yolov8的安装命令
安装命令:pip install ultralytics (不推荐)
推荐方式,源码安装:pip install -e . (下载代码,并进入目录)
1、数据集转换
Labelme标注软件生成Json文件,该文件不能直接用于训练,需要转换成yolo格式数据。具体内容详见:https://blog.csdn.net/m0_74259636/article/details/132768892?spm=1001.2014.3001.5502
2、数据集划分
2.1 训练集、验证集、测试集的作用
训练集 训练集是用于训练模型的数据集。模型通过训练集学习输入和输出之间的映射关系,以便在预测新数据时能够提供准确的输出。训练集通常占总数据集的大部分,并且应该尽可能包含各种可能的输入数据和输出标签,以确保模型能够泛化到未见过的数据。
验证集 验证集是用于验证模型在训练过程中的性能和选择合适的超参数的数据集。在训练过程中,模型通常需要进行调整和优化,以获得更好的性能。为了防止过拟合或欠拟合等问题,需要使用验证集来评估模型的性能,并选择最佳的超参数。验证集通常是从训练集中随机选择一部分数据。
测试集 测试集是用于评估模型泛化性能的数据集。模型在训练集和验证集上获得良好的性能并不意味着它可以在未见过的数据上表现良好。为了评估模型的泛化性能,需要使用测试集来测试模型对未见过的数据的预测能力。测试集应该与训练集和验证集是相互独立的,以确保测试结果的准确性。
总之,训练集、验证集和测试集在机器学习中扮演着重要的角色。训练集用于训练模型,验证集用于选择最佳的超参数和评估模型的性能,测试集用于评估模型的泛化性能。划分数据集时应该注意保持数据的独立性和随机性,以避免过拟合和欠拟合等问题。
以上内容参考自:https://blog.csdn.net/gu1857035894/article/details/129445998
数据集划分为训练集验证,集测试集这只是一种划分方法,也有的人将数据集划分为验证集测试集两部分。
划分两部分时,训练集充当了训练模型超参数调节的作用。
这里模型的超参数是指训练的epoch数,batchsize数,学习率,模型的结构(在yolov8项目中,指nsmlx5种模型结构)等。
2.2 划分代码
import os
from PIL import Image
import numpy as np
from random import shuffle
from pathlib import Path
import random,shutil
#划分数据集
def split_data(path="",image='image',label='labels',seed=1234,test_rate=0.15,val_rate=0.15):
var_path=Path(path)
path_dir=var_path.name
path_parent=str(var_path.parent)+'//'
datalist=os.listdir(path)
datalist=[path+x for x in datalist]
random.seed(seed)
random.shuffle(datalist)
test_len=int(test_rate*len(datalist))
val_len=int(val_rate*len(datalist))
train_len=len(datalist)-test_len-val_len
if not Path(path_parent+'train').exists():
Path(path_parent+'train').mkdir()
Path(path_parent+'val').mkdir()
Path(path_parent+'test').mkdir()
Path(path_parent+'train/%s'%image).mkdir()
Path(path_parent+'train/%s'%label).mkdir()
Path(path_parent+'val/%s'%image).mkdir()
Path(path_parent+'val/%s'%label).mkdir()
Path(path_parent+'test/%s'%image).mkdir()
Path(path_parent+'test/%s'%label).mkdir()
for i in range(len(datalist)):
if i<train_len:
target='/train'
elif i<train_len+val_len:
target='/val'
else:
target='/test'
image_path=datalist[i]
labels_path=image_path.replace('/'+path_dir+'/','/%s/'%label).replace('.jpg','.txt')
target_iamge_path=path_parent+target+'/%s'%image
target_labels_path=path_parent+target+'/%s'%label
if os.path.exists(labels_path):
shutil.copy(image_path, target_iamge_path)
shutil.copy(labels_path, target_labels_path)
else:
print(labels_path,"缺失!!!!!!")
if __name__ == "__main__":
print("Generate txt in ImageSets.")
path=r"D:/yolo_seq/fire_smoke/data/image/"
split_data(path,image='image',label='labels',seed=1234,test_rate=0.15,val_rate=0.15)
print("Generate txt finish!!!!!!!")
部分参数详解:
Split_data 函数:实现了数据集按比例划分的功能,其中训练集占70%,测试集和验证集各占15%;
seed=1234:设置的划分数据集的随机种子数,确保每次划分结果一致:
test_rate=0.15,val_rate=0.15:测试集和验证集所占比例;
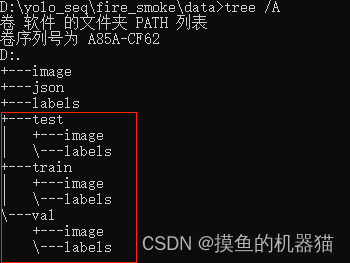
划分后的数据路径如下图所示,其中红框部分为划分结果。
3. 模型训练
3.1 数据说明
data.yaml 的具体内容如下所示:
path: D:/yolo_seq/cardboard_yolo
train: # train images (relative to 'path')
- images/train
val: # val images (relative to 'path')
- images/val
test: # test images (optional)
- images/test
# Classes 类别设置根据json 文件里的类别进行设置
names:
0: defect
3.2 CLI模式
注意相对路径和绝对路径之间转换关系。CLI命令以其所在的路径为相对起点路径,其中参数的路径“./”等价于CLI命令所在的路径。
训练命令
从头开始训练, model=yolov8s.yaml 表明基于yolov8s模型从头开始训练,data=./data.yaml数据路径
yolo task=detect mode=train model=yolov8s.yaml data=./data.yaml epochs=80 batch=16 workers=8
常规训练, 基于官方发布的yolov8s.pt模型开始训练
yolo task=detect mode=train model=yolov8s.pt data=./data.yaml epochs=80 batch=16 workers=8
中断恢复 model为上一次训练中断后的last.pt
yolo task=detect mode=train model=./runs/detect/train/weights/last.pt data=./data.yaml epochs=80 batch=16 workers=8 resume=True
验证命令
model为已经训练好的模型
yolo task=detect mode=val model=weights/best.pt data=data.yaml device=0
预测命令
model为训练好的最佳模型
yolo predict model=./runs/detect/train7/weights/best.pt source=D:/AI_toolV.13/_TongYongNengli/1.jpg show classes=1
3.3 代码模式
训练代码
from ultralytics import YOLO
if __name__ == '__main__':
#训练 https://docs.ultralytics.com/modes/train/
model = YOLO('yolov8s.yaml')
model = model.load('yolov8s.pt') # 加载预训练权重
# Train the model
results = model.train(data='data.yaml', epochs=10, workers=4,batch=16
代码运行时输出结果如下:
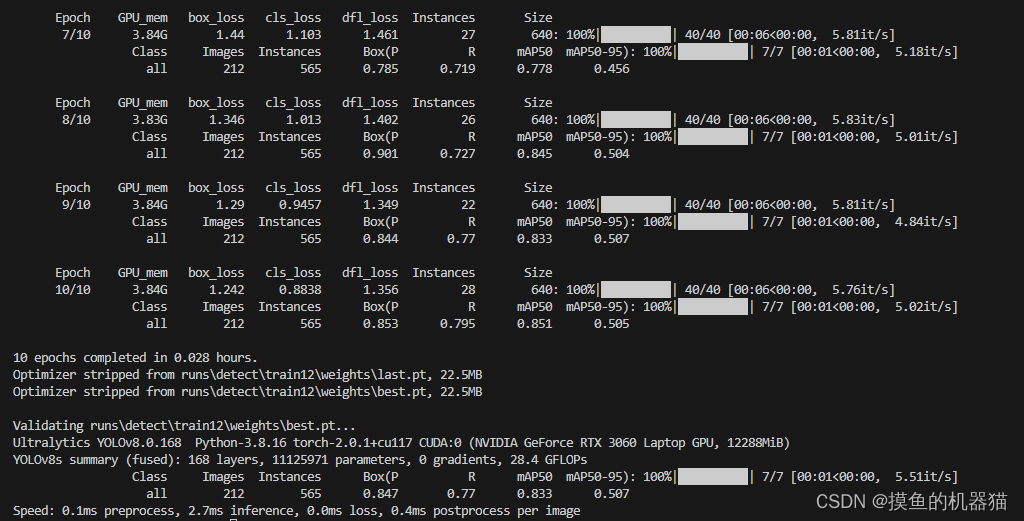
运行时相关图片如下所示,其中labels描述了class的频率信息,result描述了训练过程中的loss、精度信息、train_batch*.jpg对训练数据进行了部分可视化、results.csv保存了详细的训练过程信息。

验证代码
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/detect/train11/weights/best.pt') # load a custom model
# # Validate the model
metrics = model.val(data='data.yaml')
预测代码
支持预测单张图片图片路径和多张图片图片文件夹路径
from ultralytics import YOLO
if __name__ == '__main__':
#预测
model = YOLO('runs/detect/train11/weights/best.pt')
results = model.predict('D:/yolo_seq/cardboard_yolo/images/predic',save_txt=True, exist_ok=True)
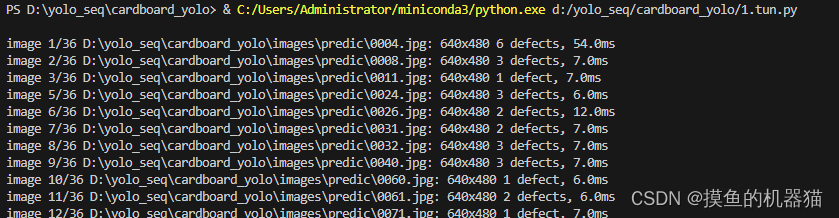
预测多张图运行结果如下: