动量法
提出动机
在SGD的每次迭代中,梯度下降根据自变量当前位置,沿着当前位置的梯度更新自变量。然而,如果自变量的迭代方向仅仅取决于自变量当前位置可能会带来一些问题。
我们考虑一个二维输入向量 x = [ x 1 , x 2 ] T x = [x_1,x_2]^T x=[x1,x2]T和目标函数 f ( x ) = 0.1 x 1 2 + 2 x 2 2 f(x) =0.1x_1^2+2x_2^2 f(x)=0.1x12+2x22。
import numpy as np
import matplotlib.pyplot as plt
# 目标函数
def f_2d(x1, x2):
return 0.1 * x1 ** 2 + 2 * x2 ** 2
# 目标函数的梯度
def gd_2d(x1, x2, s1, s2, eta=0.4):
return (x1 - eta * 0.2 * x1, x2 - eta * 4 * x2, 0, 0)
# x参数为起始位置,s是自变量状态
def train_2d(trainer, iters=20, x1=-5, x2=-2, s1=0, s2=0):
results = [(x1, x2)]
for i in range(iters):
x1, x2, s1, s2 = trainer(x1, x2, s1, s2)
results.append((x1, x2))
print('epoch {}, x1 {}, x2 {}'.format(i+1, x1, x2))
return results
# 梯度下降过程
def show_trace_2d(f, results, xrange=np.arange(-5.5, 1.0, 0.1), yrange=np.arange(-3.0, 2.0, 0.1)):
plt.plot(*zip(*results), '-o', color='#ff7f0e')
x1, x2 = np.meshgrid(xrange, yrange)
plt.contour(x1, x2, f(x1, x2), colors='#1f77b4')
plt.xlabel('x1')
plt.ylabel('x2')
利用如下代码画出运行轨迹。
show_trace_2d(f_2d, train_2d(gd_2d))
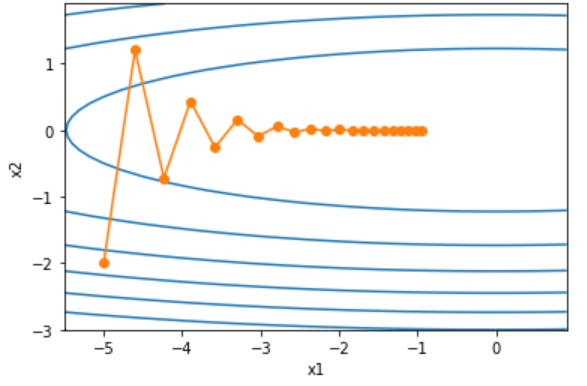
我们发现,最开始的几次迭代在梯度陡峭的方向进行较大的更新,但是这种震荡恰恰是我们不太需要的。我们更希望向梯度较为平缓的方向进行更新。如果调大学习率,在梯度较为平缓的方向进行的更新确实会增大,但是也可能导致参数最后没有收敛到最优解。
动量法
我们定义动量超参数 γ \gamma γ,范围是 [ 0 , 1 ) [0,1) [0,1)。取零时,等同于小批量随机梯度下降。在时间步 t t t的小批量随机梯度为 g t g_t gt,学习率是 η t \eta_t ηt。对每次迭代做如下改动
v t = γ v t − 1 + η t g t x t = x t − 1 − v t v_t = \gamma v_{t-1} + \eta_tg_t \\\\ x_t = x_{t-1} - v_t vt=γvt−1+ηtgtxt=xt−1−vt
利用代码画出更新过程。
def momentum_2d(x1, x2, v1, v2, eta=0.4, gamma=0.5):
v1 = gamma * v1 + eta * 0.2 * x1 ## 此处导数是硬编码
v2 = gamma * v2 + eta * 4 * x2 ## 此处导数是硬编码
return x1 - v1, x2 - v2, v1, v2
show_trace_2d(f_2d, train_2d(momentum_2d))
我们发现轨迹在上下方向的振幅减小了,而且更快收敛到了最优解。

指数加权移动平均
学过时间序列的同学可能对加权移动平均非常熟悉。当前时间步 t t t的变量 y t y_t yt是上一时间步改变量的值和当前时间步另一变量 x t x_t xt的线性组合。
y t = γ y t − 1 + ( 1 − γ ) x t y_t = \gamma y_{t-1} + (1-\gamma) x_t yt=γyt−1+(1−γ)xt
如果我们将这个通项公式进行展开,
y t = ( 1 − γ ) x t + γ y t − 1 = ( 1 − γ ) x t + ( 1 − γ ) γ x t − 1 + γ 2 y t − 2 = ( 1 − γ ) x t + ( 1 − γ ) γ x t − 1 + ( 1 − γ ) γ 2 x t − 2 + γ 3 y t − 3 . . . . y_t = (1-\gamma) x_t + \gamma y_{t-1}\\\\ = (1-\gamma) x_t + (1-\gamma) \gamma x_{t-1} + \gamma^2 y_{t-2}\\\\ = (1-\gamma) x_t + (1-\gamma) \gamma x_{t-1} + (1-\gamma) \gamma^2 x_{t-2} + \gamma^3 y_{t-3}\\\\ .... yt=(1−γ)xt+γyt−1=(1−γ)xt+(1−γ)γxt−1+γ2yt−2=(1−γ)xt+(1−γ)γxt−1+(1−γ)γ2xt−2+γ3yt−3....
令 n = 1 / ( 1 − γ ) n=1/(1-\gamma) n=1/(1−γ),可以得到
( 1 − 1 n ) n = γ 1 1 − γ (1- \frac 1 n)^n = \gamma^{\frac 1 {1-\gamma}} (1−n1)n=γ1−γ1
我们知道
l i m n → ∞ ( 1 − 1 n ) n = e x p ( − 1 ) ≈ 0.3679 lim_{n \rightarrow \infty} (1 - \frac 1 n)^n = exp(-1) \approx 0.3679 limn→∞(1−n1)n=exp(−1)≈0.3679
所以,当 γ → 1 \gamma \rightarrow 1 γ→1时, γ 1 1 − γ = e x p ( − 1 ) \gamma^{\frac 1 {1-\gamma}} = exp(-1) γ1−γ1=exp(−1)。我们可以将 e x p ( − 1 ) exp(-1) exp(−1)当成一个很小的数,从而在通项公式展开中忽略带有这一项(或者更高阶)的系数的项。因此,在实际中,我们常常将 y t y_t yt看成是对最近 1 1 − γ \frac 1 {1-\gamma} 1−γ1个时间步的 x t x_t xt值的加权平均。距离当前时间步 t t t越近的 x t x_t xt值获得的权重越大(越接近1)。
我们可以对动量法的速度变量做变形。
v t = γ v t − 1 + ( 1 − γ ) ( η t 1 − γ g t ) v_t = \gamma v_{t-1} + (1-\gamma) (\frac {\eta_t} {1-\gamma} g_t) vt=γvt−1+(1−γ)(1−γηtgt)
由指数加权移动平均的形式可得,速度变量 v t v_t vt实际上对序列 η t 1 − γ g t \frac{\eta_t} {1-\gamma} g_t 1−γηtgt做了指数加权移动平均。动量法在每个时间步的自变量更新量近似于将前者对应的最近 1 / ( 1 − γ ) 1/(1−\gamma) 1/(1−γ)个时间步的更新量做了指数加权移动平均后再除以 1 − γ 1−\gamma 1−γ。所以,在动量法中,自变量在各个方向上的移动幅度不仅取决于当前梯度,还取决于过去的各个梯度在各个方向上是否一致。如果一致,则会加速,使自变量向最优解更快移动。
代码实现
def init_momentum_states(dim=2):
v_w = np.zeros((dim, 1))
v_b = np.zeros(1)
return (v_w, v_b)
def sgd_momentum(params, states, hyperparams):
for p, v in zip(params, states):
v[:] = hyperparams['momentum'] * v + hyperparams['lr'] * p.grad
p[:] -= v