遥感图像目标检测
遥感图像特殊性
- 尺度多样性:航空遥感图像可从几百米到近万米的高度进行拍摄,且地面目标即使是同类目标也大小不一,如港口的轮船大的有300多米,小的却只有数十米。
- 视角特殊性:航空遥感图像的视角基本都是高空俯视,但常规数据集大部分还是地面水平视角,所以同一目标的模式是不同的,在常规数据集上训练的很好的检测器,使用在航空遥感图像上可能效果很差。
- 小目标问题:航空遥感图像的目标很多都是小目标(几十个甚至几个像素),这就导致目标信息量不大,基于CNN的目标检测方法在常规目标检测数据集上一骑绝尘,但对于小目标检测而言,CNN的Pooling层会让信息量进一步减少,一个24*24的目标经过4层pooling后只有约1个像素,使得维度过低难以区分。
- 多方向问题:航空遥感图像采用俯视拍摄,目标的方向都是不确定的(而常规数据集上往往有一定的确定性,如行人、车辆基本都是立着的),目标检测器需要对方向具有鲁棒性。
- 背景复杂度高:航空遥感图像视野比较大(通常有数平方公里的覆盖范围),视野中可能包含各种各样的背景,会对目标检测产生较强的干扰。
一、目标检测研究综述
1.介绍
目标检测一直以来都是计算机视觉领域的研究热点之一,其任务是返回给定图像中的单个或多个特定目标的类别与矩形包围框坐标。目标检测任务具有很高的挑战性和更加广阔的应用前景,如自动驾驶、人脸识别、行人检测、医疗检测等等。同时,目标检测也可以作为图像分割、图像描述、目标跟踪、动作识别等更复杂的计算机视觉任务的研究基础。
- General Object Detection:探索在统一的框架下检测不同类型物体的方法,以模拟人类的视觉和认知。
- Detection Applications:特定应用场景下的检测,如行人检测、人脸检测、文本检测。
2.传统目标检测
早期的目标检测算法大多是基于手工特征构建的。由于当时缺乏有效的图像表示,人们别无选择,只能设计复杂的特征表示,以及各种加速技术来用尽有限的计算资源。
- Viola Jones Detectors
18年前,P.Viola和M.Jones在没有任何约束条件(如肤色分割)的情况下首次实现了人脸的实时检测。在700MHz Pentium III CPU上,在同等检测精度下,检测器的速度是其他算法的数十倍甚至数百倍。这种检测算法,后来被称为“维奥拉-琼斯”(VJ)检测器”。VJ检测器采用最直接的检测方法。即,滑动窗口:查看图像中所有可能的位置和比例,看看是否有窗口包含人脸。VJ检测器结合了 “ 积分图像 ”、“ 特征选择 ” 和 “ 检测级联 ” 三种重要技术,大大提高了检测速度。 - HOG Detector
方向梯度直方图(HOG)特征描述符最初是由N.Dalal和B.Triggs在2005年提出的。HOG可以被认为是对当时的尺度不变特征变换(scale-invariant feature transform)和形状上下文(shape contexts)的重要改进。为了平衡特征不变性 ( 包括平移、尺度、光照等 ) 和非线性 ( 区分不同对象类别 ),将HOG描述符设计为在密集的均匀间隔单元网格上计算,并使用重叠局部对比度归一化 ( 在“块”上 ) 来提高精度。虽然HOG可以用来检测各种对象类,但它的主要动机是行人检测问题。若要检测不同大小的对象,则HOG检测器在保持检测窗口大小不变的情况下,多次对输入图像进行重新标度。多年来,HOG检测器一直是许多目标检测器和各种计算机视觉应用的重要基础。 - Deformable Part-based Model (DPM)
DPM作为voco -07、-08、-09检测挑战的优胜者,是传统目标检测方法的巅峰。DPM最初是由P.Felzenszwalb提出的,于2008年作为HOG检测器的扩展,之后R.Girshick进行了各种改进。DPM遵循“分而治之”的检测思想,训练可以简单地看作是学习一种正确的分解对象的方法,推理可以看作是对不同对象部件的检测的集合。一个典型的DPM检测器由一个根过滤器(root-filter)和一些零件滤波器(part-filters)组成。该方法不需要手动指定零件滤波器的配置 ( 如尺寸和位置 ),而是在DPM中开发了一种弱监督学习方法,所有零件滤波器的配置都可以作为潜在变量自动学习。R.Girshick将这个过程进一步表述为一个多实例学习的特殊案例,“硬负挖掘”、“边界框回归”、“上下文启动”等重要技术也被用于提高检测精度。为了加快检测速度,R.Girshick开发了一种技术,将检测模型 “ 编译 ” 成一个更快的模型,实现了级联结构,在不牺牲任何精度的情况下实现了超过10倍的加速度。
3.基于深度学习目标检测
随着手工特征的性能趋于饱和,目标检测在2010年之后达到了一个稳定的水平。R.Girshick等人在2014年率先将卷积神经网络应用到目标检测中,提出了具有CNN特征的区域(RCNN)用于目标检测。从那时起,目标检测开始以前所未有的速度发展。
目标检测算法主要分为三个步骤:图像特征提取、候选区域生成与候选区域分类
R-CNN系列为代表的两阶段算法
首先在图像上通过启发式方法或者卷积神经网络生成一系列可能存在潜在目标的候选区域,然后对每一个候选区域依次进行分类与边界回归。
- R-CNN
(1)采用选择性搜索生成可能包含潜在目标的候选区域;(2)将所有候选区域采样至某一固定分辨率后,逐一输入卷积神经网络,提取出固定长度的特征向量;(3)采用多个支持向量机对所有特征向量进行分类;(4)根据已知类别和提取出的特征向量,对矩形框进行回归修正,从而进一步提高定位精度。
优势:相较于传统算法,R-CNN的最大创新点在于不再需要人工设计特征算子,而是引入卷积神经网络去自动学习如何更好地提取特征,实验结果也证明这样做是更有效的。
缺陷:(1)虽然在提取特征向量时使用了CNN,但生成候选区域采用的选择性搜索算法却还是基于底层视觉特征,因此候选框质量不高;(2)算法的三个模块是相互独立的,导致训练过程繁琐,无法实现端到端的训练,且不能获得全局最优解;(3)在提取特征向量时,每个候选区域都会被单独从原图上裁剪下来,再依次输入神经网络,这样做既占用了大量磁盘空间,也带来了很多的重复计算,导致训练速度和推断速度都非常缓慢。 - SPP-Net
不再将候选区域依次通入CNN,而是直接计算整张图的特征图,然后划分出每一个候选区域的特征。在全连接层之前,为了统一特征向量的长度,新增一个SPP层,通过池化操作将任意输入都转化为固定长度的输出。
优势:显著加速了训练和推断的过程。
缺陷:SPP-Net的精度和R-CNN并无明显差别,而且它的算法流程依旧是独立的多个模块,保存特征向量依旧需要大量存储空间。 - Fast R-CNN
Fast R-CNN吸纳了SPP-Net的思想,对整张图进行一次性的特征计算,新提出的RoI池化层相当于SPP层的简化版。除此以外,Fast R-CNN为了简化流程,不再使用支持向量机进行分类,也不再使用额外的回归器,而是设计了多任务损失函数,直接训练CNN在两个新的网络分支上分别进行分类和回归。
优势:将特征提取、分类、回归整合为了一步,这样就不再需要中途保存特征向量,解决了存储空间的问题;而且在训练时能够进行整体的优化,因此取得了更高的精度。
缺陷:(1)候选框的生成依旧是完全独立的。选择性搜索等传统算法是基于图像的底层视觉特征直接生成候选区域,无法根据具体的数据集进行学习。(2)选择性搜索非常耗时。在 CPU上处理一张图像需要 2秒。 - Faster R-CNN
设计了RPN候选框生成网络。(1)RPN的输入是已有的Fast R-CNN的骨架网络所提取的整张图像的特征图,这种共享特征的设计既充分利用了CNN的特征提取能力,又节省了运算;(2)提出了锚点(Anchor)概念, RPN基于预先设定好尺寸的锚点进行分类(前景或背景)和回归,既确保了多尺度的候选框的生成,也让模型更易于收敛。RPN生成候选区域之后,算法剩余的部分和Fast R-CNN一致。
优势:RPN取代选择性搜索算法,Faster R-CNN最终在GPU上的检测速度达到了5FPS,打破了PASCAL VOC数据集的记录;同时,它还是第一个真正实现了端到端训练的检测算法,标志着两阶段检测器的正式成型。
自Faster R-CNN问世之后,新诞生的两阶段检测器几乎都是以它为雏形。Dai等人提出的R-FCN为了进一步提高Faster R-CNN的效率,去除了各分支独立的计算耗时的全连接层,设计了位置敏感得分图和位置敏感RoI池化层来保留空间信息,显著提高了推断速度与精度。Lin等人考虑到网络深层特征有较强语义信息,而浅层特征有较强空间信息,提出了将深层特征图通过多次上采样和浅层特征图逐一结合的FPN架构,基于多层融合后的特征图进行输出,能够更好地检测到不同尺度的目标,是多尺度目标检测的里程碑。He等人提出的Mask R-CNN在Faster R-CNN基础上将RoI池化层替换成了RoI对齐层,使得特征图和原图像素的能对齐得更精准,并新增了一个掩膜分支用于实例分割。令人惊讶的是,该算法不仅在实例分割任务上取得了优秀表现,对分类、回归、掩膜分支同时进行多任务训练也提高了目标检测任务的性能。 Qin等人则提出了轻量级的二阶段检测器ThunderNet:通过为检测任务定制的轻量级骨架网络SNet、对RPN和检测头的压缩和CEM、SAM等模块的引入,让模型在速度和精度方面超越了不少一阶段检测器。
YOLO、SSD为代表的一阶段算法
仅使用一个卷积神经网络直接在整张图像上完成所有目标的定位和分类,略过了生成候选区域这一步骤。
- OverFeat
(1)采用卷积层替代全连接层实现全卷积神经网络,适应不同分辨率的图像作为输入,相当于用卷积来快速实现滑动窗口算法;(2)采用同一个卷积神经网络作为共享的骨架网络,通过更改网络头部来分别实现分类、定位和检测任务。
优势:OverFeat比R-CNN的检测速度快了 9 倍。
缺陷:精度不如同期R-CNN。 - YOLO
将输入图像划分为7*7的网格,每一个网格负责预测中心点处于该网格内的目标,回归中心点相对于网格的位置、目标的长宽和类别。YOLO的损失函数由定位损失、置信度损失、分类损失三部分组成,其中置信度是指是否存在目标。可以看到,YOLO是一个端到端的算法,没有候选框这一概念,输入一张图片,在检测到前景的同时就回归得到了需要的属性。
优势:YOLO算法真正实现了实时性目标检测,其检测速度能够达到45FPS, Fast YOLO 甚至能到155FPS,比二阶段检测器快了一个数量级。除此以外,YOLO在检测时考虑了更多的背景信息,因此将背景误判为前景的概率比FastR-CNN要低很多。
缺陷:(1)每一个网格只检测2个目标,且规定为同一类别,导致算法难以处理密集目标的检测;(2)精度比Fast R-CNN要差,尤其体现在定位上,主要原因在于后者经过了从整体到局部的两次矩形框回归,而YOLO只经过了一次;(3)由于全连接层的存在,输入图像的分辨率是固定的;(4)只在单张特征图上检测目标,导致算法难以驾驭多尺度目标的检测。 - SSD
(1)训练网络在多个不同深度的特征层上预测不同尺度的目标,最后进行整合;(2)引入 Faster R-CNN的锚点概念,使模型更容易收敛,保证不同感受野的特征图适应不同尺度的目标检测;(3)使用全卷积神经网络,适应不同分辨率的图像输入;(4)损失函数由定位损失和分类损失组成,没有YOLO的前景置信度的概念,因为它在分类时直接将背景也视为一个类别,和其他类别同时进行预测。此外,SSD在特征图上铺设了密集的锚点,而有效匹配目标的锚点个数是很有效的,若直接进行采用所有样本进行训练,会存在严重的正负样本不平衡问题。于是,SSD采用了难例挖掘的手段来缓解这一问题。
优势:SSD的检测速度能和YOLO媲美,而精度能够匹敌Faster R-CNN。
缺陷:相对于Faster R-CNN,小目标的检测结果并未能得到明显改善。
新诞生的一系列一阶段检测器虽然普遍有着绝对的速度优势,但和顶尖的二阶段检测器也存在着不可忽视的精度差距。Lin 等人认为,两类算法最本质的区别在于后者通过对候选框的筛选,保证了第二阶段训练样本的高质量和类别的均衡,而前者必须在图像上每一个滑动窗口处进行预测,换言之即存在严重的正负样本不均衡和难易样本不均衡。因此,他们为一阶段检测器设计了新的损失函数Focal Loss。Focal Loss在交叉熵损失函数的基础上引入了两个新参数,一个用于降低负样本的权重,另一个用于降低简单样本的权重,让模型在训练时能够避免被一阶段算法存在的大量负样本、简单样本转移注意力。实验测试中,作者采用ResNet和特征金字塔网络架构设计了简单的一阶段检测器RetinaNet,并应用Focal Loss进行训练,最终在MS COCO测试集上展现出了超越Faster R-CNN的精度,尤其体现在小样本的检测上。YOLOv2之后,Redmon等再次对其进行升级,提出了YOLOv3。YOLOv3主要有三个改进点:(1)采用多个逻辑回归分类器取代softmax分类器,使模型能适用于类别间存在交集的分类任务;(2)引入特征金字塔网络架构,对最深层特征图进行两次上采样,分别与浅层特征相融合,最后在三个特征层上设置不同的锚点,预测不同尺度的目标;(3)学习残差网络的思想,设计了Darknet-53作为新的骨架网络,在精度上能和Resnet-101、 ResNet152相匹敌,而速度更快。YOLOv3在当时实现了最好的速度与精度的权衡,也是目前工业界目标检测的首选算法之一。
二、多尺度目标检测研究综述
检测器在面对尺度跨度较大的数据集时会表现不佳的根本原因,是因为卷积神经网络在不断加深的过程中,表达抽象特征的能力越来越强,但浅层的空间信息也相对丢失。这就导致深层特征图无法提供细粒度的空间信息对目标进行精确定位,同时小目标的语义信息也在下采样的过程中逐渐丢失。
在检测尺度较大、细节特征丰富的目标时,需要更强的语义信息作为分类依据;在检测尺度较小、偏差容忍度较小的目标时,则需要更细粒度的空间信息实现精确定位。
解决尺度问题的一个通用的思路:构建多尺度的特征表达

1.基于图像金字塔的多尺度目标检测
在训练阶段,随机输入不同尺度的图像,能够强迫神经网络适应不同尺度的目标检测;在测试阶段,对同一张图像以不同的尺度进行多次检测,最后采用非极大值抑制算法整合所有结果,能够使检测器覆盖尽可能大的尺度范围内的目标。
优势:一定程度上提升整体精度。
缺陷:高分辨率的图像输入既会增大内存开销,也会增加计算耗时。这不仅会导致训练时难以使用较大的批尺寸,影响模型精度,同时成倍增加的推断时间还会进一步抬高将算法投入实际应用的门槛。
基于尺度生成网络的图像金字塔
在进行多尺度检测时,金字塔的很多层实际上是没有检测到有效目标的,即存在着明显的资源浪费。其原因在于,每一张图像的目标的尺度分布都存在着显著差别:有的图像可能只有一种尺度的目标,因此实际只需要对金字塔的某一层进行检测;有的图像可能只有中等目标和大目标,因此金字塔里分辨率最高的那一层其实是不需要的,而那恰好是计算开销最大的一层。为了提高检测效率,他们认为:在正式进行目标检测之前,若能先判断图像内目标的尺度分布,就能去除图像金字塔中冗余的层,而且在已知目标尺度的情况下还可以对后续检测做进一步的优化。因此,他们设计了一个尺度生成网络,将原本的目标检测任务拆分为了尺度估计和单一尺度的目标检测这两步,如图所示。
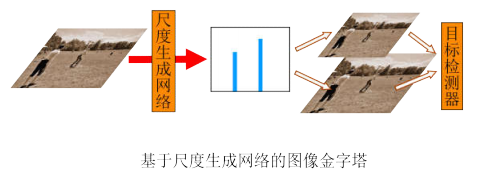
尺度生成网络基于图像级别的监督信号进行训练,输出尺度直方图向量,经过均值滤波和一维的非极大值抑制操作后得到离散的目标尺度分布。由于已知目标尺度,因此后续的检测器只需要检测单一尺度的目标,所以可以将RPN的锚点的尺寸数缩减为1,这样能在不影响精度的前提下进一步提高检测速度。最后,将图像依次采样至目标尺度所对应的分辨率,再轮流进行检测,最后对所有结果进行汇总,完成多尺度目标的检测。
基于尺度归一化的图像金字塔
Singh等人就MS COCO数据集中大量的小目标带来的挑战,提出了名为尺度归一化图像金字塔(简称SNIP)的训练策略:采用图像金字塔训练模型,但是每一层都只提供合适的尺度范围内的监督信号,如图所示。
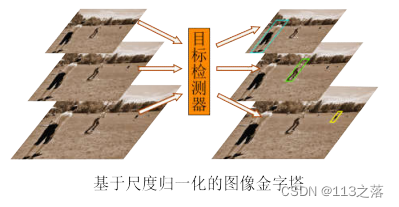
这样做的根本目的让模型专注于检测某一尺度范围内的目标,同时又通过金字塔的方式保证所有的训练数据都能够被学习。最后,在验证模型时同样采用图像金字塔。该策略可同时应用于Faster R-CNN的两个阶段,并对所有尺度的目标的检测精度带来全方位的提升。可以说,SNIP本质上是基于CNN的固有缺陷对传统的多尺度训练策略的一个改进,将图像金字塔的优势发挥到了机制。不过,该训练策略并未能解决图像金字塔的内存与时间开销问题。之后,Singh等人将SNIP升级为SNIPER。为了能够解决图像金字塔在训练时的内存限制,SNIPER不再是对完整的图像进行训练,而是从金字塔的每一层中裁剪出分辨率固定为512x512的碎片作为训练单元。其中,在不同层上以碎片大小为网格单元,选择囊括了该尺度下有效目标的网格作为碎片,即为训练时的正样本。而为了防止检测器将背景误判为目标,作者们也将包含了若干假正例的碎片作为负样本,共同参与训练。由于碎片的分辨率较小,因此就有效解决了图像金字塔的内存问题,在训练时可以使用更大的批尺寸,这样既加快了训练速度,也提高了模型的检测精度。不过,在实际应用模型检测目标时,仍然必须通入完整的图像金字塔,因此推断的计算耗时问题还有待解决。
基于注意力机制的图像金字塔
最早在深度学习目标检测中引入放大操作的是Lu等人提出的AZ-Net。他们认为RPN网络的锚点策略本质上是一个固定了滑动窗口大小的穷举算法,既效率不高,也对多尺度的目标不具备适用性。因此,他们设计了一个自适应搜索的候选区域生成算法AZ-Net。算法以整张图像作为搜索起点,提供邻接区域预测和放大指示器两种输出,前者指和该搜索区域尺度接近的一系列候选区域,后者是用于指示当前搜索区域内是否存在更小的目标。若存在,则将整张图像分为左上、左下、右上、右下、中间五个区域,依次作为新的搜索起点,直到所有区域都不再包含小目标为止。在PASCAL VOC数据集上的实验表明,该算法生成的候选区域比RPN网络生成的候选区域数量更少但质量更高,不过精度优势并不明显。Gao等人延续了AZ-Net的搜索的思想,通过引入具有决策能力的强化学习,设计了一个由粗到精的策略来检测高分辨率图像中的目标:首先用一个粗糙的Fast R-CNN对下采样后的低分辨率图像进行检测,生成准确率提升概率图,然后利用强化学习找到有可能包含小目标的区域,采用更精细的检测器对高分辨率的该区域进行目标检测,同时将该区域作为新的算法输入,再次通入粗糙检测器,如此循环,直到不再包含小目标。实验结果表明,在几乎未损失精度的前提下,该算法在Caltech行人检测数据集上的像素处理数量减少了50%、推断时间减少了25%,在YFCC100M数据集上的像素处理数量减少了70%、推断时间减少了50%。Uzkent等人延续了Gao等人的做法,同样是引入强化学习选择图像中需进一步查看的区域,不过区别在于,算法还会判断该区域是由大目标主导还是小目标,然后分别通过两种不同尺度的检测器进行检测,其目的在于进一步节省计算量。总的来说,这些算法都是源于注意力机制的思想,将多尺度目标检测视为由粗到细、从整体到细节的递归过程,流程如图所示。
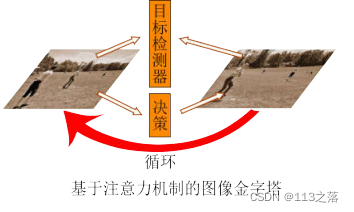
这些算法可以看作是对图像金字塔的优化:从金字塔的最顶端开始检测,并利用强化学习判断金字塔的下一层中的哪一部分区域存在潜在目标,如此循环,直到下一层不再包括目标为止。所以,算法相当于利用强化学习的决策能力做引导,去除了图像金字塔的冗余部分,解决了SNIPER策略中仍然存在的推断时计算耗时严重的问题。
2.基于网络内特征金字塔的多尺度目标检测
早期以R-CNN为代表的检测器直接在神经网络的最后一层特征图上进行预测,由于细粒度空间特征的缺失,对小目标的检测效果不佳,因此需寻求多尺度的特征表示。图像金字塔虽能基于不同分辨率的输入提取不同尺度的特征,但又会带来严重的内存和时间开销,不具备适用性。因此,如果能在卷积神经网络内部构建多尺度的特征表示,就能够在只输入一次图像的情况下近似地得到图像金字塔所能提取的多尺度特征,且计算代价要小得多。现阶段主要通过以下两种方式构建网络内的特征金字塔:(1)基于跨层连接融合网络内不同深度的特征图,得到不同尺度的特征表示;(2)基于感受野不同的并行支路,构建空间金字塔。
基于跨层连接构建特征金字塔
考虑到卷积神经网络的层层相叠的结构,越深的特征图的感受野越大,因此网络内不同深度的特征图就形成了天然的多尺度表达,于是SSD算法和MS-CNN算法均提出,可以直接在这些不同尺度的特征图上分别检测目标并最后进行整合,其中浅层特征图负责检测小目标,深层特征图负责检测大目标。但是,从实验结果来看,小目标的检测精度却并未得到明显改善。究其原因,在于这些特征层因为深度各不相同,特征表示能力也各不相同,存在着显著的语义鸿沟。浅层特征层虽然保留了更为细粒度的空间信息,但特征表示能力太弱,缺少有效的语义信息,所以检测效果差。因此,直接在网络内不同深度的特征图上预测不同尺度的目标是不合适的,需要首先构建出每一层都具有足够特征信息的特征金字塔。针对SSD算法存在的缺陷,Lin等人提出了著名的特征金字塔网络FPN。FPN的核心思想在于融合网络内部的不同深度的特征信息,但是由上至下逐层融合的结构是值得商酌的,因此出现了一系列对此进行讨论和改进的算法。
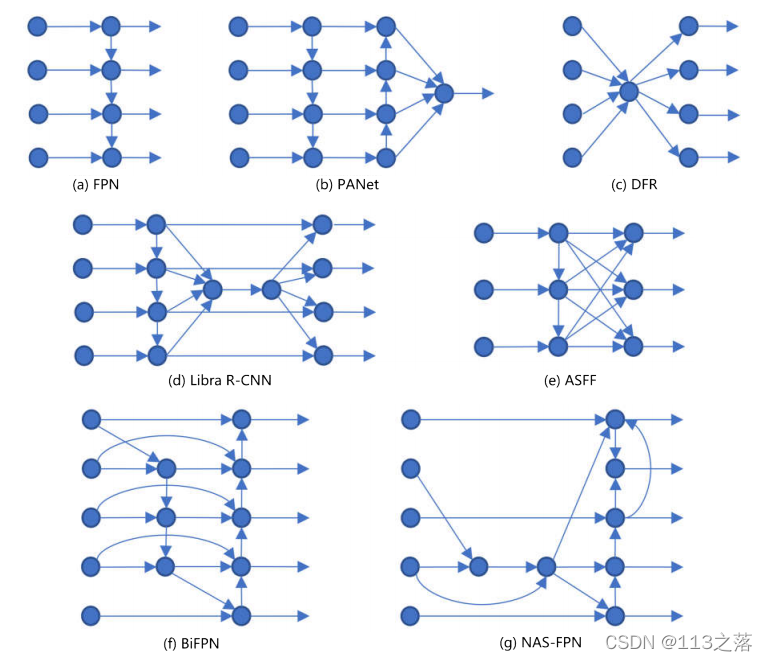
上述方法都是在针对FPN提出的特征融合的方式做出改变,而Li等人则是对FPN的骨架网络本身进行了改进。多数检测器都是采用分类网络作为骨架网络(例如 ResNet),预训练也是在分类数据集上完成,这带来了两个问题:(1)FPN等检测器引入了未参与预训练的额外的网络阶段;(2)骨架网络的感受野和下采样系数均较大,虽有利于图像分类,但空间信息的缺失不利于大目标的精确定位,下采样过程中语义信息的丢失不利于小目标的识别,即便是引入了FPN架构也没有解决本质问题。为此,他们专门针对检测任务的需求设计了新的骨架网络DetNet-59,相比起ResNet-50有三点主要的区别:(1)网络和FPN有着相同的阶段数量,因此所有阶段都可以参与预训练;(2)从第四阶段开始,DetNet的下采样系数固定为16,通道数固定为256;(3)在残差模块中引入空洞卷积增加感受野。从实验结果来看,DetNet的参数量介于ResNet-50和ResNet-101之间,但在检测任务上的性能表现要优于它们。具体到不同尺度的目标,会发现DetNet尤其擅长定位大目标和寻找小 目标,符合作者预期。
基于并行支路构建特征金字塔
构建多尺度的特征表达,可以在网络内设计参数不同的并行支路,每条支路基于各自的感受野提取不同空间尺度下的特征图,进而构建出空间金字塔。在深度学习领域,空间金字塔可以追溯到 GoogLenet提出的Inception模块,模块内包含了四个分支,其中前三个分支分别用1x1、3x3和 5x5的卷积核进行的卷积操作,第四条分支进行最大池化,最后将所有分支的输出融合,如图所示。
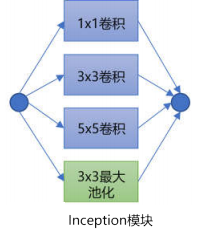
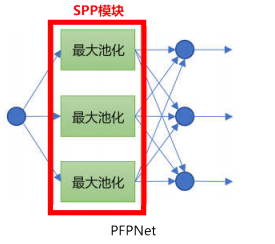
虽然具体的实现方法有很大差异,但Inception模块和SPM的思想是一致的,都是为了提取图像在不同空间尺度下的特征。SPP-Net的SPP模块同样是采用的SPM的多尺度分块的方法,对每一分块进行池化操作,就能将任意大小的特征图转换为固定长度的特征向量。总而言之,构建空间金字塔同样是解决目标检测的尺度问题的一个可行方案。Zhao等人为了将全局信息和局部信息相结合,设计了类似于SPP模块的金字塔池化模块,模块内包含了四条分别进行1x1、2x2、3x3、6x6池化的分支提取多尺度信息,在语义分割任务上效果有明显提升。Kim等人提出的PFPNet同样是出于融合不同尺度的上下文信息的思想,在一阶段检测器里引入了包含三条支路的SPP模块,不过每个分支池化得到的特征图还经过了作者设计的 MSCA模块,分别与另外两个分支的输出特征进行了融合,将另外两个分支的特征图进行上下采样,然后和主干支路进行特征拼接。最后,在三条支路的输出特征图上分别进行目标检测,采用非极大值抑制算法汇总结果。从MS COCO数据集的实验结果来看,PFPNet比使用FPN架构的YOLOv3还要略胜一筹,流程如图所示。
3.多尺度目标检测的其他策略
锚点
早期的目标检测为了检测到不同尺度的目标,除了采用固定大小的滑动窗口在图像金字塔上逐层滑动以外,还可以采用不同大小的滑动窗口轮流在同一张图上滑动。Ren等人提出的RPN网络引入的锚点这一概念,相当于在骨架网络提取的特征图上设置了九个不同大小的滑动窗口作为检测的先验信息,以确保网络能够尽可能覆盖更大的尺度范围内的目标。虽然模型对于小目标的检测精度并不理想,但多尺度的锚点策略还是成为了后来多数检测器的标配,结合特征金字塔甚至能够进一步扩大锚点的尺度范围。
缺陷:(1)锚点的尺寸需要预先定义,如果定义得不好会明显降低模型性能;(2)为了保证足够的召回率,往往需要大量的锚点,然而其中的大部分锚点都是对检测结果没有帮助的。
交并比阈值
在目标检测的训练过程中,我们通常基于预测矩形框和真实标签的交并比来确定正负样本,譬如交并比大于0.5的为正样本,小于0.3的为负样本。但是,这样的阈值设定主要是基于经验,并不一定是最优选择。而且,采用固定的交并比阈值对于多尺度目标检测来说更加不合适,因为相等的坐标偏差会对小目标的交并比造成更大影响,对于大目标的影响则微弱得多。为了尝试解决这一问题, Cai等人提出了Cascade R-CNN算法,将3个R-CNN网络分别设置0.5、0.6、0.7的交并比阈值,然后级联在一起。这样做的依据是,如果直接在单个网络上将交并比阈值提高,会使得正样本数量快速减少,导致了网络精度显著下降。因此,我们以级联的方式逐步提升生成的矩形框的质量,将前一个检测网络的输出作为后一个检测网络的输入,就能够不断适应更高的交并比阈值,且每一个网络都可以检测特定交并比范围内的目标。
缺陷:级联结构对于精度的提升是显著的,不过也明显增加了训练时间和推断时间。同样是考虑到固定的交并比阈值并不合理。
动态卷积
传统的卷积神经网络存在着一个固有缺陷:卷积核的大小是固定的,池化层的尺度也是固定的,这就导致了网络内所有特征层的感受野始终是固定的,不利于感知不同尺度的目标。因此,便有了一系列方法尝试将卷积操作动态化。例如,空洞卷积的提出,让卷积层能够在参数量不变的情况下,感受野随着空洞卷积系数单调变化,这也使得神经网络能够更方便地捕获多尺度的特征。Dai等人提出的可变卷积进一步的对卷积计算的每一个采样点的位置都增加了一个偏置,让卷积核呈现出各式各样的形状,空洞卷积相当于是可变卷积的一种特例。同样的,池化层也可以增加偏置,进而被改造为可变池化。从实验的可视化结果来看,可变卷积的确能帮助神经网络更好地适应不同形状和尺度的目标。不过,Zhu等人又发现可变卷积因为偏置不可控,引入了过多的可能造成负面影响的上下文信息。因此他们对可变卷积进行了升级,让其不仅能学习偏置,还能学习到每个采样点的权重,相当于局部的注意力机制。总体来说,可变卷积这一设计显著增加了卷积神经网络的自由度,可以很好地和其他检测器兼容。
缺陷:模型检测正确率得以提升,但是参数量也变为了原模型的3-4倍左右,因此目前而言难以推广到成熟的检测网络中。
边界框损失函数
L1和L2范数是经典的回归损失函数,在目标检测任务中可以用于对边界框进行回归。但是 L1损失函数的收敛速度较慢且解不稳定,L2损失函数对离群点敏感而不够鲁棒。因此Girshick提出了平滑L1损失函数,结合了两者的特点:相比起L1损失函数,在靠近真实值的时候,梯度值足够小,收敛更快;相比起L2 损失函数,离群点的梯度更小,更鲁棒。
缺陷:(1)都是对矩形框的顶点坐标和长宽的偏移进行惩罚,无法直接反映预测框与真实框的相似程度;(2)都不具备尺度不变性。为了解决这一问题,Yu 等人提出了交并比损失函数,将矩形框视为一个整体,直接对比例形式的交并比求对数来指导边界回归,因此该损失函数就具备了尺度不变性,相比起 L2 损失函数在处理多尺度的目标时有着明显的效果提升。
解耦分类与定位
目标检测任务包含了目标分类和目标定位两部分,Faster R-CNN等传统算法在第二阶段普遍通过共享的全连接层对候选区域进行特征提取,最后再在两个分支上分别进行分类和回归。Song等人基于热度图分析指出,分类任务的敏感区域为目标的显著性区域,而定位任务的敏感区域则是目标的边界区域,两者在空间上无法对齐。显然,对于多尺度目标检测,随着目标的尺度增大,分类和定位任务在空间上的不对齐问题也会愈加严重。同样地,Wu等人则从全连接层和卷积层的特性出发,认为前者的空间敏感性使它更适合于进行分类,后者的权重共享的特点使它提取出的特征的空间相关性更强,更适合回归边界,实验结果证明了这一观点。为了解决分类与回归问题潜在的冲突,最直观的思路就是将两个任务进行解耦。
小目标特征重建
在MS-CNN算法中,为了能够更好地检测尺度较小的目标,网络中设计了反卷积层来对特征图进行上采样,有效减少了内存占用和计算耗时。Zhou等人提出的STOD算法里,以DenseNet-169作为骨架网络,设计了尺度变换模块将最后的多个通道的特征图通过平铺展开的方式构造为了分辨率更高、通道数更少的特征图,用来检测小目标。Zhang等人提出的DES算法为了能够加强SSD的浅层特征在检测小目标时缺失的语义信息,设计了一个分割模块的分支进行语义分割,将分割得到的特征图作为权重叠加到浅层特征图上,相当于一种注意力机制。从可视化的结果来看,浅层特征图上的无关特征得到了有效的抑制。
数据增强
数据增强同样是缓解尺度问题的可行方案,比如YOLOv2算法的随机多尺度训练策略。此外,Kisantal等人以Mask R-CNN作为基准线,针对MS COCO数据集的小目标检测精度较差的问题提出了两种数据增强的手段:(1)采用过采样策略,解决数据集中包含小目标的图片较少的问题;(2)在同一张图片里,对小目标的分割掩膜进行复制粘贴,使锚点策略能匹配到更多的小目标正样本,进而增加小目标在损失函数中的权重。该思路的本质是通过改变训练数据的目标尺度分布,让模型更倾向于去感知小目标。从实验结果来看,大目标的检测精度略有下降,小目标的检测精度有所提升。在目标检测任务中,为了提高检测器的整体性能,通常会采用额外的数据集对模型进行预训练,然后再在正式的数据集上进行微调,亦或是直接让额外数据集参与联合训练。
三、其他目标检测任务
- pedestrian detection(行人检测)

- face detection(人脸检测)

- text detection(文本检测)

- traffic light and sign(交通标志/灯光检测)

- remote sensing target detection(遥感目标检测等特定领域的检测)

高分辨率图像的多尺度目标检测:在对高分辨率图像进行目标检测时,往往并不缺少小目标的细节信息,而是难以实现精度与计算资源的权衡。由于受到内存、检测速度需求等限制,Faster R-CNN、 YOLO等算法都会先将高分辨率图像下采样至某一分辨率,再通入网络进行检测,这就导致了信息的丢失。若采用滑动窗口法实现地毯式检测,整体速度又太慢。 Gao等人提出的用强化学习引导细粒度检测的策略,对于日常设备拍摄的高分辨率图像是有一定效益的。但是,对于细粒度信息更密集的图像是否仍有效(例如无人机航拍),以及能否设计出更简洁的算法,都还有待进一步研究。
四、评估目标探测器的有效性
在行人检测的早期研究中,“每个窗口的漏报率与误报率(FPPW)” 通常用作度量检测性能的评价标准。然而,逐窗测量(FPPW)可能存在缺陷,在某些情况下无法预测的完整图像特性。2009年,加州理工学院(Caltech)建立了行人检测基准,从那时起,评估指标从每窗口(per-window,FPPW)改为每图像的伪阳性(false positive per-image,FPPI)。
最早在VOC2007,对目标检测最常用的评估方法是 “ 平均精度(AP) ”。AP定义为不同召回情况下的平均检测精度,通常以类别特定的方式进行评估。为了比较所有对象类别的性能,通常使用所有对象类别的平均AP(mAP)作为性能的最终度量。为了测量目标定位精度,使用Union上的交集(Intersection over Union,IoU)来检查预测框和地面真实框之间的IoU是否大于预定义的阈值,比如0.5。如果是,则将该对象标识为 “ 成功检测到 ”,否则将标识为 “ 未检测到 ”。因此,基于mAP的0.5 -IoU多年来已成为用于目标检测问题的实际度量。
2014年以后,由于MS-COCO数据集的普及,研究人员开始更加关注边界框位置的准确性。MS-COCO AP没有使用固定的IoU阈值,而是在多个IoU阈值上取平均值,阈值介于0.5(粗定位)和0.95(完美定 )之间。这种度量的变化鼓励了更精确的对象定位,并且对于一些实际应用可能非常重要 ( 例如,假设有一个机器人手臂试图抓住扳手 )。
近年来,对开放图像数据集的评价有了进一步的发展,如考虑了组框(group-of boxes)和非穷举的图像级类别层次结构。一些研究者也提出了一些替代指标,如 “ 定位回忆精度 ”。尽管最近发生了一些变化,基于VOC/COCO的mAP仍然是最常用的目标检测评估指标。