对于嘈杂的梯度,我们在选择学习率需要格外谨慎。 如果衰减速度太快,收敛就会停滞。 相反,如果太宽松,我们可能无法收敛到最优解。
泄漏平均值
小批量随机梯度下降作为加速计算的手段。 它也有很好的副作用,即平均梯度减小了方差。 小批量随机梯度下降可以通过以下方式计算:
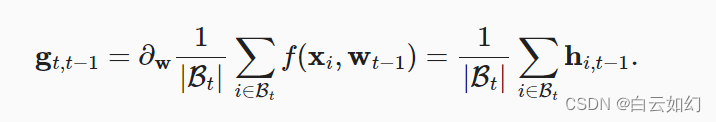
为了保持记法简单,在这里我们使用时间时更新的权重
。 如果我们能够从方差减少的影响中受益,甚至超过小批量上的梯度平均值,那很不错。 完成这项任务的一种选择是用泄漏平均值(leaky average)取代梯度计算:
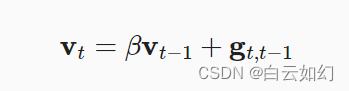
其中。 这有效地将瞬时梯度替换为多个“过去”梯度的平均值。
被称为动量(momentum), 它累加了过去的梯度。 为了更详细地解释,让我们递归地将
扩展到
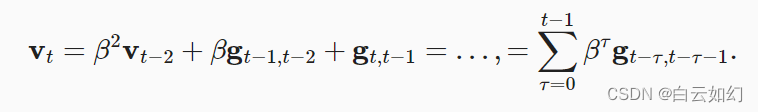
其中,较大的相当于长期平均值,而较小的
相对于梯度法只是略有修正。 新的梯度替换不再指向特定实例下降最陡的方向,而是指向过去梯度的加权平均值的方向。 这使我们能够实现对单批量计算平均值的大部分好处,而不产生实际计算其梯度的代价。
上述推理构成了“加速”梯度方法的基础,例如具有动量的梯度。 在优化问题条件不佳的情况下(例如,有些方向的进展比其他方向慢得多,类似狭窄的峡谷),“加速”梯度还额外享受更有效的好处。 此外,它们允许我们对随后的梯度计算平均值,以获得更稳定的下降方向。 诚然,即使是对于无噪声凸问题,加速度这方面也是动量如此起效的关键原因之一。