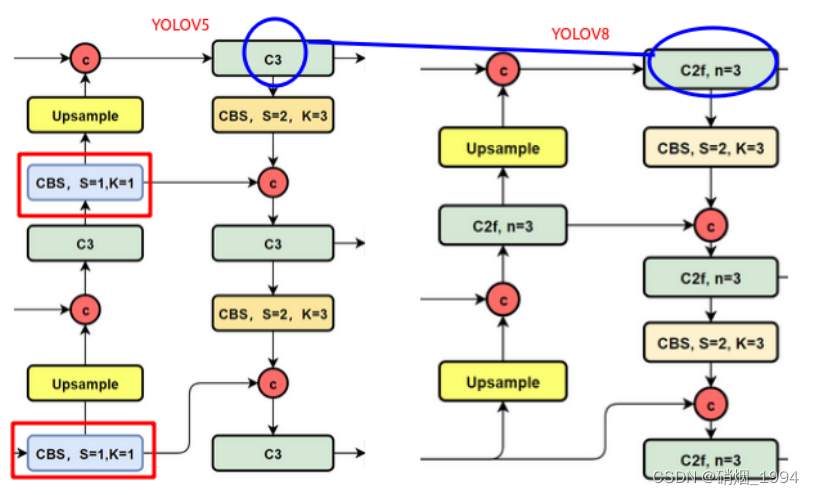
3.2 Neck
NECK部分和yolov5结构基本一致,区别主要有两点
- C3模块更换为C2F模块
- 去掉了上采样前用于降维的 1×1 卷积。
3.3 Head
- Anchor_base 调整为 Anchor_free
- 个人认为anchor box在一定程度上能够起到先验的作用,但其尺寸一般基于数据集统计分析得到,在一定程度上依赖于数据集本身的分布;
- 同时anchor的引入会带来额外的参数量,整体来说anchor_free还是较为简单明了;
- 参考yolox操作,对预测结果进行解耦 :单独分支预测分类和定位
- 去掉了置信度分支
- 回归的内容是ltrb四个值(距离匹配到的anchor点的距离值),这里的regmax在后面进行解释
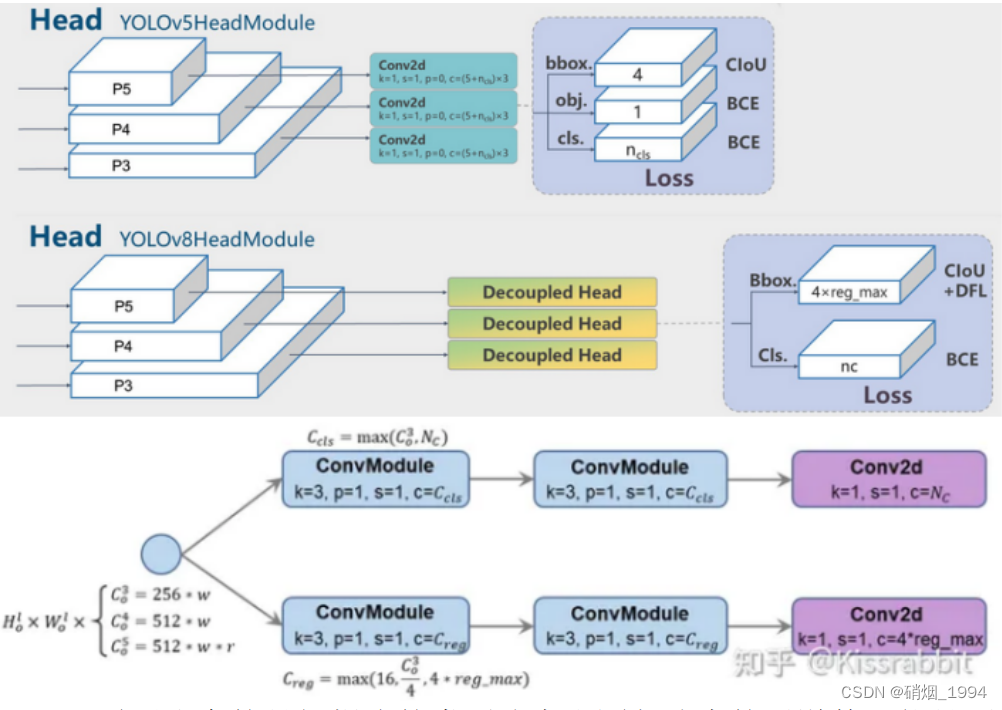
- 需要注意的是解耦头的类别分支和回归分支的通道数可能是不相等的,YOLOv8认为二者表征了两种不同的特征,应该不一样。因此,对于类别分支,YOLOv8将其通道数设置为 c c l s = m a x ( c 0 3 , N C ) c_{cls} = max(c_0^3,N_C) ccls=max(c03,NC) 回归分支的通道数设置为 c r e g = m a x ( 16 , c 0 3 / 4 , 4 ∗ r e g m a x ) c_{reg} = max(16,c_0^3/4,4*regmax) creg=max(16,c03/4,4∗regmax) 以coco数据集(类别80)为例,第一层解耦头的通道数配置为

4.正样本匹配策略
4.1 静态分配策略&动态分配策略
- 在目标检测中,正负样本分配策略关系到模型训练精度的一个重要因素,实际应用中静态分配策略和动态分配策略是两种常见的正负样本分配策略。
- 静态分配策略通常是设置一些固定阈值参数,如iou、长宽比等。其分配策略在训练前就已经设置好且不会随着网络的训练而发生调整;这些超参数和分配策略一般是基于数据集的统计结果和实际经验得出;
- 动态分配策略生成的正负样本往往和模型的训练相关联,随着训练的逐步进行,模型的能力逐渐增强,可以让模型更多的关注于高质量的正样本上。整体而言,动态分配策略可以在训练过程中进行调整,能够更好的适用不同的数据集和场景;
- 训练前期,模型的能力较弱,生成的正负样本可能存在一些问题不利于网络的学习和收敛。所以在实际训练过程中,可以在采用前期使用静态分配策略,中后期使用动态分配策略的组合方法;也可以利于静态分配策略进行样本初筛,然后使用动态分配策略进行细筛的方法生成正负样本;
4.2 TaskAlignedAssigner
正负样本分配策略上目标检测领域的一个常见的优化方向,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本
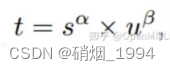
- α 和 β 为权重超参,s 是标注类别对应的预测分值,u 是预测框和gt 框的iou,两者相乘就可以衡量对齐程度(Task-Alignment)
- t 可以同时控制分类得分和IoU 的优化来实现 Task-Alignment,可以引导网络动态的关注于高质量的Anchor。
具体执行步骤
- 基于分类得分和预测框与GT的IoU加权得到一个关联分类以及回归的对齐分数alignment_metrics;
- 计算anchor中心点是否在当前GT框内,is_in_point:只有在当前GT内的anchor才能作为正样本;
- 满足条件2的前提下,基于 alignment_metrics 选取 topK 大的作为正样本,其余作为负样本进行训练;
# 1. 基于分类分数与回归的 IoU 计算对齐分数 alignment_metrics
alignment_metrics = bbox_scores.pow(self.alpha) * overlaps.pow(
self.beta)
# 2. 保证中心点在 GT 内部的 mask
is_in_gts = select_candidates_in_gts(priors, gt_bboxes)
# 3. 选取 TopK 大的对齐分数的样本
topk_metric = self.select_topk_candidates(
alignment_metrics * is_in_gts,
topk_mask=pad_bbox_flag.repeat([1, 1, self.topk]).bool())
5.损失函数
5.1 概述
- Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支
- 分类分支依然采用 BCE Loss
- 回归分支使用了 Distribution Focal Loss(DFL Reg_max默认为16)+ CIoU Loss。
- 3 个Loss 采用一定权重比例加权即可
5.2 Distribution Focal Loss
常规的坐标点回归方式是一种狄拉克分布,即认为某一点的概率无穷大,而其他点的概率为0(概率密度是一条尖锐的竖线),这种方式认为标签是绝对正确的;在实际应用中,对于遮挡、模糊场景下目标框的边界存在一定的不确定性,如滑板左侧边界和大象右侧边界;而常规的回归方式不能解决这种不确定的问题,所以这种情况下学习边界一个分布更为合理;
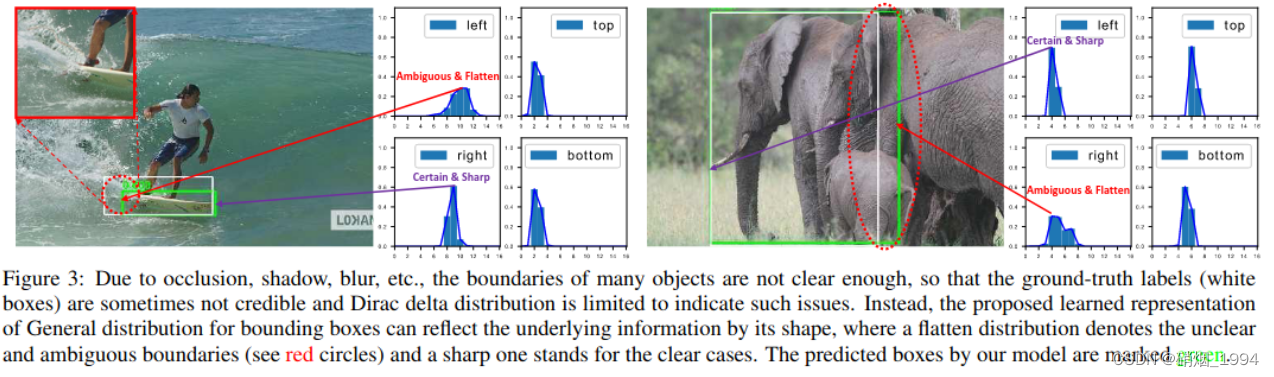

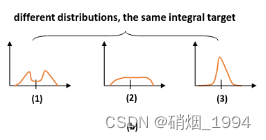
但如果分布过于任意,网络学习的效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式。考虑到真实的分布通常不会距离标注的位置太远,因此优化与标签y最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去较为合理;也就是说网络学出来的分布理论上是在真实浮点坐标的附近,并且以线性插值的模式得到距离左右整数坐标的权重。
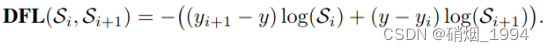
具体执行
- 网络此时回归的不是4个坐标点的信息,而是ltrb四个值(距离匹配到的anchor点的距离值)
- 其输出的channel为4 *regmax,regmax代表目标边界在当前特征图下距离anchor点的最大偏移量,默认为16
- 训练阶段:以左侧边界left为例进行说明,现将标签转换为ltrb形式 y = ( l e f t − 匹配到的 a n c h o r 中心点 x 坐标 ) / 当前的下采样倍数 y= (left-匹配到的anchor中心点x坐标)/当前的下采样倍数 y=(left−匹配到的anchor中心点x坐标)/当前的下采样倍数
- 假设计算得到的结果为3.2,则左右两侧的值为yi = 3, y(i+1)=4
- 推理阶段:先对网络输出的16个格子进行softmax操作转换为概率值,随后对结果进行积分(对离散变量就是累积求和) ,求得坐标偏移量,最后乘以下采样的倍数加上匹配到的anchor中心点坐标
def distribution_focal_loss(pred, label):
r"""
参数:
pred (torch.Tensor): 预测的bbox的分布(未经softmax)(N, n+1),
n是y的最大值对应的下标,配置里是reg_max,具体见论文.
label (torch.Tensor): anchor中心到gt bbox四条边的距离标签(N,).
返回值:
torch.Tensor: 损失张量 (N,).
"""
#将label 划分到 dis_left 和 dis_right 两个整数之间
dis_left = label.long()
dis_right = dis_left + 1
# label 与其右边界的差值
weight_left = dis_right.float() - label
# label 与其左边界的差值
weight_right = label - dis_left.float()
# 求交叉熵损失乘权重
loss = F.cross_entropy(pred, dis_left, reduction='none') * weight_left \
+ F.cross_entropy(pred, dis_right, reduction='none') * weight_right
return loss
几点理解
- DFL通过将bbox的位置建模为一般分布,希望网络能够快速地聚焦到标注位置附近的数值,使得它们概率尽可能大;
- 这种方式提供了更多信息和精确的估计:额外提供了一个目标框不确定性程度的指标(分布越陡峭,证明越确定,否则越不确定);
- 以reg-max=16, 输出的是16个位置的概率,而每一个位置对应的是在当前下采样特征图上目标各边缘距离匹配到的anchor中心点的偏差;因此最大偏差为16*32=512,该值需要大于输入分辨率的一半,如果没有大于,需要增大reg-max;
-更多关于的Distribution Focal Loss说明,请参考大白话 Generalized Focal Loss
6.总结
- Yolov8是v5团队的又一力作,从网络结构、正样本匹配策略、损失函数等角度对算法进行了优化,这也是yolo系列算法一直以来的优化路径。
- Yolov8目前阶段实现了新的 SOTA,同时相对于Yolov5来说整体优化效果很明显,也就意味着v5可能会慢慢退出历史舞台;但相对于Yolov7而言,其实优化效果不是很明显;
- 结合Yolox和Yolov8的一系列更新来看,目标检测的趋势更多的是朝着Anchor_free和Dynamic label assignment分配的方向发展,目前这两个方向都有较多的研究,就看未来是否有质的突破。